Cerebras' Tech Trains "Brain-Scale" AIs

Cerebras Systems, whose CS-2 AI-training computer contains the world's largest single chip, revealed that the addition of new memory system to the computer boosts the size of the neural networks it can train more than 100-fold to 120 trillion parameters. Additionally, the company has come up with two schemes that speed training by linking as many as 192 systems and by efficiently dealing with so-called "sparsity" in neural networks. Cerebras' cofounder and chief hardware architect Sean Lie detailed the technology involved today at the IEEE Hot Chips 33 conference.
The developments come from a combination of four technologies-weight streaming, MemoryX, SwarmX, and selectable sparsity. The first two expand the size of the neural networks CS-2 can train by two orders of magnitude, and they present a shift in the way Cerebras computers have operated.
The CS-2 is designed to train large neural networks quickly. Much of the time saving comes from the fact that the chip is large enough to keep the entire network, consisting primarily of sets of parameters called weights and activations, on the chip. Other systems lose time and power, because they must continually load a fraction of the network onto a chip from DRAM and then store them to make room for the next portion.
With 40 gigabytes of on-chip SRAM, the computer's processor, WSE2, can fit the whole of even the largest of today's common neural networks. But these networks are growing at a rapid pace, increasing 1000-fold in the last few years alone, and they are now approaching 1 trillion parameters. So even a wafer-sized chip is starting to fill up.
To understand the solution, you first have to know a bit about what happens during training. Training involves streaming in the data that the neural net will learn from, and measuring how far from accurate the network is. This difference is used to calculate a "gradient"-how each weight needs to be tweaked to make the network more accurate. That gradient is propagated backward through the network layer by layer. Then the whole process is repeated until the network is as accurate as needed. In Cerebras' original scheme, only the training data is streamed onto the chip. The weights and activations remain in place and the gradient propagates within the chip.
"The new approach is to keep all the activations in place and pour the [weight] parameters in," explains Feldman. The company constructed a hardware add-on to the CS-2 called MemoryX, which stores weights in a mix of DRAM and Flash and streams them into the WSE2 where they interact with the activation values stored on the processor chip. The gradient signal is then sent to the MemoryX unit to adjust the weights. With weight streaming and MemoryX a single CS-2 can now train a neural network with as many as 120 trillion parameters, the company says.
Feldman says he and his cofounders could see the need for weight streaming back when they founded the company in 2015. "We knew at the very beginning we would need two approaches," he says. However "we probably underestimated how fast the world would get to very large parameter sizes." Cerebras began adding engineering resources to weight streaming at the start of 2019.
The other two technologies Cerebras unveiled at Hot Chips are aimed at speeding up the training process. SwarmX is hardware that expands the WSE2's on-chip high-bandwidth network so that it can include as many as 192 CS-2s. Constructing clusters of computers to train massive AI networks is fraught with difficulty, because the network has to be carved up among many processors. The result does not often scale up well, says Feldman. That is, doubling the number of computers in the cluster does not typically double the training speed.
Cerebras' MemoryX system delivers and manipulates weights for neural network training in the CS-2. The SwarmX network allows up to 192 CS-2s to work together on the same network.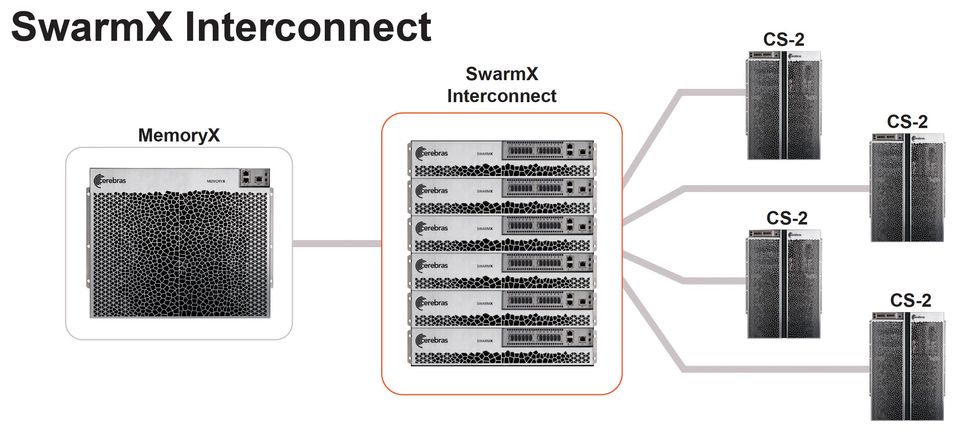 Cerebras' MemoryX system delivers and manipulates weights for neural network training in the CS-2. The SwarmX network allows up to 192 CS-2s to work together on the same network.Cerebras
Cerebras' MemoryX system delivers and manipulates weights for neural network training in the CS-2. The SwarmX network allows up to 192 CS-2s to work together on the same network.Cerebras
"We've finally solved one of the most pressing issues: How to make building clusters easy as pie," says Feldman.
