Thinking about Big Data — Part Two
 In Part One of this series of columns we learned about data and how computers can be used for finding meaning in large data sets. We even saw a hint of what we might call Big Data at Amazon.com in the mid-1990s, as that company stretched technology to observe and record in real time everything its tens of thousands of simultaneous users were doing. Pretty impressive, but not really Big Data, more like Bigish Data. The real Big Data of that era was already being gathered by outfits like the U.S. National Security Agency (NSA) and the UK Government Communications Headquarters (GCHQ) - spy operations that were recording digital communications even though they had no easy way to decode and find meaning in it. Government tape libraries were being filled to overflowing with meaningless gibberish.
In Part One of this series of columns we learned about data and how computers can be used for finding meaning in large data sets. We even saw a hint of what we might call Big Data at Amazon.com in the mid-1990s, as that company stretched technology to observe and record in real time everything its tens of thousands of simultaneous users were doing. Pretty impressive, but not really Big Data, more like Bigish Data. The real Big Data of that era was already being gathered by outfits like the U.S. National Security Agency (NSA) and the UK Government Communications Headquarters (GCHQ) - spy operations that were recording digital communications even though they had no easy way to decode and find meaning in it. Government tape libraries were being filled to overflowing with meaningless gibberish.
What Amazon.com had done was easier. The customer experience at Amazon, even if it involved tens of thousands of products and millions of customers, could be easily defined. There are only so many things a customer can do in a store, whether it is real or virtual. They can see what's available, ask for more information, compare products, prepare to buy, buy, or walk away. That was all within the capability of relational databases where the relations between all those activities could be pre-defined. It had to be predefined, which is the problem with relational databases - they aren't easily extended.
Needing to know your database structure upfront is like having to make a list of all of your unborn child's potential friends" forever. This list must even include future friends as yet unborn, because once the child's friends list is built, adding to it requires major surgery.
Finding knowledge - meaning - in data required more flexible technology.
The two great technical challenges of the 1990s Internet were dealing with unstructured data, which is to say the data flowing around us every day that isn't typically even thought of as being within a database of any kind, and processing those data very cheaply because there was so much of it and the yield of knowledge was likely to be very low.
If you are going to listen to a million telephone conversations hoping to hear one instance of the words al-Qaeda that means either a huge computing budget or a new very cheap way to process all that data.
The commercial Internet was facing two very similar challenges, which were finding anything at all on the World Wide Web and paying through advertising for finding it.
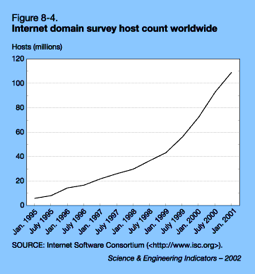 The search challenge.By 1998 the total number of web sites had reached 30 million (it is more than two billion today). That was 30 million places, each containing many web pages. Pbs.org, for example, is a single site containing more than 30,000 pages. Each page then contains hundreds or thousands of words, images, and data points. Finding information on the web required indexing the entire Internet. Now that's Big Data!
The search challenge.By 1998 the total number of web sites had reached 30 million (it is more than two billion today). That was 30 million places, each containing many web pages. Pbs.org, for example, is a single site containing more than 30,000 pages. Each page then contains hundreds or thousands of words, images, and data points. Finding information on the web required indexing the entire Internet. Now that's Big Data!
To index the web you first need to read it - all of it -30 million hosts in 1998 or two billion today. This was done through the use of what are called spiders- computer programs that search the Internet methodically looking for new web pages, reading them, then copying and dragging back the content of those pages to be included in the index. All search engines use spiders and spiders have to run continuously, updating the index to keep it current as web pages come and go or change. Most search engines keep not only an index of the web today, they tend to keep all old versions of the index, too, so by searching earlier versions it is possible to look back in time.
Indexing means recording all the metadata - the data about the data -words, images, links and other types of data like video or audio embedded in a page. Now multiply that by zillions. We do it because an index occupies approximately one percent of the storage of the servers it represents - 300,000 pages worth of data out of 30 million circa 1998. But indexing isn't finding information, just recording the metadata. Finding usable information from the index is even harder.
