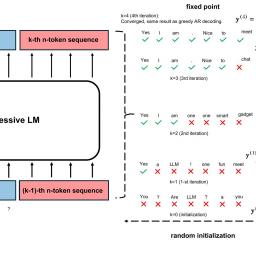
Consistency LLM: converting LLMs to parallel decoders accelerates inference 3.5x
by from Hacker News on (#6MNS5)
| Source | RSS or Atom Feed |
| Feed Location | https://news.ycombinator.com/rss |
| Feed Title | Hacker News |
| Feed Link | https://news.ycombinator.com/ |
| Reply | 0 comments |