Chinese character frequency and entropy
Yesterday I wrote a post looking at the frequency of Koine Greek letters and the corresponding entropy. David Littleboy asked what an analogous calculation would look like for a language like Japanese. This post answers that question.
First of all, information theory defines the Shannon entropy of an "alphabet" to be

bits where pi is the probability of the ith "letter" occurring and the sum is over all letters. I put alphabet and letter in quotes because information theory uses these terms for any collection of symbols. The collection could be a literal alphabet, like the Greek alphabet, or it could be something very different, such as a set of musical notes. For this post it will be a set of Chinese characters.
The original question mentioned Japanese, but I chose to look at Chinese because I found an excellent set of data from Jun Da. See that site for details.
Here's a plot of the character frequencies on a logarithmic scale.
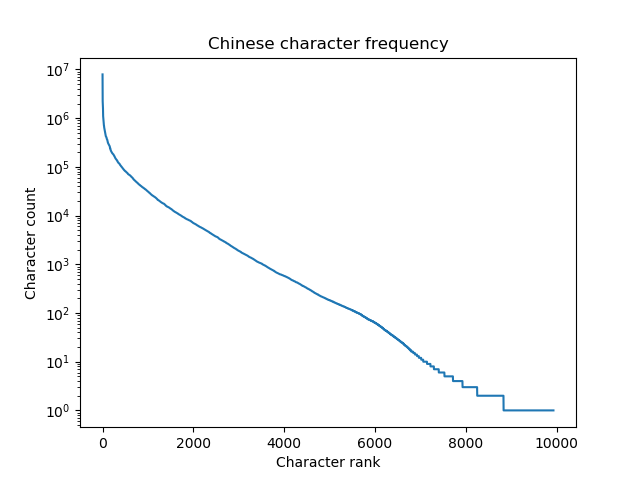
Jun Da's data set contains 9,933 characters. The most common character, c, appears 7,922,684 times in the language corpus and the least common character on the list, e', appears once. The 1,000 most common characters account for 89% of use.
The Shannon entropy of the Chinese "alphabet" is 9.56 bits per character. By comparison, the entropy of the English alphabet is 3.9 bits per letter.
The entropy of individual symbols doesn't tell the whole story of the information density of the two writing systems. Symbols are not independent, and so the information content of a sequence of symbols will be less than just multiplying the information content per symbol by the number of symbols. I imagine there is more sequential correlation between consecutive English letters than between consecutive Chinese characters, though I haven't seen any data on that. If this is the case, just looking at the entropy of single characters underestimates the relative information density of Chinese writing.
Although writing vary substantially in how much information they convey per symbol, spoken languages may all convey about the same amount of information per unit of time.
A few weeks ago I wrote about new research suggesting that all human languages convey information at about the same rate. Some languages carry more information per syllable than others, as measured by Shannon entropy, but these languages are typically spoken more slowly. The net result is that people convey about 40 bits of information per second, independent of their language. Of course there are variations by region, by individual, etc. And there are limits to any study, though the study in question did consider a wide variety of languages.
Related posts- All languages equally complex
- Writing down an unwritten language
- Estimating vocabulary size with Heaps' law