There were dozens of search engines in the first decade of the Internet but four were the most important and each took a different technical approach to finding meaning from all those pages. Alta-Vista was the first real search engine. It came from the Palo Alto lab of Digital Equipment Corporation which was really the Computer Science Lab of XEROX PARC moved almost in its entirety two miles east by Bob Taylor, who built both places and hired many of the same people.
Alta-Vista used a linguistic tool for searching its web index. Alta-Vista indexed all the words in a document, say a web page. You could search on "finding gold doubloons" and Alta Vista would search its index for documents that contained the words "finding," "gold," and "doubloons." and presented a list of pages ordered by the number of times each search term appeared in the document.
But even back then there was a lot of crap on the Internet which means Alta-Vista indexed a lot of crap and had no way of telling crap from non-crap. They were, after all, only words. Pointedly bad documents often rose to the top of search results and the system was easy to game by inserting hidden words to tilt the meter. Alta-Vista couldn't tell the difference between real words and bogus hidden words.
 Where Alta-Vista leveraged DEC's big computers (that was the major point, since DEC was primarily a builder of computer hardware), Yahoo leveraged people. The company actually hired workers to spend all day reading web pages, indexing them by hand (and not very thoroughly) then making a note of the ones most interesting on each topic. If you had a thousand human indexers and each could index 100 pages per day then Yahoo could index 100,000 pages per day or about 30 million pages per year - the entire Internet universe circa 1998. It worked a charm on the World Wide Web until the web got too big for Yahoo to keep up. Yahoo's early human-powered system did not scale.
Where Alta-Vista leveraged DEC's big computers (that was the major point, since DEC was primarily a builder of computer hardware), Yahoo leveraged people. The company actually hired workers to spend all day reading web pages, indexing them by hand (and not very thoroughly) then making a note of the ones most interesting on each topic. If you had a thousand human indexers and each could index 100 pages per day then Yahoo could index 100,000 pages per day or about 30 million pages per year - the entire Internet universe circa 1998. It worked a charm on the World Wide Web until the web got too big for Yahoo to keep up. Yahoo's early human-powered system did not scale.
So along came Excite, which was based on a linguistic trick, which was to find a way to give searchers not more of what they said they wanted but more of what they actually needed but might be unable to articulate. Again, this challenge was posed in an environment of computational scarcity (this is key).
Excite used the same index as Alta-Vista, but instead of just counting the number of times the word "gold" or "doubloons" appeared, the six Excite boys took a vector geometric approach, each query being defined as a vector composed of search terms and their frequencies. A vector is just an arrow in space with a point of origin, a direction, and a length. In the Excite universe the point of origin was total zeroness on the chosen search terms (zero "finding," zero "gold," and zero "doubloons"). An actual search vector would begin at zero-zero-zero on those three terms then extend, say, two units of "finding" because that's how many times the word "finding" appeared in the target document, thirteen units of "gold" and maybe five units of "doubloons." This was a new way to index the index and a better way to characterize the underlying data because it would occasionally lead to search results that didn't use any of the actual search terms - something Alta-Vista could never do.
The Excite web index was not just a list of words and their frequencies but a multi-dimensional vector space that considered searches as directions. Each search was a single quill in a hedgehog of data and the genius of Excite (Graham Spencer's genius) was to grab not just that quill, but all the quills right around it, too. By grabbing not just the document that matched absolutely the query terms (as Alta-Vista did) but also all the terms near it in the multidimensional vector space, Excite was a more useful search tool. It worked on an index, it had the refinement of vector math and - here's the important part - it required almost no calculation to produce a result since that calculation was already done as part of the indexing. Excite produced better results faster using primitive hardware.
But Google was even better.
 Google brought two refinements to search - PageRank and cheap hardware.
Google brought two refinements to search - PageRank and cheap hardware.
