Thinking about Big Data — Part Three (the final and somewhat scary part)
 In part one we learned about data and how it can be used to find knowledge or meaning. Part two explained the term Big Data and showed how it became an industry mainly in response to economic forces. This is part three, where it all has to fit together and make sense - rueful, sometimes ironic, and occasionally frightening sense. You see our technological, business, and even social futures are being redefined right now by Big Data in ways we are only now coming to understand and may no longer be able to control.
In part one we learned about data and how it can be used to find knowledge or meaning. Part two explained the term Big Data and showed how it became an industry mainly in response to economic forces. This is part three, where it all has to fit together and make sense - rueful, sometimes ironic, and occasionally frightening sense. You see our technological, business, and even social futures are being redefined right now by Big Data in ways we are only now coming to understand and may no longer be able to control.
Whether the analysis is done by a supercomputer or using a hand-written table compiled in 1665 from the Bills of Mortality, some aspects of Big Data have been with us far longer than we realize.
The dark side of Big Data. Historically the role of Big Data hasn't always been so squeaky clean. The idea of crunching numbers to come up with a quantitative rationalization for something we wanted to do anyway has been with us almost as long as we've had money to lose.
 Remember the corporate raiders of the 1980s and their new-fangled Big Data weapon - the PC spreadsheet? The spreadsheet, a rudimentary database, made it possible for a 27-year-old MBA with a PC and three pieces of questionable data to talk his bosses into looting the company pension plan and doing a leveraged buy-out. Without personal computers and spreadsheets there would have been no Michael Milkens or Ivan Boeskys. That was all just a 1980's-era version of Big Data. Pedants will say that isn't Big Data, but it served the same cultural role as what we call Big Data today. It was Big Data for that time.
Remember the corporate raiders of the 1980s and their new-fangled Big Data weapon - the PC spreadsheet? The spreadsheet, a rudimentary database, made it possible for a 27-year-old MBA with a PC and three pieces of questionable data to talk his bosses into looting the company pension plan and doing a leveraged buy-out. Without personal computers and spreadsheets there would have been no Michael Milkens or Ivan Boeskys. That was all just a 1980's-era version of Big Data. Pedants will say that isn't Big Data, but it served the same cultural role as what we call Big Data today. It was Big Data for that time.
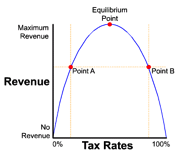 Remember Reaganomics? Economist Arthur Laffer claimed to prove that you could raise government revenue by lowering taxes on the rich. Some people still believe this, but they are wrong.
Remember Reaganomics? Economist Arthur Laffer claimed to prove that you could raise government revenue by lowering taxes on the rich. Some people still believe this, but they are wrong.
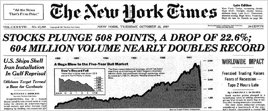 Program trading - buying and selling stocks automatically following the orders of a computer algorithm - caused Wall Street to crash in 1987 because firms embraced it but didn't really know how to use it. Each computer failed to realize that other computers were acting at the same time, possibly in response to the same rules, turning what was supposed to be an orderly retreat into a selling panic.
Program trading - buying and selling stocks automatically following the orders of a computer algorithm - caused Wall Street to crash in 1987 because firms embraced it but didn't really know how to use it. Each computer failed to realize that other computers were acting at the same time, possibly in response to the same rules, turning what was supposed to be an orderly retreat into a selling panic.
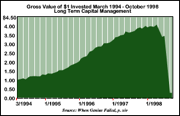 Long Term Capital Management took derivative securities to a place in the 1990s they had never been before only to fail spectacularly because nobody really understood derivatives. If the government hadn't quickly intervened, Wall Street would have crashed again.
Long Term Capital Management took derivative securities to a place in the 1990s they had never been before only to fail spectacularly because nobody really understood derivatives. If the government hadn't quickly intervened, Wall Street would have crashed again.
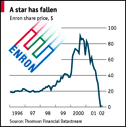 Enron in the early 2000's used giant computers to game energy markets, or so they thought until the company imploded. Enron's story, remember, was that their big computers made them smarter, while the truth was their big computers were used to mask cheating and market manipulation. "Pay no attention to that man behind the curtain!"
Enron in the early 2000's used giant computers to game energy markets, or so they thought until the company imploded. Enron's story, remember, was that their big computers made them smarter, while the truth was their big computers were used to mask cheating and market manipulation. "Pay no attention to that man behind the curtain!"
