Three ways to differentiate ReLU
When a function is not differentiable in the classical sense there are multiple ways to compute a generalized derivative. This post will look at three generalizations of the classical derivative, each applied to the ReLU (rectified linear unit) function. The ReLU function is a commonly used activation function for neural networks. It's also called the ramp function for obvious reasons.
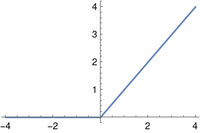
The function is simplyr(x) = max(0,x).
Pointwise derivativeThe pointwise derivative would be 0 forx < 0, 1 for x > 0, and undefined atx = 0. So except at 0, the pointwise derivative of the ramp function is the Heaviside function.

In a real analysis course, you'd simply sayr'(x) =H(x) because functions are only defined up to equivalent modulo sets of measure zero, i.e. the definition atx = 0 doesn't matter.
Indistribution theory you'd identify the functionr(x) with the distribution whose action on a test function is

Then the derivative of r would be the distribution r' satisfying

for all smooth functions with compact support. You can prove using integration by parts that the above equals the integral of from 0 to , which is the same as the action of H(x) on .
In this case the distributional derivative ofr is the same as the pointwise derivative ofr interpreted as a distribution. This does not happen in general [1]. For example, the pointwise derivative of H is zero but the distributional derivative of H is , the Dirac delta distribution.
For more on distributional derivatives, see How to differentiate a non-differentiable function.
SubgradientThe subgradient of a function f at a point x, written f(x), is the set of slopes of tangent lines to the graph off atx. Iff is differentiable atx, then there is only one slope, namelyf'(x), and we typically say the subgradient of f atx is simply f'(x) when strictly speaking we should say it is the one-element set {f'(x)}.
A line tangent to the graph of the ReLU function at a negative value of x has slope 0, and a tangent line at a positivex has slope 1. But because there's a sharp corner atx = 0, a tangent at this point could have any slope between 0 and 1.

My dissertation was full of subgradients of convex functions. This made me uneasy because subgradients are not real-valued functions; they're set-valued functions. Most of the time you can blithely ignore this distinction, but there's always a nagging suspicion that it's going to bite you unexpectedly.
[1] Whenis the pointwise derivative of f as a function equal to the derivative off as a distribution? It's not enough forf to be continuous, but it is sufficient for f to beabsolutely continuous.
The post Three ways to differentiate ReLU first appeared on John D. Cook.