Self-Driving Cars Learn to Read the Body Language of People on the Street
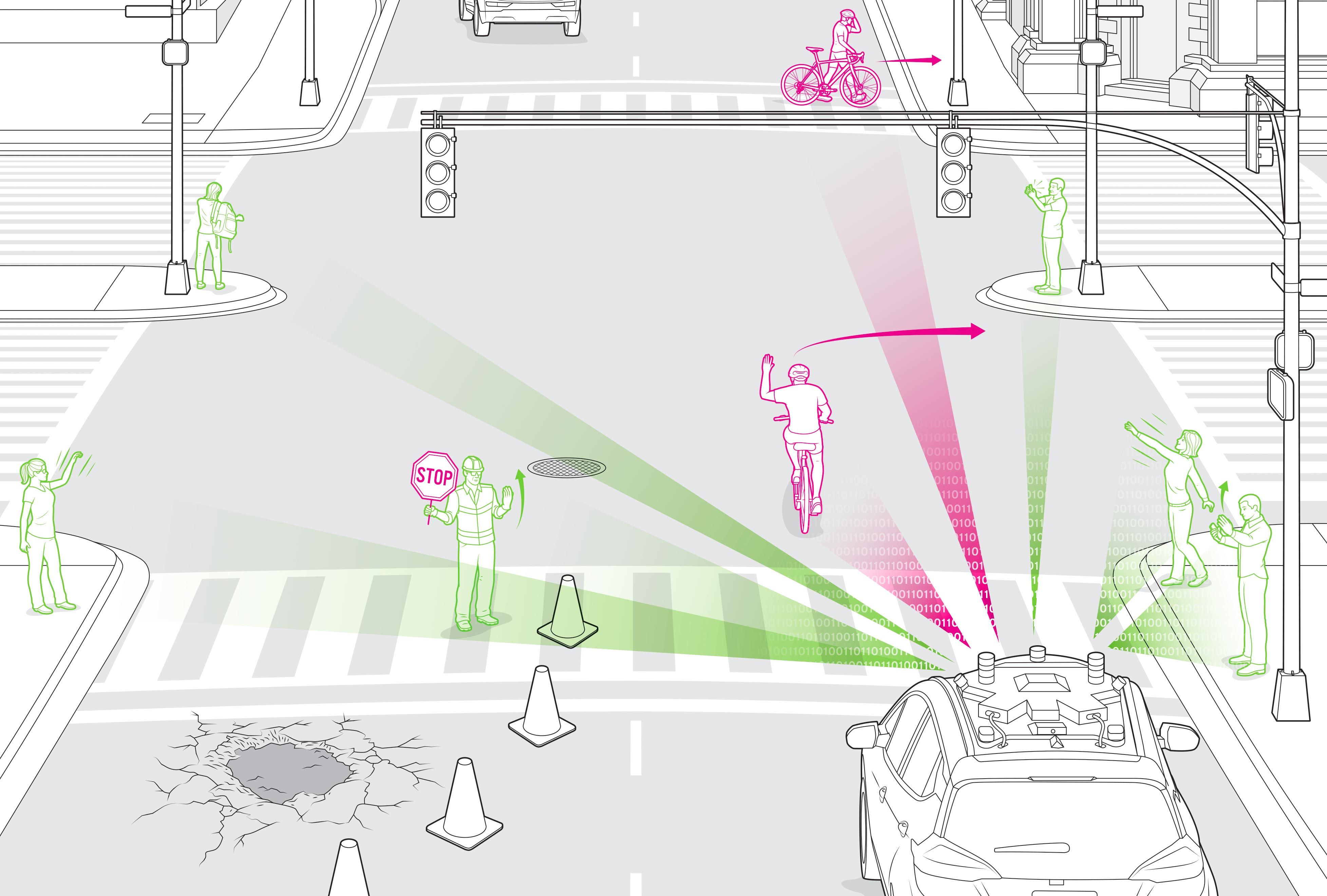 Illustration: Chris Philpot
Illustration: Chris Philpot A four-lane street narrows to two to accommodate workers repairing a large pothole. One worker holds a stop sign loosely in his left hand as he waves cars through with his right. Human drivers don't think twice about whether to follow the gesture or the sign; they move smoothly forward without stopping.
