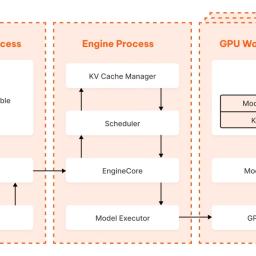
Life of an inference request (vLLM V1): How LLMs are served efficiently at scale
by from Hacker News on (#6Y9ZH)
| Source | RSS or Atom Feed |
| Feed Location | http://news.ycombinator.com/rss |
| Feed Title | Hacker News |
| Feed Link | https://news.ycombinator.com/ |
| Reply | 0 comments |