AMD Releases Instinct MI210 Accelerator: CDNA 2 On a PCIe Card

With both GDC and GTC going on this week, this is a big time for GPUs of all sorts. And today, AMD wants to get in on the game as well, with the release of the PCIe version of their MI200 accelerator family, the MI210.
First unveiled alongside the MI250 and MI250X back in November, when AMD initially launched the Instinct MI200 family, the MI210 is the third and final member of AMD's latest generation of GPU-based accelerators. Bringing the CDNA 2 architecture into a PCIe card, the MI210 is being aimed at customers who are after the MI200 family's HPC and machine learning performance, but need it in a standardized form factor for mainstream servers. Overall, the MI200 is being launched widely today as part of AMD moving the entire MI200 product stack to general availability for OEM customers.
| AMD Instinct Accelerators | ||||
| MI250 | MI210 | MI100 | MI50 | |
| Compute Units | 2 x 104 | 104 | 120 | 60 |
| Matrix Cores | 2 x 416 | 416 | 480 | N/A |
| Boost Clock | 1700MHz | 1700MHz | 1502MHz | 1725MHz |
| FP64 Vector | 45.3 TFLOPS | 22.6 TFLOPS | 11.5 TFLOPS | 6.6 TFLOPS |
| FP32 Vector | 45.3 TFLOPS | 22.6 TFLOPS | 23.1 TFLOPS | 13.3 TFLOPS |
| FP64 Matrix | 90.5 TFLOPS | 45.3 TFLOPS | 11.5 TFLOPS | 6.6 TFLOPS |
| FP32 Matrix | 90.5 TFLOPS | 45.3 TFLOPS | 46.1 TFLOPS | 13.3 TFLOPS |
| FP16 Matrix | 362 TFLOPS | 181 TFLOPS | 184.6 TFLOPS | 26.5 TFLOPS |
| INT8 Matrix | 362.1 TOPS | 181 TOPS | 184.6 TOPS | N/A |
| Memory Clock | 3.2 Gbps HBM2E | 3.2 Gbps HBM2E | 2.4 Gbps HBM2 | 2.0 Gbps GDDR6 |
| Memory Bus Width | 8192-bit | 4096-bit | 4096-bit | 4096-bit |
| Memory Bandwidth | 3.2TBps | 1.6TBps | 1.23TBps | 1.02TBps |
| VRAM | 128GB | 64GB | 32GB | 16GB |
| ECC | Yes (Full) | Yes (Full) | Yes (Full) | Yes (Full) |
| Infinity Fabric Links | 6 | 3 | 3 | N/A |
| CPU Coherency | No | N/A | N/A | N/A |
| TDP | 560W | 300W | 300W | 300W |
| Manufacturing Process | TSMC N6 | TSMC N6 | TSMC 7nm | TSMC 7nm |
| Transistor Count | 2 x 29.1B | 29.1B | 25.6B | 13.2B |
| Architecture | CDNA 2 | CDNA 2 | CDNA (1) | Vega |
| GPU | 2 x CDNA 2 GCD "Aldebaran" | CDNA 2 GCD "Aldebaran" | CDNA 1 "Arcturus" | Vega 20 |
| Form Factor | OAM | PCIe (4.0) | PCIe (4.0) | PCIe (4.0) |
| Launch Date | 11/2021 | 03/2022 | 11/2020 | 11/2018 |
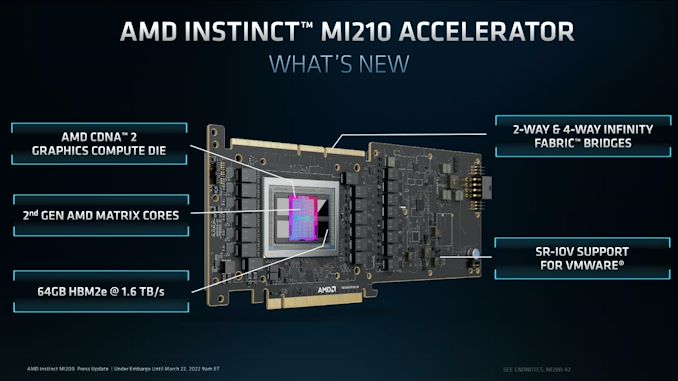
Starting with a look at the top-line specifications, the MI210 is an interesting variant to the existing MI250 accelerators. Whereas those two parts were based on a pair of Aldebaran (CDNA 2) dies in an MCM configuration on a single package, for MI210 AMD is paring everything back to a single die and related hardware. With MI250(X) requiring 560W in the OAM form factor, AMD essentially needed to halve the hardware anyhow to get things down to 300W for a PCIe card. So they've done so by ditching the second on-package die.
The net result is that the MI210 is essentially half of an MI250, both in regards to physical hardware and expected performance. The CNDA 2 Graphics Compute Die features the same 104 enabled CUs as on MI250, with the chip running at the same peak clockspeed of 1.7GHz. So workload scalability aside, the performance of the MI210 is for all practical purposes half of a MI250.
That halving goes for memory, as well. As MI250 paired 64GB of HBM2e memory with each GCD - for a total of 128GB of memory - MI210 brings that down to 64GB for the single GCD. AMD is using the same 3.2GHz HBM2e memory here, so the overall memory bandwidth for the chip is 1.6 TB/second.
In regards to performance, the use of a single Aldebaran die does make for some odd comparisons to AMD's previous-generation PCIe card, the Radeon Instinct MI100. While clocked higher, the slightly reduced number of CUs relative to the MI100 means that for some workloads, the old accelerator is, at least on paper, a bit faster. In practice, MI210 has more memory and more memory bandwidth, so it should still have the performance edge the real world, but it's going to be close. In workloads that can't take advantage of CDNA 2's architectural improvements, MI210 is not going to be a step up from MI100.
