Detection Stays One Step Ahead of Deepfakes—for Now
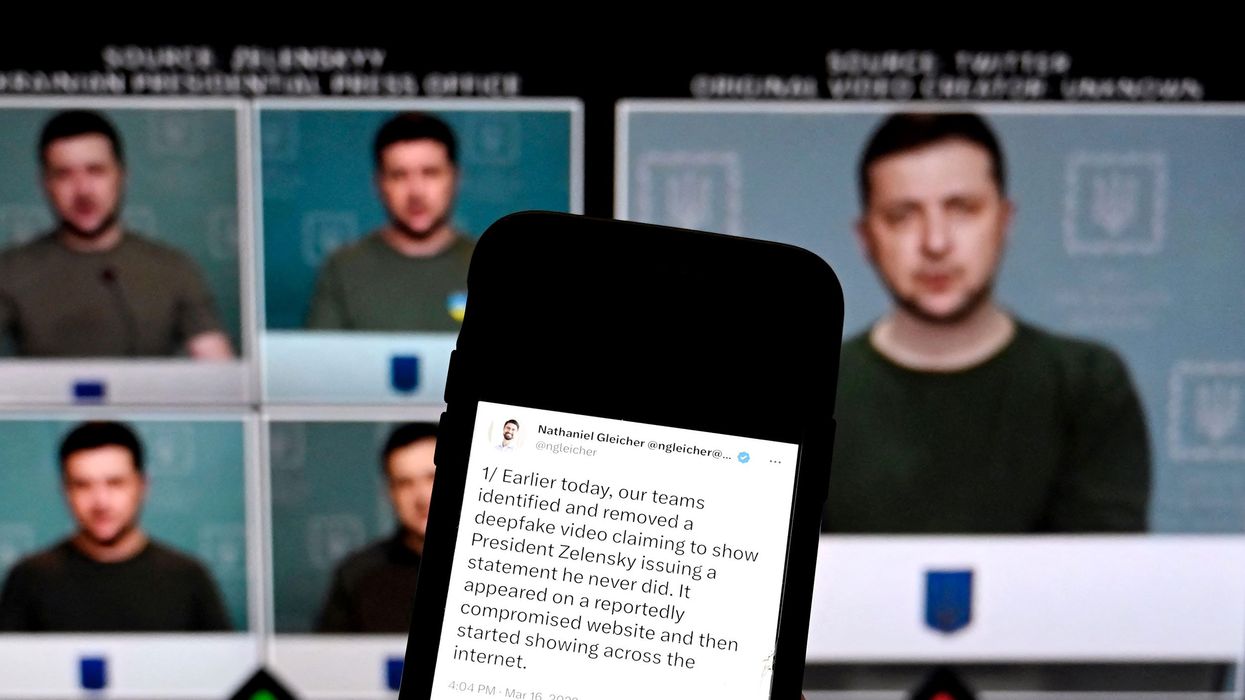
In March 2022, a video appeared online that seemed to show Ukraine's president, Volodymyr Zelensky, asking his troops to lay down their arms in the face of Russia's invasion. The video-created with the help of artificial intelligence-was poor in quality and the ruse was quickly debunked, but as synthetic content becomes easier to produce and more convincing, a similar effort could someday have serious geopolitical consequences.
That's in part why, as computer scientists devise better methods for algorithmically generating video, audio, images, and text-typically for more constructive uses such as enabling artists to manifest their visions-they're also creating counter-algorithms to detect such synthetic content. Recent research shows progress in making detection more robust, sometimes by looking beyond subtle signatures of particular generation tools and instead utilizing underlying physical and biological signals that are hard for AI to imitate.
It's also entirely possible that AI-generated content and detection methods will become locked in a perpetual back-and-forth as both sides become more sophisticated. The main problem is how to handle new technology," Luisa Verdoliva, a computer scientist at the University of Naples Federico II, says of the novel generation methods that keep cropping up. In this respect, it never ends."
In November, Intel announced its Real-Time Deepfake Detector, a platform for analyzing videos. (The term deepfake" derives from the use of deep learning-an area of AI that uses many-layered artificial neural networks-to create fake content.) Likely customers include social-media companies, broadcasters, and NGOs that can distribute detectors to the general public, says Ilke Demir, a researcher at Intel. One of Intel's processors can analyze 72 video streams at once. Eventually the platform will apply several detection tools, but when it launches this spring it will use a detector that Demir cocreated (with Umur Ciftci, at Binghamton University) called FakeCatcher.
FakeCatcher studies color changes in faces to infer blood flow, a process called photoplethysmography (PPG). The researchers designed the software to focus on certain patterns of color on certain facial regions and to ignore anything extraneous. If they'd allowed it to use all the information in a video, then during training it might have come to rely on signals that other video generators could more easily manipulate. PPG signals are special in the sense that they're everywhere on your skin," Demir says. It's not just eyes or lips. And changing illumination does not eliminate them, but any generative operation actually eliminates them, because the type of noise that they're adding messes up the spatial, spectral, and temporal correlations." Put another way, FakeCatcher makes sure that color fluctuates naturally over time as the heart pumps blood, and that there's coherence across facial regions. In one test, the detector achieved 91 percent accuracy, nearly nine percentage points better than the next-best system.