Excite's clever vector approach produced search results that were most like what searchers intended to find, but even Excite search results were often useless. So Larry Page of Google came up with a way to measure usefulness, which was by finding a proxy for accuracy. Google started with search results using linguistic methods like Alta-Vista, but then added an extra filter in PageRank (named for Larry Page, get it?),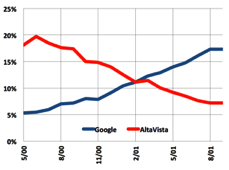 which looked at the top-tier results and ordered them by how many other pages they were linked to. The idea being that the more page authors who bothered to link to a given page, the more useful (or at least interesting if even in a bad way) the page would be. And they were right. The other approaches all fell into decline and Google quickly dominated on the basis of their PageRank patent.
which looked at the top-tier results and ordered them by how many other pages they were linked to. The idea being that the more page authors who bothered to link to a given page, the more useful (or at least interesting if even in a bad way) the page would be. And they were right. The other approaches all fell into decline and Google quickly dominated on the basis of their PageRank patent.
 But there was another thing that Google did differently from the other guys. Alta-Vista came from Digital Equipment and ran on huge clusters of DEC's VAX minicomputers. Excite ran on equally big UNIX hardware from Sun Microsystems. Google, however, ran using free Open Source software on computers that were little more than personal computers. They were, in fact, less than PCs, because Google's homemade computers had no cases, no power supplies (they ran, literally, on car batteries charged by automotive battery chargers), the first ones were bolted to walls while later ones were shoved into racks like so many pans of brownies, fresh from a commercial oven.
But there was another thing that Google did differently from the other guys. Alta-Vista came from Digital Equipment and ran on huge clusters of DEC's VAX minicomputers. Excite ran on equally big UNIX hardware from Sun Microsystems. Google, however, ran using free Open Source software on computers that were little more than personal computers. They were, in fact, less than PCs, because Google's homemade computers had no cases, no power supplies (they ran, literally, on car batteries charged by automotive battery chargers), the first ones were bolted to walls while later ones were shoved into racks like so many pans of brownies, fresh from a commercial oven.
Amazon created the business case for Big Data and developed a clunky way to do it on pre-Big Data hardware and software. The search companies broadly expanded the size of practical data sets, while mastering indexing. But true Big Data couldn't run on an index, it had to run on the actual data, itself, which meant either really big and expensive computers like they used at Amazon, or a way to use cheap PCs to look like a huge computer at Google.
The Dot-Com Bubble. Let's consider for a moment the euphoria and zaniness of the Internet as an industry in the late 1990s during what came to be called the dot-com bubble. It was clear to everyone from Bill Gates down that the Internet was the future of personal computing and possibly the future of business. So venture capitalists invested billions of dollars in Internet startup companies with little regard to how those companies would actually make money.
The Internet was seen as a huge land grab where it was important to make companies as big as they could be as fast as they could be to grab and maintain market share whether the companies were profitable or not. For the first time companies were going public without having made a dime of profit in their entire histories. But that was seen as okay - profits would eventually come.
 The result of all this irrational exuberance was a renaissance of ideas, most of which couldn't possibly work at the time. Broadcast.com, for example, purported to send TV over dial-up Internet connections to huge audiences. It didn't actually work, yet Yahoo still bought Broadcast.com for $5.7 billion in 1999 making Mark Cuban the billionaire he is today.
The result of all this irrational exuberance was a renaissance of ideas, most of which couldn't possibly work at the time. Broadcast.com, for example, purported to send TV over dial-up Internet connections to huge audiences. It didn't actually work, yet Yahoo still bought Broadcast.com for $5.7 billion in 1999 making Mark Cuban the billionaire he is today.
We tend to think of Silicon Valley being built on Moore's Law making computers continually cheaper and more powerful, but the dot-com era only pretended to be built on Moore's Law. It was actually built on hype.
Hype and Moore's Law.In order for many of these 1990s Internet schemes to succeed, the cost of computing had to be brought down to a level that was cheaper even than could be made possible at that time by Moore's Law. This was because the default business model of most dot-com startups was to make their money from advertising and there was a strict limit on how much advertisers were willing to pay.