The global banking crisis of 2007 was caused in part by using big computers to create supposedly perfect financial products that the market ultimately could not absorb. But wasn't that all caused by deregulation? Deregulation can encourage financiers to be reckless, but more importantly Moore's Law had brought down the cost of computing to the point where it seemed plausible to mount a technical assault on regulation. Technology created temptation to try for the big score.
These were all just variations on the darker side of Big Data. Big Data schemes become so big so fast and then they crash. These data-driven frenzies tend not to be based on reality but on the fantasy that you can somehow trump reality.
And at their heart these failures tend to be based on lies or become undermined by lies. How do you make a AAA-rated Collateralized Mortgage Obligation entirely from junk-rated mortgages? You lie.
It's a huge problem of basing conclusions on either the wrong method or the wrong data. Some experts would argue this can be cured simply through the use of Bigger Data. And maybe it can be, but our track record of doing so hasn't been a good one.
There is an irony here that when we tend to believe the wrong Big Data it usually concerns money or some other manifestation of power, but we have an equal tendency to not believe the right Big Data when it involves politics or religion. So Big Scientific Data often struggles to gain acceptance against unbelievers - those who deny climate change, for example, or endorse the teaching of creationism.
 Big Data and insurance. Big Data has already changed our world in many ways. Take health insurance, for example. There was a time when actuaries at insurance companies studied morbidity and mortality statistics in order to set insurance rates. This involved metadata - data about data - because for the most part the actuaries weren't able to drill down far enough to reach past broad groups of policyholders to individuals. In that system, insurance company profitability increased linearly with scale so health insurance companies wanted as many policyholders as possible, making a small profit on most of them.
Big Data and insurance. Big Data has already changed our world in many ways. Take health insurance, for example. There was a time when actuaries at insurance companies studied morbidity and mortality statistics in order to set insurance rates. This involved metadata - data about data - because for the most part the actuaries weren't able to drill down far enough to reach past broad groups of policyholders to individuals. In that system, insurance company profitability increased linearly with scale so health insurance companies wanted as many policyholders as possible, making a small profit on most of them.
Then in the 1990s something happened: the cost of computing came down to the point where it was cost-effective to calculate likely health outcomes on an individual basis. This moved the health insurance business from being based on setting rates to denying coverage. In the U.S. the health insurance business model switched from covering as many people as possible to covering as few people as possible - selling insurance only to healthy people who didn't need the healthcare system.
Insurance company profits soared but we also had millions of uninsured families as a result.
Given that the broad goal of society is to keep people healthy, this business of selling insurance only to the healthy probably couldn't last. It was just a new kind of economic bubble waiting to burst - hence Obamacare. There's a whole book in this subject alone, but just understand that something had to happen to change the insurance system if the societal goal was to be achieved. Trusting the data crunchers to somehow find an intrinsic way to cover more citizens while continuing to maximize profit margins, that's lunacy.
Big scary Google.The shell games that too often underly Big Data extend throughout our economy to the very people we've come to think of as embodying - even having invented - Big Data. Google, for example, wants us to believe they know what they are doing. I'm not saying what Google has done isn't amazing and important but at the base of it is an impenetrable algorithm they won't explain or defend any more than Bernie Madoff would his investment techniques. Big Scary Google, they have it all figured out.
Maybe, but who can even know?
But they are making all the money!
The truth about advertising. Google bills advertisers but what makes them all that money is the advertisers pay those bills. While this may sound simplistic, often advertisers don't really want to know how well their campaigns are going. If it were ever clear what a ridiculously low yield there was on most advertising, ad agencies would go out of business. And since agencies not only make the ads, they also typically place them for customers, in the ad industry's point of view it is sometimes better not to know.
Among Mad Men the agency power structure is on its head as a result. Senior agency people who earn most of the money are on the creative side, making the ads. Junior people who make almost no money and have virtually zero influence are the ones who place print, broadcast, and even Internet ads. The advertising industry values ad creation above any financial return to clients. That's crazy and to make it work ignorance has to be king.
As a result the Internet is corrupt. The Huffington Post tells its writers to use Search Engine Optimization terms in their stories because that is supposed to increase readership. Does it really? That's not clear, though what research there is says SEO numbers go up, too, if you insert gibberish into your posts, which makes no sense at all.
Ultimately what happens is we give in and accept a lower standard of performance. Will Match.com or eHarmony really help you find a better mate? No. But it's fun to think they can, so what the hell"
What's odd here is we have data cynicism when it concerns real science (climate change, creationism, etc.) but very little cynicism when it comes to business data.
