Cerebras Introduces Its 2-Exaflop AI Supercomputer

Generative AI is eating the world."
That's how Andrew Feldman, CEO of Silicon Valley AI computer maker Cerebras, begins his introduction to his company's latest achievement: An AI supercomputer capable of 2 billion billion operations per second (2 exaflops). The system, called Condor Galaxy 1, is on track to double in size within 12 weeks. In early 2024, it will be joined by two more systems of double that size. The Silicon Valley company plans to keep adding Condor Galaxy installations next year until it is running a network of nine supercomputers capable of 36 exaflops in total.
If large-language models and other generative AI are eating the world, Cerebras's plan is to help them digest it. And the Sunnyvale, Calif., company is not alone. Other makers of AI-focused computers are building massive systems around either their own specialized processors or Nvidia's latest GPU, the H100. While it's difficult to judge the size and capabilities of most of these systems, Feldman claims Condor Galaxy 1 is already among the largest.
Condor Galaxy 1-assembled and started up in just 10 days-is made up of 32 Cerebras CS-2 computers and is set to expand to 64. The next two systems, to be built in Austin, Texas, and Ashville, N.C., will also house 64 CS-2s each.
The heart of each CS-2 is the Waferscale Engine-2, an AI-specific processor with 2.6 trillion transistors and 850,000 AI cores made from a full wafer of silicon. The chip is so large that the scale of memory, bandwidth, compute resources, and other stuff in the new supercomputers quickly gets a bit ridiculous, as the following graphic shows.
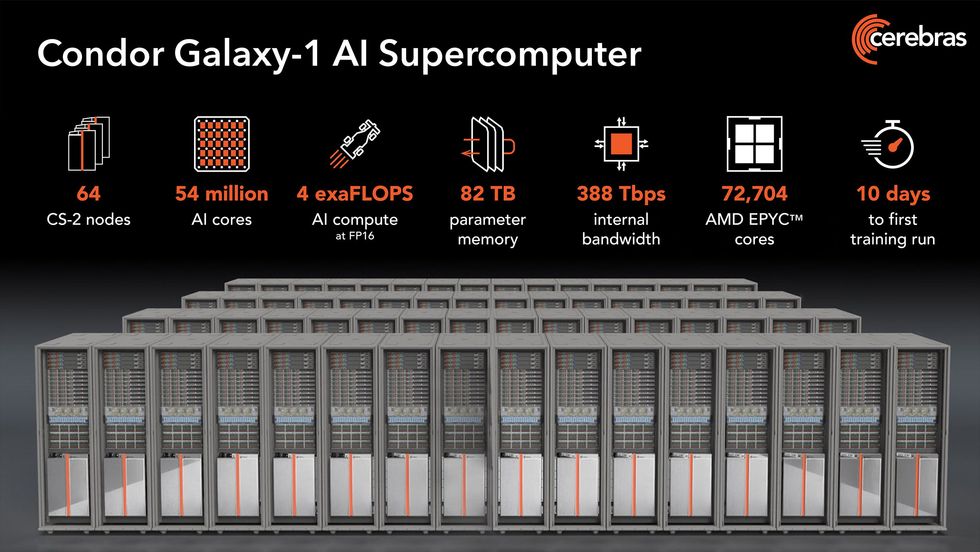 In case you didn't find these numbers overwhelming enough, here's another: There are at least 166 trillion transistors in the Condor Galaxy 1.Cerebras
In case you didn't find these numbers overwhelming enough, here's another: There are at least 166 trillion transistors in the Condor Galaxy 1.Cerebras
One of Cerebras's biggest advantages in building big AI supercomputers is its ability to scale up resources simply, says Feldman. For example, a 40 billion-parameter network can be trained in about the same time as a 1 billion-parameter network if you devote 40-fold more hardware resources to it. Importantly, such a scale-up doesn't require additional lines of code. Demonstrating linear scaling has historically been very troublesome because of the difficulty of dividing up big neural networks so they operate efficiently. We scale linearly from 1 to 32 [CS-2s] with a keystroke," he says.
The Condor Galaxy series is owned by Abu Dhabi-based G42, a holding company with nine AI-based businesses including G42 Cloud, one of the largest cloud-computing providers in the Middle East. Feldman describes the relationship as a deep strategic partnership," which is what's needed to get 36 exaflops up and running in just 18 months, he says. Feldman is planning to move to the UAE for several months later this year to help manage the collaboration, which will substantially add to the global inventory of AI compute," he says. Cerebras will operate the supercomputers for G42 and can rent resources its partner is not using for internal work.
Demand for training large neural networks has shot up, according to Feldman. The number of companies training neural-network models with 50 billion or more parameters went from 2 in 2021 to more than 100 this year, he says.
Obviously, Cerebras isn't the only one going after businesses that need to train really large neural networks. Big players such as Amazon, Google, Meta, and Microsoft have their own offerings. Computer clusters built around Nvidia GPUs dominate much of this business, but some of these companies have developed their own silicon for AI, such as Google's TPU series and Amazon's Trainium. There are also startup competitors to Cerebras, making their own AI accelerators and computers including Habana (now part of Intel), Graphcore, and Samba Nova.
Meta, for example, built its AI Research SuperCluster using more than 6,000 Nvidia A100 GPUs. A planned second phase would push the cluster to 5 exaflops. Google constructed a system containing 4,096 of its TPU v4 accelerators for a total of 1.1 exaflops. That system ripped through the BERT natural language processor neural network, which is much smaller than today's LLMs, in just over 10 seconds. Google also runs Compute Engine A3, which is built around Nvidia H100 GPUs and a custom infrastructure processing unit made with Intel. Cloud provider CoreWeave, in partnership with Nvidia, tested a system of 3,584 H100 GPUs that trained a benchmark representing the large language model GPT-3 in just over 10 minutes. In 2024, Graphcore plans to build a 10-exaflop system called the Good Computer made up of more than 8,000 of its Bow processors.
You can access Condor Galaxy here.
This post was updated on 24 July to add context about Cerebras' relationship with G42.