Common Voice: Mozilla releases the largest dataset of voice samples for free, for all
by Cory Doctorow from Boing Boing on (#4A667)
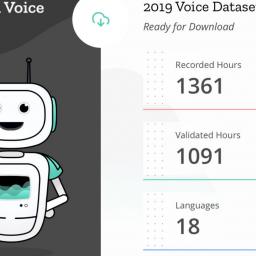
42,000 Mozilla supporters contributed to Common Voice, a free-open dataset of 1,361 hours of voice recordings in 18 languages, which is now free for anyone to use as a set of "high quality, transcribed voice data... available to startups, researchers, and anyone interested in voice-enabled technologies" -- in a field plagued with sampling bias problems, this is a dataset that aims to be diverse, representative and inclusive, and it's growing by the day (you can contribute your voice too!) -- the whole project is inspiring. (via Four Short Links)