For awhile it didn't matter because venture capitalists and then Wall Street investors were willing to make up the difference, but it eventually became obvious that an Alta-Vista with its huge data centers couldn't make a profit from Internet search alone. Nor could Excite or any of the other early search outfits.
The dot-com meltdown of 2001 happened because the startups ran out of gullible investors to fund their Super Bowl commercials. When the last dollar of the last yokel had been spent on the last Herman Miller office chair, the VCs had, for the most part, already sold their holdings and were gone. Thousands of companies folded, some of them overnight. And the ones that did survive - including Amazon and Google and a few others - did so because they'd figured out how to actually make money on the Internet.
Amazon.com was different because Jeff Bezos' business was e-commerce. Amazon was a new kind of store meant to replace bricks and mortar with electrons. For Amazon the savings in real estate and salaries actually made sense since the company's profit could be measured in dollars per transaction. But for Internet search - the first use of Big Data and the real enabler of the Internet - the advertising market would pay less than a penny per transaction. The only way to make that work was to find a way to break Moore's Law and drive the cost of computing even lower while at the same time trying to find a better way to link search and advertising, thus increasing sales. Google did both.
Time for Big Data Miracle #2, which entirely explains why Google is today worth $479 billion and most of those other search companies are long dead.

GFS, Map Reduce and BigTable.Because Page and Brin were the first to realize that making their own super-cheap servers was the key to survival as a company, Google had to build a new data processing infrastructure to solve the problem of how to make thousands of cheap PCs look and operate like a single supercomputer.
Where other companies of the era seemed content to lose money hoping that Moore's Law would eventually catch up and make them profitable, Google found a way to make search profitable in late 1990s dollars. This involved inventing new hardware, software, and advertisingtechnologies. Google's work in these areas led directly to the world of Big Data we see emerging today.
Let's first get an idea of the scale involved at Google today. When you do a Google search you are first interacting first with three million web servers in hundreds of data centers all over the world. All those servers do is send page images to your computer screen - an average of 12 billion pages per day. The web index is held in another two million servers and a further three million servers contain the actual documents stored in the system. That's eight million servers so far and that doesn't include YouTube.
The three key components in Google's el cheapo architecture are the Google File System, or GFS, which lets all those millions of servers look at what they think is the same memory. It isn't the same, of course - there are subdivided copies of the memory called chunksall over the place - but the issue here is coherency.If you change a file it has to be changed for all servers at the same time, even those thousands of miles apart.
One huge issue for Google, then, is the speed of light.
MapReduce distributes a big problem across hundreds or thousands of servers. It maps the problem out to the servers then reducestheir many answers back into one.
BigTable is Google's database that holds all the data. It isn't relational because relational doesn't work at this scale. It's an old-fashioned flat database that, like GFS, has to be coherent.
Before these technologies were developed computers worked like people, on one thing at a time using limited amounts of information. Finding a way for thousands of computers to work together on huge amounts of data was a profound breakthrough.
But it still wasn't enough for Google to reach its profit targets.
 Big Brother started as an ad man.In Google's attempt to match the profit margins of Amazon.com, only so much could be accomplished by just making computing cheaper. The rest of that gap from a penny to a dollar per transaction had to be covered by finding a way to sell Internet ads for more money. Google did this by turning its data center tools against its very users, effectively indexing us in just the way the company already indexed the web.
Big Brother started as an ad man.In Google's attempt to match the profit margins of Amazon.com, only so much could be accomplished by just making computing cheaper. The rest of that gap from a penny to a dollar per transaction had to be covered by finding a way to sell Internet ads for more money. Google did this by turning its data center tools against its very users, effectively indexing us in just the way the company already indexed the web.
By studying our behavior and anticipating our needs as consumers, Google could serve us ads we were 10 or 100 times more likely to click on, increasing Google's pay-per-click revenue by 10 or 100 times, too.
Now we're finally talking Big Data.