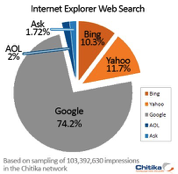 Now here is something really interesting to consider. Google's data - the raw data, not the analysis - is for the most part accessible to other companies, so why doesn't Google have an effective competitor in search? Microsoft's Bing certainly has the same data as Google but they have a sixth the users. It comes down to market perception and Bing is not perceived as a viable alternative to Google even though it clearly is.
Now here is something really interesting to consider. Google's data - the raw data, not the analysis - is for the most part accessible to other companies, so why doesn't Google have an effective competitor in search? Microsoft's Bing certainly has the same data as Google but they have a sixth the users. It comes down to market perception and Bing is not perceived as a viable alternative to Google even though it clearly is.
This is the spin game of Big Data.
Here's another side of this story that hasn't been covered. Apple has a $1 billion data center in North Carolina, built before Steve Jobs died. I spent an afternoon parked by the front gate of that facility and counted one vehicle enter or leave. I went on to calculate the server capacity required if Apple were to store in the facility multiple copies of all known data on Earth and it came to eight percent of the available floor space. This building has the capacity to hold two million servers.  Later I met the salesman who sold to Apple every server in that building - all 20,000 of them, he told me.
Later I met the salesman who sold to Apple every server in that building - all 20,000 of them, he told me.
Twenty thousand servers is plenty for iTunes but only one percent of the building's capacity. What's going on there? It's Big Data BS: by spending $1 billion for a building, Apple looks to Wall Street (and to Apple competitors) like a player in Google's game.
This is not to say that Big Data isn't real when it is real. At Amazon.com and any other huge retailer including Walmart, Big Data is very real because those firms need real data to be successful on thin profit margins. Walmart's success has always been built on Information Technology. In e-commerce, where real things are bought and sold, the customer is the customer.
At Google and Facebook the customer is the product. Google and Facebook sell us.
All the while Moore's Law marches on, making computing ever cheaper and more powerful. As we said in part one, every decade computing power at the same price goes up by a factor of 100 thanks to Moore's Law alone. So the computer transaction required to sell an airline ticket on the SABRE System in 1955 dropped by a factor of a billion today. What was a reasonable $10 ticketing expense in 1955 is today such a tiny fraction of a penny that it isn't worth calculating. In SABRE terms, computing is now effectively free. That changes completely the kind of things we might do with computers.
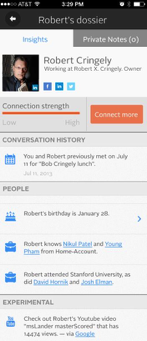 Your personal intelligence agency. Computing has become so inexpensive and personal data has become so pervasive that there are now cloud-based apps that make your smart phone the equivalent of J. Edgar Hoover's FBI or today's NSA - a data mining machine. One of these tools was called Refresh and is pictured here. Refresh has now been absorbed into LinkedIn which is being absorbed into Microsoft but the example is still valid. Punch someone's name into your phone and hundreds of computers - literally hundreds of computers - fan out across social media and the world wide web composing an on-the-fly dossier on the person you are about to meet in business or would like to meet at the end of the bar, not only telling you about this person, their life, work, family, education, but even mapping any intersections between their life and yours, suggesting questions you might ask or topics of conversation you might want to pursue. All of this in under one second. And for free.
Your personal intelligence agency. Computing has become so inexpensive and personal data has become so pervasive that there are now cloud-based apps that make your smart phone the equivalent of J. Edgar Hoover's FBI or today's NSA - a data mining machine. One of these tools was called Refresh and is pictured here. Refresh has now been absorbed into LinkedIn which is being absorbed into Microsoft but the example is still valid. Punch someone's name into your phone and hundreds of computers - literally hundreds of computers - fan out across social media and the world wide web composing an on-the-fly dossier on the person you are about to meet in business or would like to meet at the end of the bar, not only telling you about this person, their life, work, family, education, but even mapping any intersections between their life and yours, suggesting questions you might ask or topics of conversation you might want to pursue. All of this in under one second. And for free.
Okay an electronic crib sheet is hardly the apex of human computational development, but it shows how far we have come and suggests how much farther still we can go as computing gets even cheaper. And computing is about to get a lot cheaper since Moore's Law isn't slowing down, it's actually getting faster.
