No rules, no problem: DeepMind’s MuZero masters games while learning how to play them
DeepMind has made it a mission to show that not only can an AI truly become proficient at a game, it can do so without even being told the rules. Its newest AI agent, called MuZero, accomplishes this not just with visually simple games with complex strategies, like Go, Chess, and Shogi, but with visually complex Atari games.
The success of DeepMind's earlier AIs was at least partly due to a very efficient navigation of the immense decision trees that represent the possible actions in a game. In Go or Chess these trees are governed by very specific rules, like where pieces can move, what happens when this piece does that, and so on.
The AI that beat world champions at Go, AlphaGo, knew these rules and kept them in mind (or perhaps in RAM) while studying games between and against human players, forming a set of best practices and strategies. The sequel, AlphaGo Zero, did this without human data, playing only against itself. AlphaZero did the same with Go, Chess, and Shogi in 2018, creating a single AI model that could play all these games proficiently.
But in all these cases the AI was presented with a set of immutable, known rules for the games, creating a framework around which it could build its strategies. Think about it: if you're told a pawn can become a queen, you plan for it from the beginning, but if you have to find out, you may develop entirely different strategies.
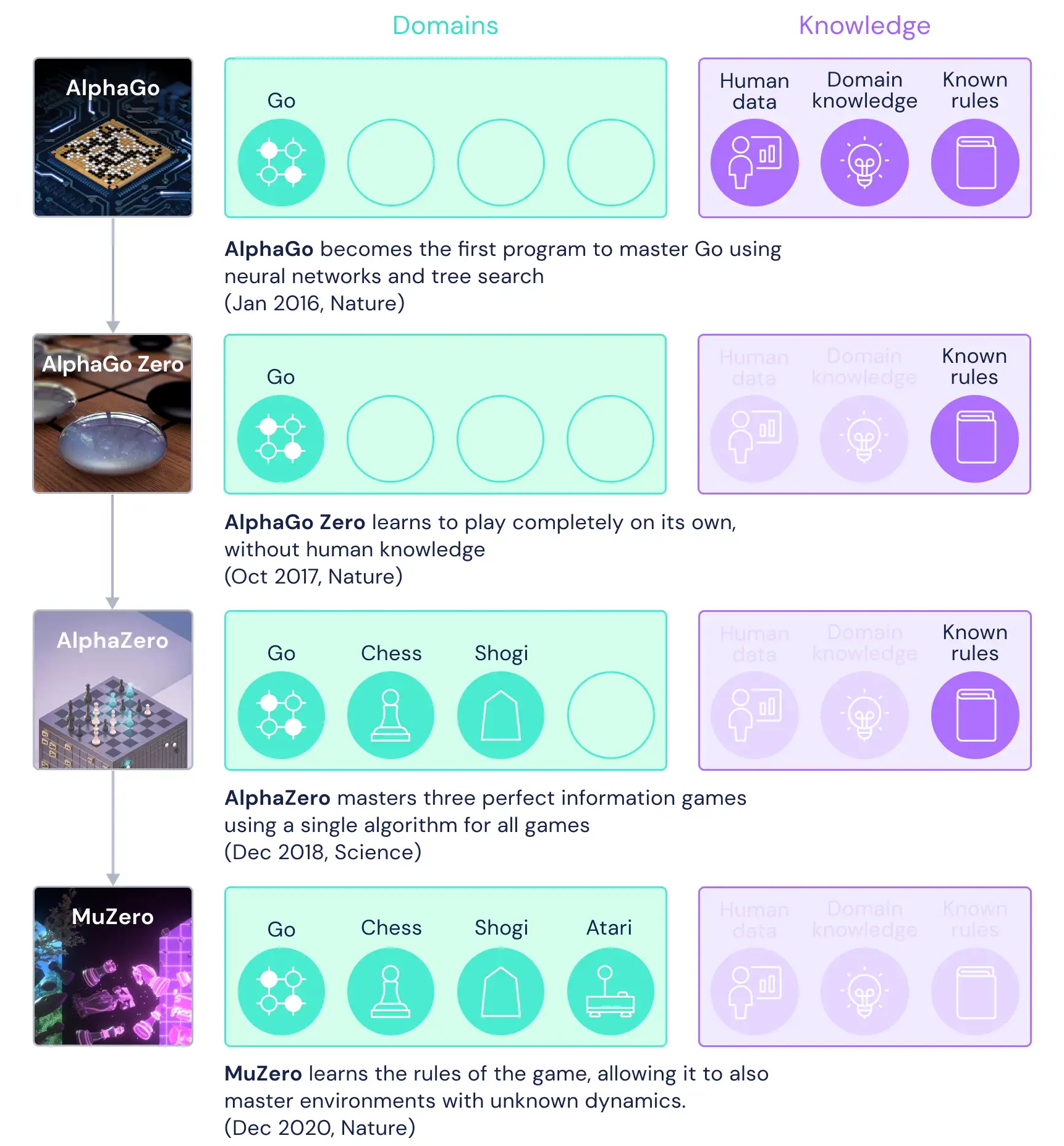
This helpful diagram shows what different models have achieved with different starting knowledge.
As the company explains in a blog post about their new research, if AIs are told the rules ahead of time, this makes it difficult to apply them to messy real world problems which are typically complex and hard to distill into simple rules."
The company's latest advance, then, is MuZero, which plays not only the aforementioned games but a variety of Atari games, and it does so without being provided with a rulebook at all. The final model learned to play all of these games not just from experimenting on its own (no human data) but without being told even the most basic rules.
Instead of using the rules to find the best-case scenario (because it can't), MuZero learns to take into account every aspect of the game environment, observing for itself whether it's important or not. Over millions of games it learns not just the rules, but the general value of a position, general policies for getting ahead, and a way of evaluating its own actions in hindsight.
This latter ability helps it learn from its own mistakes, rewinding and redoing games to try different approaches that further hone the position and policy values.
You may remember Agent57, another DeepMind creation that excelled at a set of 57 Atari games. MuZero takes the best of that AI and combines it with the best of AlphaZero. MuZero differs from the former in that it does not model the entire game environment, but focuses on the parts that affect its decision-making, and from the latter in that it bases its model of the rules purely on its own experimentation and firsthand knowledge.
DeepMind's Agent57 AI agent can best human players across a suite of 57 Atari games
Understanding the game world lets MuZero effectively plan its actions even when the game world is, like many Atari games, partly randomized and visually complex. That pushes it closer to an AI that can safely and intelligently interact with the real world, learning to understand the world around it without the need to be told every detail (though it's likely that a few, like don't crush humans," will be etched in stone). As one of the researchers told the BBC, the team is already experimenting with seeing how MuZero could improve video compression - obviously a very different problem than Ms. Pac-Man.
The details of MuZero were published today in the journal Nature.