OpenAI’s new experiments in music generation create an uncanny valley Elvis
AI-generated music is a fascinating new field, and deep-pocketed research outfit OpenAI has hit new heights in it, creating recreations of songs in the style of Elvis, 2Pac, and others. The results are convincing, but fall squarely in the unnerving uncanny valley" of audio, sounding rather like good, but drunk, karaoke heard through a haze of drugs.
Jukebox, the organization's new music-generating system, was detailed in a blog post and paper published today. OpenAI produced some interesting work almost exactly a year ago with MuseNet, a machine learning system that, having ingested a great deal of MIDI-based music, was able to mix and match genres and instruments.
MuseNet generates original songs in seconds, from Bollywood to Bach (or both)
But MIDI is a simpler format than final recorded music with live instruments, since the former consists of discrete notes and key presses rather than complex harmonics and voices.
If you wanted an AI to examine the structure of a classical piano piece, the timing and key presses might only amount to a couple thousand pieces of information. Recorded audio is far denser, with (usually) 44,100 samples per second.
Machine learning systems that learn and imitate things like instruments and voice work by looking at the most recent words or sounds and predicting the next few, but they generally operate on the order of tens or a hundred pieces of data - the last 30 words or notes predict what the next 30 will be, for instance. So how can a computer learn how a tiny fraction of a waveform 10 seconds and 440,000 samples into a song compare with a sample 90 seconds and 4 million samples in?
OpenAI's solution is to break down the song into more digestible parts - not quite key and chord, but something like that, a machine-palatable summary of 1/128th of a second of the song, picked from a vocabulary" of 2048 options. To be honest it's hard to create an analogy because this is so unlike the way humans remember or understand things - as far as we even understand that.
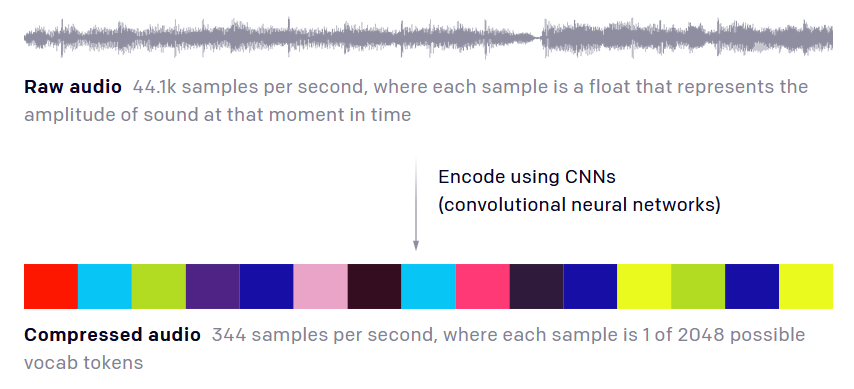
It doesn't actually use color swatches - that's just to indicate that it's breaking the waveform down into pieces.
The end result is that the AI agent has a reliable way to break down a song into digestible bits that are big enough that there aren't too many to track, but small enough that they can reliably reconstruct the sound of a song. The process is much more complex than it sounds here; Reliably breaking down a song to a series of words" and then reconstructing it from them is the core of the new research, but the technical details I'll let the OpenAI team to explain in their paper.
The system also had to learn how to parse the lyrics in a song, which like most things in this domain is more complicated than it sounds. Our ability to remember and use vocal patterns is partly innate and partly learned, and we tend to take for granted how powerful it is. Computers have no such ability and must learn how to pick out a voice from a mix, understand what it's saying, and match that to lyrics that are nothing more than a series of words with no information on key, tempo, and all the rest. Nevertheless the OpenAI system does it to a satisfactory degree.
Jukebox is able to accomplish a variety of musical tasks, and while the results aren't what you might call single material, it must be kept in mind that there's very little like this out there now, able to rebuild a song from scratch that's recognizable as being like the target artist. Trained on 1.2 million songs, the system in the end has one multifaceted ability it accomplishes these tasks with: essentially, improvising a song given lyrics and the style it's learned from ingesting others by that artist.
So given its knowledge of how Ella Fitzgerald sings and the way instruments generally accompany her, it can sing a rendition of At Long last Love" in a way that sounds like her but definitely isn't what Cole Porter had in mind. (Samples for these examples and more are included near the top of the OpenAI blog post.)
Jukebox can also sing entirely original lyrics in another's style, like this truly strange Elvis song, Mitosis," written by another AI language model:
In case you didn't catch that:
From dust we came with humble start;
From dirt to lipid to cell to heart.
With [mitosis] with [meiosis] with time,
At last we woke up with a mind.
From dust we came with friendly help;
From dirt to tube to chip to rack.
With S. G. D. with recurrence with compute,
At last we woke up with a soul.
Yes, it's Elvis" using cell division as a metaphor for life, as imagined by an AI. What a world we live in.
Lastly there's the completion" task, where Jukebox learns (in addition to the base learning from its library) from the first 12 seconds of a song and uses that to generate the rest in a similar style. The switch from original to AI-generated sounds a bit like the ether just kicked in.
While MuseNet could be played with more or less in real time due to its lesser complexity, Jukebox is hugely computation intensive, taking hours to generate a single second of music. We shared Jukebox with an initial set of 10 musicians from various genres... these musicians did not find it immediately applicable to their creative process," the authors note drily. Still, it's fun and fascinating research and, given the current cadence, we can expect an even further improved version of the OpenAI music effort next April.