This situation, however, would likely stop an autonomous vehicle in its tracks. It would understand the stop sign and how to react, but that hand gesture? That's a lot more complicated.
And drivers, human and computer, daily face this and far more complex situations in which reading body language is the key. Consider a city street corner: A pedestrian, poised to cross with the light, stops to check her phone and waves a right-turning car forward. Another pedestrian lifts a hand up to wave to a friend across the way, but keeps moving. A human driver can decode these gestures with a glance.
Navigating such challenges safely and seamlessly, without interrupting the flow of traffic, requires that autonomous vehicles understand the common hand motions used to guide human drivers through unexpected situations, along with the gestures and body language of pedestrians going about their business. These are signals that humans react to without much thought, but they present a challenge for a computer system that's still learning about the world around it.
Autonomous-vehicle developers around the world have been working for several years to teach self-driving cars to understand at least some basic hand gestures, initially focusing on signals from cyclists. Generally, developers rely on machine learning to improve vehicles' abilities to identify real-world situations and understand how to deal with them. At Cruise we gather that data from our fleet of more than 200 self-driving cars. These vehicles have logged hundreds of thousands of miles every year for the past seven years; before the pandemic hit, they were on the road around the clock, taking breaks only to recharge (our cars are all-electric) and for regular maintenance. Our cars are learning fast because they are navigating the hilly streets of San Francisco, one of the most complex driving environments in the United States.
But we realized that our machine-learning models don't always have enough training data because our cars don't experience important gestures in the real world often enough. Our vehicles need to recognize each of these situations from different angles and distances and under different lighting conditions-a combination of constraints that produce a huge number of possibilities. It would take us years to gain enough information on these events if we relied only on the real-world experiences of our vehicles.
We at Cruise found a creative solution to the data gap: motion capture (or mo-cap) of human gestures, a technique that game developers use to create characters. Cruise has been hiring game developers-including me-for expertise in simulating detailed worlds, and some of us took on the challenge of capturing data to use in teaching our vehicles to understand gestures.
First, our data-collection team set out to build a comprehensive list of the ways people use their bodies to interact with the world and with other people-when hailing a taxi, say, talking on a phone while walking, or stepping into the street to dodge sidewalk construction. We started with movements that an autonomous vehicle might misconstrue as an order meant for itself-for example, that pedestrian waving to a friend. We then moved on to other gestures made in close proximity to the vehicle but not directed at it, such as parking attendants waving cars in the lane next to the vehicle into a garage and construction workers holding up a sign asking cars to stop temporarily.
