V-statistics
A few days ago I wrote about U-statistics, statistics which can be expressed as the average of a symmetric function over all combinations of elements of a set. V-statistics can be written as an average of over all products of elements of a set.
Let S be a statistical sample of size n and let h be a symmetric function of r elements. The average of h over all subsets of S with r elements is a U-statistic. The average of h over the Cartesian product of S with itself r times
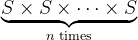
is a V-statistic.
As in the previous post, let h(x, y) = (x - y)^2/2. We can illustrate the V-statistic associated with h with Python code as before.
import numpy as np from itertools import product def var(xs): n = len(xs) h = lambda x, y: (x - y)**2/2 return sum(h(*c) for c in product(xs, repeat=2)) / n**2 xs = np.array([2, 3, 5, 7, 11]) print(np.var(xs)) print(var(xs))
This time, however, we iterate over product rather than over combinations. Note also that at the bottom of the code we print
np.var(xs)
rather than
np.var(xs, ddof=1)
This means our code here is computing the population variance, not the sample variance. We could make this more explicit by supplying the default value of ddof.
np.var(xs, ddof=0)
The point of V-statistics is not to calculate them as above, but that they could be calculated as above. Knowing that a statistic is an average of a symmetric function is theoretically advantageous, but computing a statistic this way would be inefficient.
U-statistics are averages of a function h over all subsamples of S of size r without replacement. V-statistics are averages of h over all subsamples of size r with replacement. The difference between sampling with or without replacement goes away as n increases, and so V-statistics have the same asymptotic properties as U-statistics.
Related posts- Unbiased versus consistent
- Unbiased estimators can be terrible
- Estimating standard deviation from range