Because a single WSE2 can hold all the activations in a network, Cerebras could come up with a scheme where doubling the number of computers really does double training speed. First a complete set of activations representing the neural network are copied to each CS-2. (For simplicity, let's just assume you've only got two of the AI computers.) Then the same set of weight are streamed to both computers. But the training data is divided in half, with one half of the data sent to each CS-2. Using half the data, computing a gradient takes half the time. Each CS-2 will have come up with a different gradient, but these can be combined to update the weights in MemoryX. The new weights are then streamed to both CS-2s and , just as before, the process repeats until you get an accurate network, which in this case, takes half the time it would with one computer.
Cerebras has done this on a cluster of machines comprising "tens of millions of [AI] cores", says Feldman. With 850,000 cores each, that should be the equivalent of at least twenty CS-2s. The company has simulated the effects of the full 192 machines, showing a linear improvement all the way up to 120-trillion parameter networks.
Neural network weights flow to CS-2 computers linked by the SwarmX system. Training data is divided up and delivered to the CS-2s, which compute the backpropagation gradients that are combined and delivered to MemoryX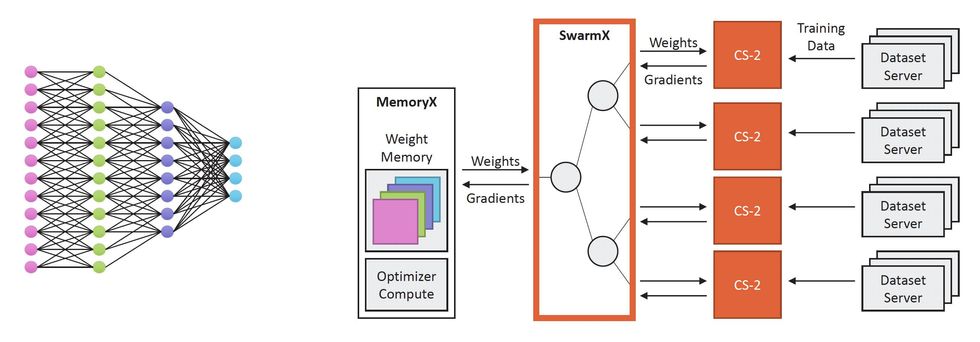 Neural network weights flow to CS-2 computers linked by the SwarmX system. Training data is divided up and delivered to the CS-2s, which compute the backpropagation gradients that are combined and delivered to MemoryXCerebras
Neural network weights flow to CS-2 computers linked by the SwarmX system. Training data is divided up and delivered to the CS-2s, which compute the backpropagation gradients that are combined and delivered to MemoryXCerebras
The final innovation Lie reported at Hot Chips was called sparsity. It's a way of reducing the number of parameters involved in a training run without messing up the network's accuracy. Sparsity is a huge area of research in AI, but for the CS-2, it a lot of it involves never multiplying by zero. Any such effort would be wasted time and energy, because the result is going to be zero anyway. "If you don't do dumb stuff it takes less time," he says.
The WSE2 core architecture is designed to spot these opportunities at a finer-grained level than other processors, says Feldman. He gave the analogy of a pallet stacked with boxes. Most systems can only deal with sparsity at the pallet level. If all the boxes on the pallet are empty, it's safe to toss it. But the WSE2 was designed to work at the level of the box.
The combination of the four innovations should let Cerebras computers stay on top of neural networks even if they grow to brain-scale-about 100 trillion parameters-in terms of the number of connections they have, according to the company.