Nvidia’s New Chip Shows Its Muscle in AI Tests

It's time for the Olympics of machine learning" again, and if you're tired of seeing Nvidia at the top of the podium over and over, too bad. At least this time, the GPU powerhouse put a new contender into the mix, its Hopper GPU, which delivered as much as 4.5 times the performance of its predecessor and is due out in a matter of months. But Hopper was not alone in making it to the podium at MLPerf Inferencing v2.1. Systems based on Qualcomm's AI 100 also made a good showing, and there were other new chips, new types of neural networks, and even new, more realistic ways of testing them.
Before I go on, let me repeat the canned answer to What the heck is MLPerf?"
MLPerf is a set of benchmarks agreed upon by members of the industry group MLCommons. It is the first attempt to provide apples-to-apples comparisons of how good computers are at training and executing (inferencing) neural networks. In MLPerf's inferencing benchmarks, systems made up of combinations of CPUs and GPUs or other accelerator chips are tested on up to six neural networks that perform a variety of common functions-image classification, object detection, speech recognition, 3D medical imaging, natural-language processing, and recommendation. The networks had already been trained on a standard set of data and had to make predictions about data they had not been exposed to before.
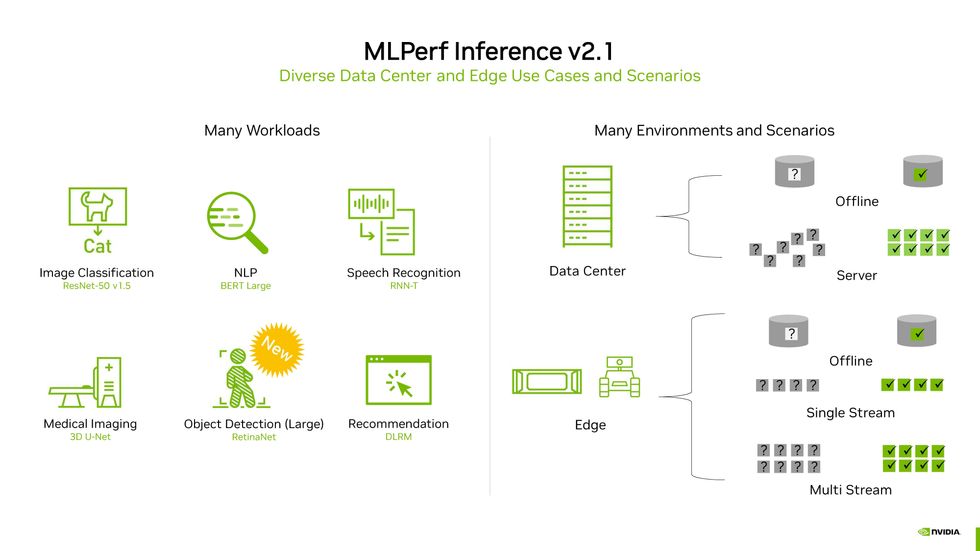 This slide from Nvidia sums up the whole MLPerf effort. Six benchmarks [left] are tested on two types of computers (data center and edge) in a variety of conditions [right].Nvidia
This slide from Nvidia sums up the whole MLPerf effort. Six benchmarks [left] are tested on two types of computers (data center and edge) in a variety of conditions [right].Nvidia
Tested computers are categorized as intended for data centers or the edge." Commercially available data-center-based systems were tested under two conditions-a simulation of real data-center activity where queries arrive in bursts and offline" activity where all the data is available at once. Computers meant to work on-site instead of in the data center-what MLPerf calls the edge, because they're located at the edge of the network-were measured in the offline state; as if they were receiving a single stream of data, such as from a security camera; and as if they had to handle multiple streams of data, the way a car with several cameras and sensors would. In addition to testing raw performance, computers could also compete on efficiency.
The contest was further divided into a closed" category, where everybody had to run the same mathematically equivalent" neural networks and meet the same accuracy measures, and an open" category, where companies could show off how modifications to the standard neural networks make their systems work better. In the contest with the most powerful computers under the most stringent conditions, the closed data-center group, computers with AI accelerator chips from four companies competed: Biren, Nvidia, Qualcomm, and Sapeon. (Intel made two entries without any accelerators, to demonstrate what its CPUs could do on their own.)
While several systems were tested on the entire suite of neural networks, most results were submitted for image recognition, with the natural-language processor BERT (short for Bidirectional Encoder Representations from Transformers) a close second, making those categories the easiest to compare. Several Nvidia-GPU-based systems were tested on the entire suite of benchmarks, but performing even one benchmark can take more than a month of work, engineers involved say.
On the image-recognition trial, startup Biren's new chip, the BR104, performed well. An eight-accelerator computer built with the company's partner, Inspur, blasted through 424,660 samples per second, the fourth-fastest system tested, behind a Qualcomm Cloud AI 100-based machine with 18 accelerators, and two Nvidia A100-based R&D systems from Nettrix and H3C with 20 accelerators each.
But Biren really showed its power on natural-language processing, beating all the other four-accelerator systems by at least 33 percent on the highest-accuracy version of BERT and by even bigger margins among eight-accelerator systems.
An Intel system based on two soon-to-be-released Xeon Sapphire Rapids CPUs without the aid of any accelerators was another standout, edging out a machine using two current-generation Xeons in combination with an accelerator. The difference is partly down to Sapphire Rapids' Advanced Matrix Extensions, an accelerator worked into each of the CPU's cores.
Sapeon presented two systems with different versions of their Sapeon X220 accelerator, testing them only on image recognition. Both handily beat the other single-accelerator computers at this, with the exception of Nvidia's Hopper, which got through six times as much work.