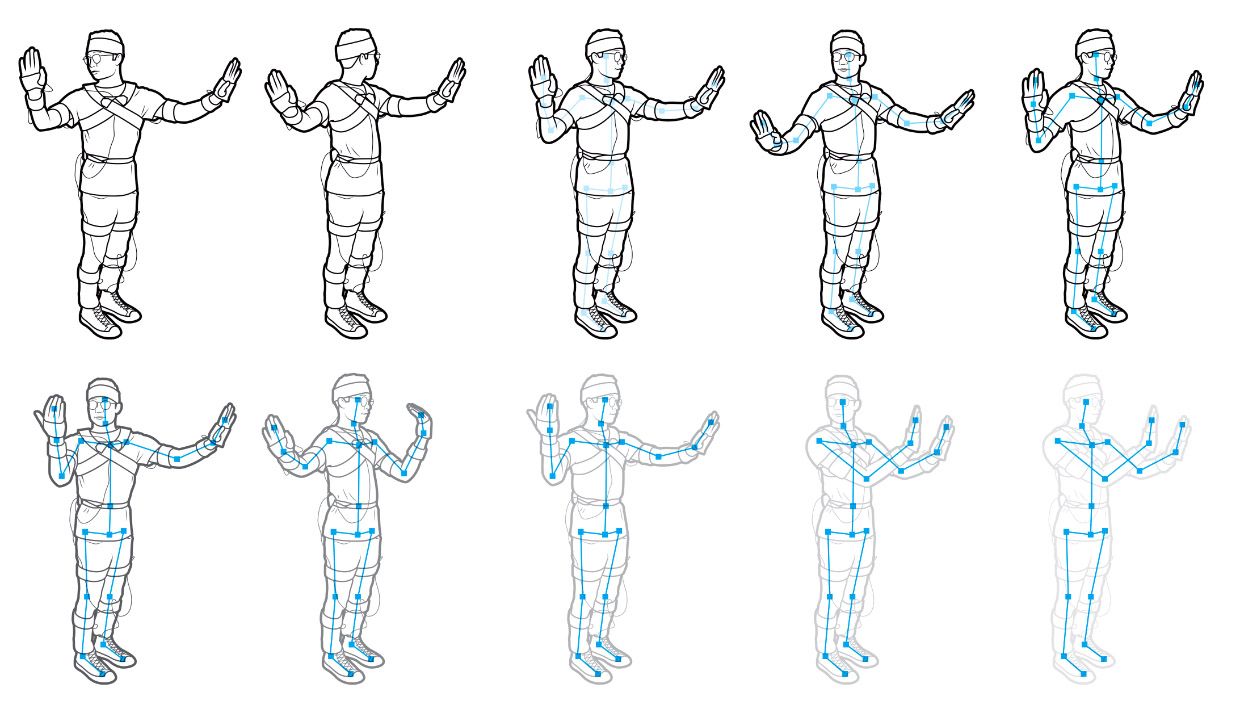 Illustration: Chris Philpot
Illustration: Chris Philpot Ultimately, we came up with an initial list of five key messages that are communicated using gestures: stop, go, turn left, turn right, and what we call no"-that is, common motions that aren't relevant to a passing car, like shooting a selfie or removing a backpack. We used the generally accepted American forms of these gestures, assuming that cars will be driving on the right, because we're testing in San Francisco.
Of course, the gestures people use to send these messages aren't uniform, so we knew from the beginning that our data set would have to contain a lot more than just five examples. Just how many, we weren't sure.
Creating that data set required the use of motion-capture technology. There are two types of mo-cap systems-optical and nonoptical. The optical version of mo-cap uses cameras distributed over a large gridlike structure that surrounds a stage; the video streams from these cameras can be used to triangulate the 3D positions of visual markers on a full-body suit worn by an actor. There are several variations of this system that can produce extremely detailed captures, including those of facial expressions. That's the kind that allows movie actors to portray nonhuman characters, as in the 2009 movie Avatar, and lets the gaming industry record the movements of athletes for the development of sports-themed video games.
Optical motion capture, however, must be performed in a studio setting with a complex multicamera setup. So Cruise selected a nonoptical, sensor-based version of motion capture instead. This technology, which relies on microelectromechanical systems (MEMS), is portable, wireless, and doesn't require dedicated studio space. That gives us a lot of flexibility and allows us to take it out of the studio and into real-world locations.
Our mo-cap suits each incorporate 19-sensor packages attached at key points of the body, including the head and chest and each hip, shoulder, upper arm, forearm, and leg. Each package is about the size of a silver dollar and contains an accelerometer, a gyroscope, and a magnetometer. These are all wired to a belt containing a battery pack, a control bus, and a Wi-Fi radio. The sensor data flows wirelessly to a laptop running dedicated software, which lets our engineers view and evaluate the data in real time.
We recruited five volunteers of varying body characteristics-including differences in height, weight, and gender-from the Cruise engineering team, had them put the suits on, and took them to places that were relatively free from electronic interference. Each engineer-actor began by assuming a T-pose (standing straight, with legs together and arms out to the side) to calibrate the mo-cap system. From there, the actor made one gesture after another, moving through the list of gestures our team had created from our real-world data. Over the course of seven days, we had these five actors run through this gesture set again and again, using each hand separately and in some cases together. We also asked our actors to express different intensities. For example, the intensity would be high for a gesture signaling an urgent stop to a car that's driving too fast in a construction zone. The intensity would be lower for a movement indicating that a car should slow down and come to a gradual stop. We ended up with 239 thirty-second clips.