Synthetic-media creation and detection is an arms race, one in which each side builds on the other. Given a new detection method, someone can often train a generation algorithm to become better at fooling it. A key advantage of FakeCatcher is that it's not differentiable, a mathematical term meaning it can't easily be reverse-engineered for the sake of training generators.
Intel's platform will also eventually use a system Demir and Ciftci recently developed that relies on facial motion. Whereas natural motion obeys facial structure, deepfake motion looks different. So instead of training a neural network on raw video, their method first applies a motion-magnification algorithm to the video, making motion more salient, before feeding it to a neural network. On one test, their system detected with 97 percent accuracy not only whether a video was fake, but which of several algorithms had created it, more than three percentage points better than the next-best system.
 Intel
Intel
Researchers at the University of California, Santa Barbara, took a similar approach in a recent paper. Michael Goebel, a Ph.D. student in electrical engineering at UCSB and a paper coauthor, notes that there's a spectrum of detection methods. At one extreme, you have very unconstrained methods that are just pure deep learning," meaning they use all the data available. At the other extreme, you have methods that do things like analyze gaze. Ours is kind of in the middle." Their system, called PhaseForensics, focuses on lips and extracts information about motion at various frequencies before providing this digested data to a neural network. By using the motion features themselves, we kind of hard-code in some of what we want the neural network to learn," Goebel says.
One benefit of this middle-ground, he notes, is generalizability. If you train an unconstrained detector on videos from some generation algorithms, it will learn to detect their signatures but not necessarily those of other algorithms. The UCSB team trained PhaseForensics on one data set, then tested it on three others. Its accuracy was 78 percent, 91 percent, and 94 percent, about four percentage points better than the best comparison method on each respective dataset.
Audio deepfakes have also become a problem. In January, someone uploaded a fake clip of the actress Emma Watson reading part of Hitler's Mein Kampf. Here, too, researchers are on the case. In one approach, scientists at the University of Florida developed a system that models the human vocal tract. Trained on real and fake audio recordings, it created a range of realistic values for cross-sectional areas various distances along a sound-producing airway. Given a new suspicious sample, it can determine if it is biologically plausible. The paper reports accuracy on one data set of around 99 percent.
The algorithm doesn't need to have seen deepfake audio from a particular generation algorithm in order to defend against it. Verdoliva, of Naples, has developed another such method. During training, the algorithm learns to find biometric signatures of speakers. When implemented, it takes real recordings of a given speaker, uses its learned techniques to find the biometric signature, then looks for that signature in a questionable recording. On one test set, it achieved an AUC" score (which takes into account false positives and false negatives) of 0.92 out of 1.0. The best competitor scored 0.72.
Verdoliva's group has also worked on identifying generated and manipulated images, whether altered by AI or by old-fashioned cut-and-paste in Photoshop. They trained a system called TruFor on photos from 1,475 cameras, and it learned to recognize the kinds of signatures left by such cameras. Looking at a new image, it can detect mismatches between different patches (even from new cameras), or tell whether the whole image doesn't look like it plausibly came from a camera. On one test, TruFor scored an AUC of 0.86, while the best competitor scored 0.80. Further, it can highlight which parts of an image contribute most to its judgment, helping humans double-check its work.
High-school students are now regularly in the game of using AI to generate content, prompting the text-generating system ChatGPT to write essays. One solution is to ask the creators of such systems, called large language models, to watermark the generated text. Researchers at the University of Maryland recently proposed a method that randomly creates a set of greenlisted vocabulary words, then gives a slight preference to those words when writing. If you know this (secret) list of greenlisted words, you can look for a predominance of them in a piece of text to tell if it probably came from the algorithm. One problem is that there is an increasing number of powerful language models, and we can't expect all of them to watermark their output.
One Princeton student, Edward Tian, created a tool called GPTZero that looks for signs that a text was written by ChatGPT even without watermarking. Humans tend to make more surprising word choices and fluctuate more in sentence length. But GPTZero appears to have limits. One user putting GPTZero to a small test found that it correctly flagged 10 out of 10 AI-authored texts as synthetic, but that it also falsely flagged 8 of 10 human-written ones.
Synthetic-text detection will likely lag far behind detection in other mediums. According to Tom Goldstein, a professor of computer science at the University of Maryland who coauthored the watermarking paper, that's because there's such a diversity in the way people use language, and because there isn't much signal. An essay might have a few hundred words, versus a million pixels in a picture, and words are discrete, unlike subtle variation in pixel color.
There's a lot at stake in detecting synthetic content. It can be used to sway teachers, courts, or electorates. It can produce humiliating or intimidating adult content. The mere idea of deepfakes can erode trust in mediated reality. Demir calls this future dystopian." Short-term, she says, we need detection algorithms. Long-term, we also need protocols that establish provenance, perhaps involving watermarks or blockchains.
People would like to have a magic tool that is able to do everything perfectly and even explain it," Verdoliva says of detection methods. Nothing like that exists, and likely ever will. You need multiple tools." Even if a quiver of detectors can take down deepfakes, the content will have at least a brief life online before it disappears. It will have an impact. So, Verdoliva says, technology alone can't save us. Instead, people need to be educated about the new, nonreality-filled reality.