The failure of Artificial Intelligence.Back in the 1980s there was a popular field called Artificial Intelligence, the major idea of which was to figure out how experts do what they do, reduce those tasks to a set of rules, then program computers with those rules, effectively replacing the experts. The goal was to teach computers to diagnose disease, translate languages, to even figure out what we wanted but didn't know ourselves.
It didn't work.
Artificial Intelligence or AI, as it was called, absorbed hundreds of millions of Silicon Valley VC dollars before being declared a failure. Though it wasn't clear at the time, the problem with AI was we just didn't have enough computer processing power at the right price to accomplish those ambitious goals. But thanks to Map Reduce and the cloud we have more than enough computing power to do AI today.
The human speed bump.It's ironic that a key idea behind AI was to give language to computers yet much of Google's success has been from effectively taking language away from computers - human language that is. The XML and SQL data standards that underly almost all web content are not used at Google where they realized that human-readable data structures made no sense when it was computers - and not humans - that would be doing the communicating. It's through the elimination of human readability, then, that much progress has been made in machine learning. THIS IS REALLY IMPORTANT, PLEASE READ IT AGAIN.
You see in today's version of Artificial Intelligence we don't need to teach our computers to perform human tasks: they teach themselves.
Google Translate, for example, can be used online for free by anyone to translate text back and forth between more than 70 languages. This statistical translator uses billions of word sequences mapped in two or more languages. This in English means that in French. There are no parts of speech, no subjects or verbs, no grammar at all. The system just figures it out. And that means there's no need for theory. It clearly works, but we can't say exactly how it works because the whole process is data driven. Over time Google Translate will get better and better, translating based on what are called correlative algorithms - rules that never leave the machine and are too complex for humans to even understand.
Google Brain. At Google they have something called Google Vision that not long ago had 16000 microprocessors equivalent to about a tenth of our brain's visual cortex. It specializes in computer vision and was trained the same way as Google Translate, through massive numbers of examples - in this case still images (BILLIONS of still images) taken from YouTube videos. Google Vision looked at images for 72 straight hours and essentially taught itself to see twice as well as any other computer on Earth. Give it an image and it will find another one like it. Tell it that the image is a cat and it will be able to recognize cats. Remember this took three days. How long does it take a newborn baby to recognize cats?
 This is exactly how IBM's Watson computer came to win at Jeopardy, just by crunching old episode questions: there was no underlying theory.
This is exactly how IBM's Watson computer came to win at Jeopardy, just by crunching old episode questions: there was no underlying theory.
Let's take this another step or two. There have been data-driven studies of Magnetic Resonance Images (MRIs) taken of the active brains of convicted felons. This is not in any way different from the Google Vision example except we're solving for something different - recidivism, the likelihood that a criminal will break the law again and return to prison after release. Again without any underlying theory Google Vision seems to be able to differentiate between the brain MRIs of felons likely to repeat and those unlikely to repeat. Google's success rate for predicting recidivism purely on the basis of one brain scan is 90+ percent. Should MRIs become a tool, then, for deciding which prisoners to release on parole? This sounds a bit like that Tom Cruise movie Minority Report. It has a huge imputed cost savings to society, but also carries the scary aspect of there being no underlying theory: it works because it works.
 Google scientists then looked at brain MRIs of people while they were viewing those billions of YouTube frames. Crunch a big enough data set of images and their resultant MRIs and the computer could eventually predict from the MRI what the subject was looking at.
Google scientists then looked at brain MRIs of people while they were viewing those billions of YouTube frames. Crunch a big enough data set of images and their resultant MRIs and the computer could eventually predict from the MRI what the subject was looking at.
That's reading minds and again we don't know how.
Advance science by eliminating the scientists.What do scientists do? They theorize. Big Data in certain cases makes theory either unnecessary or simply impossible. The 2013 Nobel Prize in Chemistry, for example, was awarded to a trio of biologists who did all their research on deriving algorithms to explain the chemistry of enzymes using computers. No enzymes were killed in the winning of this prize.
Algorithms are currently improving at twice the rate of Moore's Law.
What's changing is the emergence of a new Information Technology workflow that goes from the traditional:
1) New hardware enables new software
2) New software is written to do new jobs enabled by the new hardware
3) Moore's Law brings hardware costs down over time and new software is consumerized.
4) Rinse, repeat
To the next generation:
1) Massive parallelism allows new algorithms to be organically derived
2) New algorithms are deployed on consumer hardware
3) Moore's Law is effectively accelerated though at some peril (we don't understand our algorithms)
4) Rinse, repeat
What's key here are the new derive-deploy steps and moving beyond what has always been required for a significant technology leap - a new computing platform. What's after mobile, people ask? This is after mobile. What will it look like? Nobody knows and it may not matter.
