OctoML raises $15M to make optimizing ML models easier
OctoML, a startup founded by the team behind the Apache TVM machine learning compiler stack project, today announced it has raised a $15 million Series A round led by Amplify, with participation from Madrona Ventures, which led its $3.9 million seed round. The core idea behind OctoML and TVM is to use machine learning to optimize machine learning models so they can more efficiently run on different types of hardware.
"There's been quite a bit of progress in creating machine learning models," OctoML CEO and University of Washington professor Luis Ceze told me. "But a lot of the pain has moved to once you have a model, how do you actually make good use of it in the edge and in the clouds?"
That's where the TVM project comes in, which was launched by Ceze and his collaborators at the University of Washington's Paul G. Allen School of Computer Science & Engineering. It's now an Apache incubating project and because it's seen quite a bit of usage and support from major companies like AWS, ARM, Facebook, Google, Intel, Microsoft, Nvidia, Xilinx and others, the team decided to form a commercial venture around it, which became OctoML. Today, even Amazon Alexa's wake word detection is powered by TVM.

Ceze described TVM as a modern operating system for machine learning models. "A machine learning model is not code, it doesn't have instructions, it has numbers that describe its statistical modeling," he said. "There's quite a few challenges in making it run efficiently on a given hardware platform because there's literally billions and billions of ways in which you can map a model to specific hardware targets. Picking the right one that performs well is a significant task that typically requires human intuition."
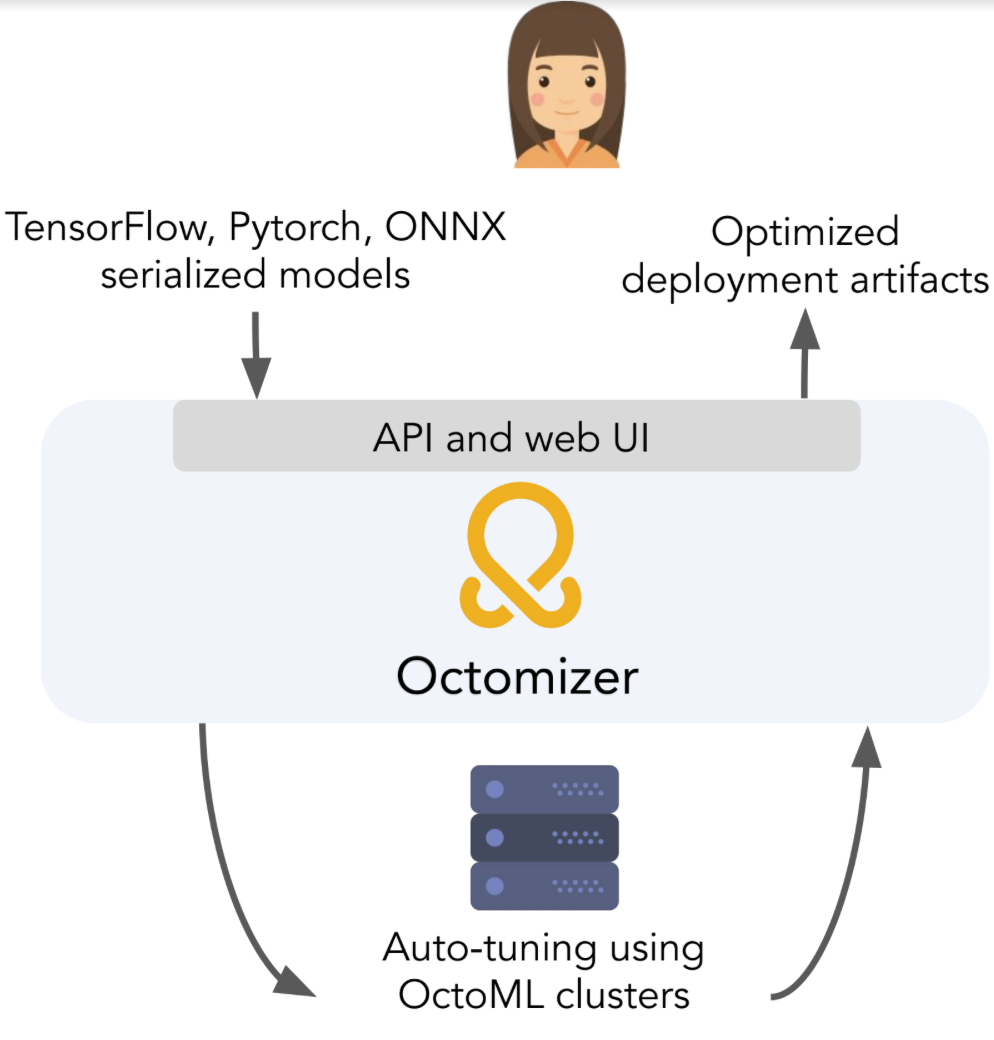 And that's where OctoML and its "Octomizer" SaaS product, which it also announced, today come in. Users can upload their model to the service and it will automatically optimize, benchmark and package it for the hardware you specify and in the format you want. For more advanced users, there's also the option to add the service's API to their CI/CD pipelines. These optimized models run significantly faster because they can now fully leverage the hardware they run on, but what many businesses will maybe care about even more is that these more efficient models also cost them less to run in the cloud, or that they are able to use cheaper hardware with less performance to get the same results. For some use cases, TVM already results in 80x performance gains.
And that's where OctoML and its "Octomizer" SaaS product, which it also announced, today come in. Users can upload their model to the service and it will automatically optimize, benchmark and package it for the hardware you specify and in the format you want. For more advanced users, there's also the option to add the service's API to their CI/CD pipelines. These optimized models run significantly faster because they can now fully leverage the hardware they run on, but what many businesses will maybe care about even more is that these more efficient models also cost them less to run in the cloud, or that they are able to use cheaper hardware with less performance to get the same results. For some use cases, TVM already results in 80x performance gains.
Currently, the OctoML team consists of about 20 engineers. With this new funding, the company plans to expand its team. Those hires will mostly be engineers, but Ceze also stressed that he wants to hire an evangelist, which makes sense, given the company's open-source heritage. He also noted that while the Octomizer is a good start, the real goal here is to build a more fully featured MLOps platform. "OctoML's mission is to build the world's best platform that automates MLOps," he said.