 Photos: Cruise And...Action! Cruise used data from a motion-capture system to generate the stick figure [bottom] and the animation of a road worker [top] as part of an effort to teach autonomous vehicles to recognize human gestures.
Photos: Cruise And...Action! Cruise used data from a motion-capture system to generate the stick figure [bottom] and the animation of a road worker [top] as part of an effort to teach autonomous vehicles to recognize human gestures. Then our engineers prepared the data to be fed into machine-learning models. First, they verified that all gestures had been correctly recorded without additional noise and that no incorrectly rotated sensors had provided bad data. Then the engineers ran each gesture sequence through software that identified the joint position and orientation of each frame in the sequence. Because these positions were originally captured in three dimensions, the software could calculate multiple 2D perspectives of each sequence; that capability allowed us to expand our gesture set by incrementally rotating the points to simulate 10 different viewpoints. We created even more variations by randomly dropping various points of the body-to simulate the real-world scenarios in which something is hiding those points from view-and again incrementally rotating the remaining points to create different viewing angles.
Besides giving us a broad range of gestures performed by different people and seen from different perspectives, motion capture also gave us remarkably clean data: The skeletal structure of human poses is consistent no matter what the style or color of clothing or the lighting conditions may be. This clean data let us train our machine-learning system more efficiently.
Once our cars are trained on our motion-captured data, they will be better equipped to navigate the various scenarios that city driving presents. One such case is road construction. San Francisco always has a plethora of construction projects under way, which means our cars face workers directing traffic very often. Using our gesture-recognition system, our cars will be able to maneuver safely around multiple workers while comprehending their respective hand gestures.
Take, for example, a situation in which three road workers are blocking the lane that a self-driving car was planning to take. One of the workers is directing traffic and the other two are assessing road damage. The worker directing traffic has a sign in one hand; it has eight sides like a stop sign but reads SLOW." With the other hand he motions to traffic to move forward. To cross the intersection safely, our self-driving vehicle will recognize the person as someone controlling traffic. The vehicle will correctly interpret his gestures to mean that it should shift into the other lane, move forward, and ignore the car that's coming to a stop at the opposite side of the intersection but appears to have the right-of-way.
In another situation, our vehicles will realize that someone entering an intersection and ignoring the flashing Don't Walk" sign is in fact directing traffic, not a pedestrian crossing against the light. The car will note that the person is facing it, rather than presenting his side, as someone preparing to cross the street would do. It will note that one of the person's arms is up and the other is moving so as to signal a vehicle to cross. It will even register assertive behavior. All these things together enable our car to understand that it can continue to move forward, even though it sees someone in the intersection.
Training our self-driving cars to understand gestures is only the beginning. These systems must be able to detect more than just the basic movements of a person. We are continuing to test our gesture-recognition system using video collected by our test vehicles as they navigate the real world. Meanwhile, we have started training our systems to understand the concept of humans carrying or pushing other objects, such as a bicycle. This is important because a human pushing a bicycle usually behaves differently from a human riding a bicycle.
We're also planning to expand our data set to help our cars better understand cyclists' gestures-for example, a left hand pointing up, with a 90-degree angle at the elbow, means the cyclist is going to turn right; a right arm pointing straight out means the same thing. Our cars already recognize cyclists and automatically slow down to make room for them. Knowing what their gestures mean, however, will allow our cars to make sure they give cyclists enough room to perform a signaled maneuver without stopping completely and creating an unnecessary traffic jam. (Our cars still look out for unexpected turns from cyclists who don't signal their intent, of course.)
Self-driving cars will change the way we live our lives in the years to come. And machine learning has taken us a long way in this development. But creative use of technologies like motion capture will allow us to more quickly teach our self-driving fleet to better coexist in cities-and make our roads safer for all.
This article appears in the September 2020 print issue as The New Driver's Ed."
About the AuthorCasey Weaver is a senior engineering manager at Cruise, in San Francisco.