In 10 years Moore's Law will increase processor power by 128X. By throwing more processor cores at problems and leveraging the rapid pace of algorithm development we ought to increase that by another 128X for a total of 16,384X. Remember Google Vision is currently the equivalent of 0.1 visual cortex. Now multiply that by 16,384 to get 1,638 visual cortex equivalents. That's where this is heading.
A decade from now computer vision will be seeing things we can't even understand, like dogs sniffing cancer today.
We've simultaneously hit a wall in our ability to generate appropriate theories while finding in Big Data a hack to keep improving results anyway. The only problem is we no longer understand why things work. How long from there to when we completely lose control?
 That's coming around 2029, according to Ray Kurzweil, when we'll reach the technological singularity.
That's coming around 2029, according to Ray Kurzweil, when we'll reach the technological singularity.
That's the year the noted futurist (and Googler) says $1000 will be able to buy enough computing power to match 10,000 human brains. For the price of a PC, says Ray, we'll be able to harness more computational power than we can understand or even describe. A virtual supercomputer in every garage.
Matched with equally fast networks this could mean your computer - or whatever the device is called - could search in its entirety in real time every word ever writtento answer literally any answerable question. No leaving stones unturned.
Nowhere to hide.Apply this in a world where every electric device is a sensor feeding the network and we'll have not only incredibly effective fire alarms, we're also likely to have lost all personal privacy.
 Those who predict the future tend to overestimate change in the short term and underestimate change in the long term. The Desk Set from 1957 with Katherine Hepburn and Spencer Tracy envisioned mainframe-based automation eliminating human staffers in a TV network research department. That happened to some extent, though it took another 50 years and people remain part of the process. But the greater technological threat wasn't to the research department but to the TV network itself. Will there even be television networks in 2029? Will there even be television?
Those who predict the future tend to overestimate change in the short term and underestimate change in the long term. The Desk Set from 1957 with Katherine Hepburn and Spencer Tracy envisioned mainframe-based automation eliminating human staffers in a TV network research department. That happened to some extent, though it took another 50 years and people remain part of the process. But the greater technological threat wasn't to the research department but to the TV network itself. Will there even be television networks in 2029? Will there even be television?
Nobody knows.
If you have been reading this series and happen to work at Google, your reaction might be to feel attacked since much of what I am describing seems to threaten our current ways of living and the name "Google" is attached to a lot of it. But that's not the way it is. More properly, it's not the only way it is. Google is a convenient target but much the same work is happening right now at companies like Amazon, Facebook and Microsoft as well as at a hundred or more startup companies. It's not just Google. And regulating Google (as the Europeans are trying to do) or simply putting Google out of business probably won't change a thing. The future is happening, no matter what. Five of those hundred startups will wildly succeed and those alone will be enough to change the world forever.
And that brings us to the self-driving car. Companies like Google and its direct competitors thrive by making computing ever faster and cheaper because it makes them the likely providers of future data-driven products and services. It's the future of industry.
Today if you look at the parts cost of a modern automobile the wiring harness that links together all the electrical bits and controls the whole mechanism costs more than the engine and transmission! This shows our priority lies in command and communication, not propulsion. But those costs are dropping dramatically just as their capabilities are increasing. The $10,000 added cost to Google for making a car self-driving will drop to nothing a decade from now when all new cars will be capable of driving themselves.
Make all new cars self-driving and the nature of our automotive culture changes completely. Cars will go everywhere at the speed limit with just one meter separating each vehicle from the next, increasing the traffic capacity of highways by a factor of 10.
The same effect can be applied to air travel. Self-flying aircraft may mean lots of small planes that swarm like birds flying direct to their destinations.
Or maybe we won't travel at all. Increased computational power and faster networks are already bringing telepresence - life-size video conferencing - into the consumer space.
It could be that the only times we'll physically meet anyone outside our village will be to touch them.
All these things and more are possible. Bio-informatics - the application of massive computing power to medicine - combined with correlative algorithms and machine learning will be finding answers to questions we don't yet know and may never know.
Maybe we'll defeat both diseases and aging, which means we'll all die from homicide, suicide, or horrible accidents.
Big Data companies are rushing headlong, grabbing prime positions as suppliers of the future. Moore's Law is well past the inflection point that made this inevitable. There is no going back now.
So the world is changing completely and we can only guess how that will look and who" or what" will be in control.

Digital Branding
Web DesignMarketing