All of this underscores the overall similarity between the CDNA (1) and CDNA 2 architectures, and how developers need to make use of CDNA 2's new features to get the most out of the hardware. Where CDNA 2 shines in comparison to CDNA (1) is with FP64 vector workloads, FP64 matrix workloads, and packed FP32 vector workloads. All three use cases benefit from AMD doubling the width of their ALUs to a full 64-bits wide, allowing FP64 operations to be processed at full speed. Meanwhile, when FP32 operations are packed together to completely fill the wider ALU, then they too can benefit from the new ALUs.
But, as we noted in our initial MI250 discussion, like all packed instruction formats, packed FP32 isn't free. Developers and libraries need to be coded to take advantage of it; packed operands need to be adjacent and aligned to even registers. For software being written specifically for the architecture (e.g. Frontier), this is easily enough done, but more portable software will need updated to take this into account. And it's for that reason that AMD wisely still advertises its FP32 vector performance at full rate (22.6 TFLOPS), rather than assuming the use of packed instructions.
The launch of the MI210 also marks the introduction of AMD's improved matrix cores into a PCIe card. For CDNA 2, they've been expanded to allow full-speed FP64 matrix operation, bringing them up to the same 256 FLOPS rate as FP32 matrix operations, a 4x improvement over the old 64 FLOPS/clock/CU rate.
| AMD GPU Throughput Rates (FLOPS/clock/CU) | |||
| CDNA 2 | CDNA (1) | Vega 20 | |
| FP64 Vector | 128 | 64 | 64 |
| FP32 Vector | 128 | 128 | 128 |
| Packed FP32 Vector | 256 | N/A | N/A |
| FP64 Matrix | 256 | 64 | 64 |
| FP32 Matrix | 256 | 256 | 128 |
| FP16 Matrix | 1024 | 1024 | 256 |
| BF16 Matrix | 1024 | 512 | N/A |
| INT8 Matrix | 1024 | 1024 | N/A |
Moving on, the PCIe format MI210 also gets a trio of Infinity Fabric 3.0 links along the top of the card, just like the MI100. This allows an MI210 card to be linked up with one or three other cards, forming a 2 or 4-way cluster of cards. Meanwhile, backhaul to the CPU or any other PCIe devices is provided via a PCIe 4.0 x16 connection, which is being powered by one of the flexible IF links from the GCD.
As previously mentioned, the TDP for the MI210 is set at 300W, the same level as the MI100 and MI50 before it - and essentially the limit for a PCIe server card. Like most server accelerators, this is fully passive dual slot card design, relying on significant airflow from the server chassis to keep things cool. The GPU itself is powered by a combination of the PCIe slot and an 8 pin, EPS12V connector at the rear of the card.

Otherwise, despite the change in form factors, AMD is going after much the same market with MI210 as they have MI250(X). Which is to say HPC users who specifically need a fast FP64 accelerator. Thanks to its heritage as a chip designed first and foremost for supercomputers (i.e. Frontier), the MI200 family currently stands alone in its FP64 vector and FP64 matrix performance, as rival GPUs have focused instead on improving performance at the lower precisions used in most industry/non-scientific workloads. Though even at lower precisions, the MI200 family is nothing to sneeze at with tis 1024 FLOPS-per-CU rate on FP16 and BF16 matrix operations.

Wrapping things up, MI210 is slated to become available today from AMD's usual server partners, including ASUS, Dell, Supermicro, HPE, and Lenovo. Those vendors are now also offering servers based on AMD's MI250(X) accelerators, so AMD's more mainstream customers will have access to systems based on AMD's full lineup of MI200 accelerators.
Gallery: AMD Instinct MI210 Press Deck




