Categorical Data Analysis
Categorical data analysis could mean a couple different things. One is analyzing data that falls into unordered categories (e.g. red, green, and blue) rather than numerical values (e..g. height in centimeters).
Another is using category theory to assist with the analysis of data. Here "category" means something more sophisticated than a list of items you might choose from in a drop-down menu. Instead we're talking about applied category theory.
So we have ((categorical data) analysis) and (categorical (data analysis)), i.e. analyzing categorical data and categorically analyzing data. The former is far, far more common.
I ran across Alan Agresti's classic book the other day in a used book store. The image below if from the third (2012) edition. The book store had the 1st (1990) edition with a more austere cover.

I bought Agresti's book because it's a good reference to have. But I was a little disappointed. My first thought was that someone has written a book on category theory and statistics, which is not the case, as far as I know.
The main reference for category theory and statistics is Peter McCullagh's 2002 paper What is a statistical model? That paper raised a lot of interesting ideas, but the statistics community did not take McCullagh's bait.
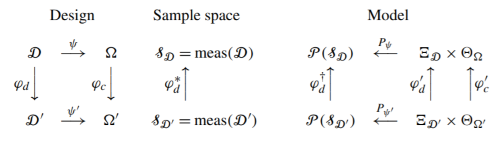
Maybe this just wasn't a fruitful idea. I suspect it is a fruitful idea, but the number of people available to develop it, conversant in both statistics and category theory, is very small. I've seen category theory used in mathematical modeling more generally, but not in statistics per se.
At its most basic, category theory asks you to be explicit about the domain and range (codomain) of functions. It would be very helpful if statisticians merely did this. Statistical notation is notoriously bad at where a function goes from and to, or even when a function is a function. Just 0th level category theory, defining categories, would be useful. Maybe it would be useful to go on to identifying limits or adjoints, but simply being explicit about "from" and "to" would be a good start.
Category theory is far too abstract to completely carry out a statistical analysis. But it can prompt you to ask questions that check whether your model has any inconsistencies you hadn't noticed. The idea of a "categorical error" doesn't differ that much moving from its philosophical meaning under Aristotle to its mathematical meaning under MacLane. Nor does the idea of something being "natural." One of the primary motivations for creating category theory was to come up with a rigorous definition of what it means for something in math to be "natural."