Racial bias observed in hate speech detection algorithm from Google
Understanding what makes something offensive or hurtful is difficult enough that many people can't figure it out, let alone AI systems. And people of color are frequently left out of AI training sets. So it's little surprise that Alphabet/Google -spawned Jigsaw manages to trip over both of these issues at once, flagging slang used by black Americans as toxic.
To be clear, the study was not specifically about evaluating the company's hate speech detection algorithm, which has faced issues before. Instead it is cited as a contemporary attempt to computationally dissect speech and assign a "toxicity score" - and that it appears to fail in a way indicative of bias against black American speech patterns.
The researchers, at the University of Washington, were interested in the idea that databases of hate speech currently available might have racial biases baked in - like many other data sets that suffered from a lack of inclusive practices during formation.
They looked at a handful of such databases, essentially thousands of tweets annotated by people as being "hateful," "offensive," "abusive" and so on. These databases were also analyzed to find language strongly associated with African American English or white-aligned English.
Combining these two sets basically let them see whether white or black vernacular had a higher or lower chance of being labeled offensive. Lo and behold, black-aligned English was much more likely to be labeled offensive.
For both datasets, we uncover strong associations between inferred AAE dialect and various hate speech categories, specifically the "offensive" label from DWMW 17 (r = 0.42) and the "abusive" label from FDCL 18 (r = 0.35), providing evidence that dialect-based bias is present in these corpora.
The experiment continued with the researchers sourcing their own annotations for tweets, and found that similar biases appeared. But by "priming" annotators with the knowledge that the person tweeting was likely black or using black-aligned English, the likelihood that they would label a tweet offensive dropped considerably.

Examples of control, dialect priming and race priming for annotators
This isn't to say necessarily that annotators are all racist or anything like that. But the job of determining what is and isn't offensive is a complex one socially and linguistically, and obviously awareness of the speaker's identity is important in some cases, especially in cases where terms once used derisively to refer to that identity have been reclaimed.
What's all this got to do with Alphabet, or Jigsaw, or Google? Well, Jigsaw is a company built out of Alphabet - which we all really just think of as Google by another name - with the intention of helping moderate online discussion by automatically detecting (among other things) offensive speech. Its Perspective API lets people input a snippet of text and receive a "toxicity score."
As part of the experiment, the researchers fed to Perspective a bunch of the tweets in question. What they saw were "correlations between dialects/groups in our datasets and the Perspective toxicity scores. All correlations are significant, which indicates potential racial bias for all datasets."
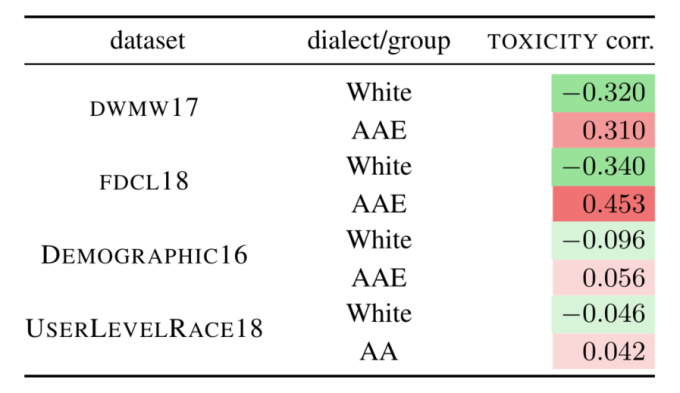
Chart showing that African American English (AAE) was more likely to be labeled toxic by Alphabet's Perspective API
So basically, they found that Perspective was way more likely to label black speech as toxic, and white speech otherwise. Remember, this isn't a model thrown together on the back of a few thousand tweets - it's an attempt at a commercial moderation product.
As this comparison wasn't the primary goal of the research, but rather a byproduct, it should not be taken as some kind of massive takedown of Jigsaw's work. On the other hand, the differences shown are very significant and quite in keeping with the rest of the team's findings. At the very least it is, as with the other data sets evaluated, a signal that the processes involved in their creation need to be reevaluated.
I've asked the researchers for a bit more information on the paper and will update this post if I hear back. In the meantime, you can read the full paper, which was presented at the Proceedings of the Association for Computational Linguistics in Florence, below:
The Risk of Racial Bias in Hate Speech Detection by TechCrunch on Scribd