Whether Google technology looked inward or outward it worked the same. And unlike, say, the SABRE system, these were general purpose tools - they can be used for almost any kind of problem on almost any kind of data.
GFS and MapReduce meant that - for the first time ever - there were no limits to database size or search scalability. All that was required was more commodity hardware eventually reaching millions of cheap servers sharing the task. Google is constantly adding servers to its network. But it goes beyond that, because unless Google shuts down an entire data center, it never replaces servers as they fail. That's too hard. The servers are just left, dead in their racks, while MapReduce computes around them.
Google published a paper on GFS in 2003 and on MapReduce in 2004. One of the wonders of this business is that Google didn't even try to keep secrets, though it is likely others would have come up with similar answers eventually.
Yahoo, Facebook and others quickly reverse-engineered an Open Source variant of Map Reduce they called Hadoop (named after a stuffed toy elephant - elephants never forget), and what followed was what today we call Cloud Computing, which is simply offering as a commercial service the ability to map your problem across a dozen or a hundred rented sometimes for only seconds, then reduce the many answers to some coherent conclusion.
Big Data made Cloud Computing necessary. Today it is hard to differentiate between them.
Not only Big Data but also Social Networking were enabled by MapReduce and Hadoop as for the first time it became cost effective to give a billion Facebook users their own dynamic web pages for free and make a profit solely from ads.
Even Amazon switched to Hadoop and there are today virtually no limits to how big their network can grow.
Amazon, Facebook, Google, and the NSA couldn't function today without MapReduce or Hadoop, which by the way destroyed forever the need to index at all. Modern searches are done not against an index but against the raw data as it changes minute-by-minute. Or more properly perhaps the index is updated minute-by-minute. It may not matter which.
Thanks to these tools, cloud computing services are available from Amazon and others. Armed only with a credit card clever programmers can in a few moments harness the power of one or a thousand or ten thousand computers and apply them to some task. That's why Internet startups no longer even buy servers. If you want, for a short time, to have more computing power than Russia, you can put it on your plastic.
If Russia wants to have more computing power than Russia, they can put it on their plastic, too.
The great unanswered question here is why did Google share its secrets with competitors by publishing those research papers? Was it foolish arrogance on the part of the Google founders who at that time still listed themselves as being on leave from their Stanford PhD program? Not at all. Google shared its secret to build the industry overall. It needed competitors to look like there was no search monopoly. But even more importantly, by letting a thousand flowers bloom Google encouraged the Internet industry to be that much larger making Google's 30 or 40 percent of all revenue that much bigger, too.
By sharing its secrets Google got a smaller piece of a very much bigger pie.
That's, in a nutshell, the genesis of Big Data. Google is tracking your every mouse click and that of a billion or more other people. So is Facebook. So is Amazon when you are on their site or when you are on any site using Amazon Web Services, which probably encompasses a third of all Internet computing anywhere.
 Think for a moment what this means for society. Where businesses in the past used market research to guess what consumers wanted and how to sell it to them, they can now use Big Data to know what you want and how to sell it to you, which is why I kept seeing online ads for expensive espresso makers. And when I finally bought one, those espresso machine ads almost instantly stopped because the system knew. It moved on to trying to sell me coffee beans and, for some reason, adult diapers.
Think for a moment what this means for society. Where businesses in the past used market research to guess what consumers wanted and how to sell it to them, they can now use Big Data to know what you want and how to sell it to you, which is why I kept seeing online ads for expensive espresso makers. And when I finally bought one, those espresso machine ads almost instantly stopped because the system knew. It moved on to trying to sell me coffee beans and, for some reason, adult diapers.
Google will eventually have a server for every Internet user. They and other companies will gather more types of data from us and better predict our behavior. Where this is going depends on who is using that data. It can make us perfect consumers or busted terrorists (or even better terrorists - that's another argument).
There is no problem too big to attempt.
And for the first time, thanks to Google, the NSA and GCHQ finally have the tools to look through that stored intelligence data to find all the bad guys. Or, I suppose, enslave us forever.
(Want more? Here's Part Three.)

Digital Branding
Web DesignMarketing