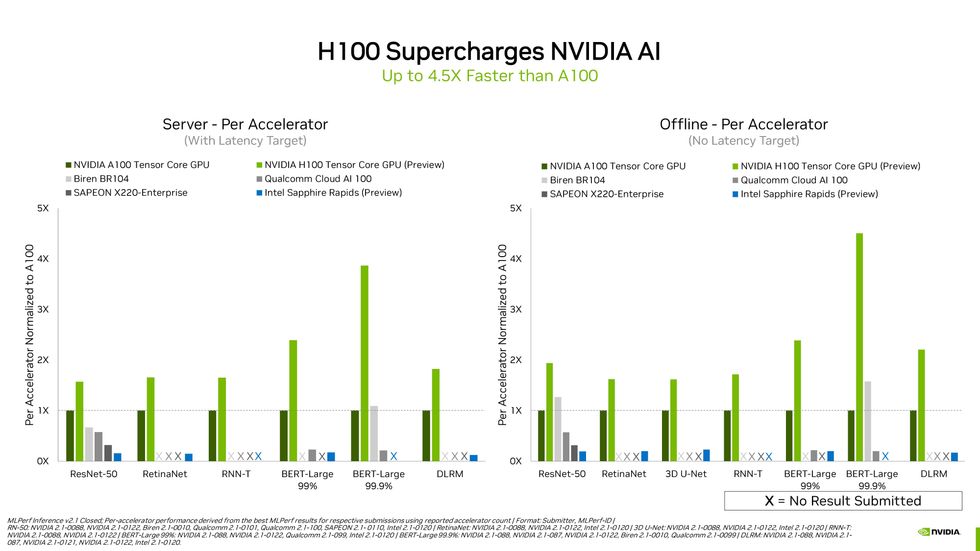 Computers with multiple GPUs or other AI accelerators typically run faster than those with a single accelerator. But on a per-accelerator basis, Nvidia's upcoming H100 pretty much crushed it.Nvidia
Computers with multiple GPUs or other AI accelerators typically run faster than those with a single accelerator. But on a per-accelerator basis, Nvidia's upcoming H100 pretty much crushed it.Nvidia
In fact, among systems with the same configuration, Nvidia's Hopper topped every category. Compared to its predecessor, the A100 GPU, Hopper was at least 1.5 times and up to 4.5 times as fast on a per-accelerator basis, depending on the neural network under test. H100 came in and really brought the thunder," says Dave Salvator, Nvidia's director of product marketing for accelerated cloud computing. Our engineers knocked it out of the park."
Hopper's not-secret-at-all sauce is a system called the transformer engine. Transformers are a class of neural networks that include the natural-language processor in the MLPerf inferencing benchmarks, BERT. The transformer engine is meant to speed inferencing and training by adjusting the precision of the numbers computed in each layer of the neural network, using the minimum needed to reach an accurate result. This includes computing with a modified version of 8-bit floating-point numbers. (Here's a more complete explanation of reduced-precision machine learning.)
Because these results are a first attempt at the MLPerf benchmarks, Salvator says to expect the gap between H100 and A100 to widen, as engineers discover how to get the most out of the new chips. There's good precedence for that. Through software and other improvements, engineers have been able to speed up A100 systems continuously since its introduction in May 2020.
Salvator says to expect H100 results for MLPerf's efficiency benchmarks in future, but for now the company is focused on seeing what kind of performance they can get out of the new chip.
EfficiencyOn the efficiency front, Qualcomm Cloud AI 100-based machines did themselves proud, but this was in a much smaller field than the performance contest. (MLPerf representatives stressed that computers are configured differently for the efficiency tests than for the performance tests, so it's only fair to compare the performance of systems configured to the same purpose.) On the offline image-recognition benchmark for data-center systems, Qualcomm took the top three spots in terms of the number of images they could recognize per joule expended. The contest for efficiency on BERT was much closer. Qualcomm took to the top spot for the 99-percent-accuracy version, but it lost out to an Nvidia A100 system at the 99.99-percent-accuracy task. In both cases the race was close.
The case was similar for image recognition for edge systems, with Qualcomm taking nearly all the top spots by dealing with streams of data in less than a millisecond in most cases and often using less than 0.1 joules to do it. Nvidia's Orin chip, due out within six months, came closest to matching the Qualcomm results. Again, Nvidia was better with BERT, using less energy, though it still couldn't match Qualcomm's speed.
SparsityThere was a lot going on in the open" division of MLPerf, but one of the more interesting results was how companies have been showing how well and efficiently sparse" networks perform. These take a neural network and prune it down, removing nodes that contribute little or nothing toward producing a result. The much smaller network can then, in theory, run faster and more efficiently while using less compute and memory resources.
For example, startup Moffett AI showed results for three computers using its Antoum accelerator architecture for sparse networks. Moffett tested the systems, which are intended for data-center use on image recognition and natural-language processing. At image recognition, the company's commercially available system managed 31,678 samples per second, and its coming chip hit 95,784 samples per second. For reference, the H100 hit 95,784 samples per second, but the Nvidia machine was working on the full neural network and met a higher accuracy target.
Another sparsity-focused firm, Neural Magic, showed off software that applies sparsity algorithms to neural networks so that they run faster on commodity CPUs. Its algorithms decreased the size of a version of BERT from 1.3 gigabytes to about 10 megabytes and boosted throughput from about 10 samples per second to 1,000, the company says.
And finally, Tel Aviv-based Deci used software it calls Automated Neural Architecture Construction technology (AutoNAC) to produce a version of BERT optimized to run on an AMD CPU. The resulting network sped throughput more than sixfold using a model that was one-third the size of the reference neural network.
And MoreWith more than 7,400 measurements across a host of categories, there's a lot more to unpack. Feel free to take a look yourself at MLCommons.