Greedy AI Agents Learn to Cooperate

Imagine you're sitting at a casino's poker table. Someone has explained the basic rules to you, but you've never played before and don't know even the simplest strategies. While this might sound like the setup for an anxiety dream, it's also a fair analogy for the beginning of a training session for a certain kind of artificial intelligence (AI) program.
If an AI system was confronted with such a situation, it would commence taking random actions within the parameters of the rules-if playing five-card draw, for example, it wouldn't ask for seven cards. When, by dumb luck, it won a hand, it would take careful note of the actions that led to that reward. If it played the game for long enough, perhaps playing millions of hands, it could devise a good strategy for winning.
This type of training is known as reinforcement learning (RL), and it's one of the most exciting areas of machine learning today. RL can be used to teach agents, be they pieces of software or physical robots, how to act to achieve certain goals. And it has been responsible for some of the most impressive triumphs by AI in recent years, such as AlphaGo's win at the board game of Go in a match against a top-ranked human professional.
RL differs from another approach called supervised learning, in which systems are trained using an existing labeled dataset. To continue the poker example: In a supervised-learning regimen, the AI player would ingest data about millions of hands. Each data point would be labeled to describe how good or bad an action is for a given state of the game. This would allow the player to take good actions when it sees game states similar to those in the training data. This isn't a very practical way to train on such sequential decision-making problems, since building a dataset with a massive number of game states and actions is intractable.
Reinforcement learning is responsible for some of the most impressive triumphs by AI in recent years.
In contrast, RL offers a more effective way of training by allowing the player to interact with the world during the training. You don't need a labeled dataset for RL, which proves a big advantage when dealing with real-world applications that don't come with heaps of carefully curated observations. What's more, RL agents can learn strategies that enable them to act even in an uncertain and changing environment, taking their best guesses at the appropriate action when confronted with a new situation.
One typical critique of RL is that it's inefficient, that it's just a glorified trial-and-error process that succeeds because of brute-force computing power put to it. But my research group at Intel's AI Lab has devised efficient techniques that can leverage RL for practical breakthroughs.
We've been working on RL agents that can quickly figure out extremely complex tasks and that can work together in teams, putting the group's overall objective ahead of their own individual goals. We're planning soon to test our methods in robots and other autonomous systems to bring these achievements into the real world.
In RL, we assume that the agent operates with some sort of dynamic environment and that it can at least partially observe the state of that environment. For example, an autonomous vehicle could sense the raw pixel values from an on-board camera, or it could take in more processed data like the location of pedestrians, cars, and lane markings. The environment must also reinforce the agent's actions with certain kinds of feedback-whether an autonomous vehicle reaches its destination without incident or crashes into a wall, say. This feedback signal is typically called the reward.
In modern RL, the agents are typically deep neural networks, ones that map input observations to output actions. A common procedure is for an RL agent to begin by taking a bunch of random actions and logging the feedback signal for each, storing all of these in what's known as a replay buffer-essentially, the agent's memory. Over time, the agent creates a large dataset of experiences that are in the form of a state, an action, the next state, and any resulting reward.
In reinforcement learning, there's a fundamental tension between exploiting an existing strategy and exploring alternatives.
Using this data, the agent trains itself and comes up with a policy, or a way of acting in the environment, that will maximize its total reward. Its policy should get better over time as it learns, but the agent doesn't know whether its policy is optimal at any given point. So it has to make a decision: Should it keep choosing actions based on its current policy or deviate from it and explore new possibilities? If it chooses the former, it will never improve.
Most RL agents therefore have an important mandate to sometimes ignore their current best policy in favor of trying new things. How often agents go "off-policy" is an extra parameter of the training system. Often, the exploration rate is kept high in the beginning of training and lowered as the agent gains experience.
Whether we're dealing with an AI poker player, an autonomous vehicle, or a virtual stock trader, this tension between exploitation of an existing policy and exploration of alternatives is fundamental to RL.
The challenges get even greater when an agent is acting in an environment with sparse rewards. In this situation, the environment provides a feedback signal very rarely--perhaps only at the end of a long multi-step task. So most of the agent's actions produce no helpful feedback. For example, our hypothetical AI poker player would only get a positive reward if it wins a hand, not if it had a good hand but was narrowly beaten by another player. The sparser the rewards, the more difficult the problem.
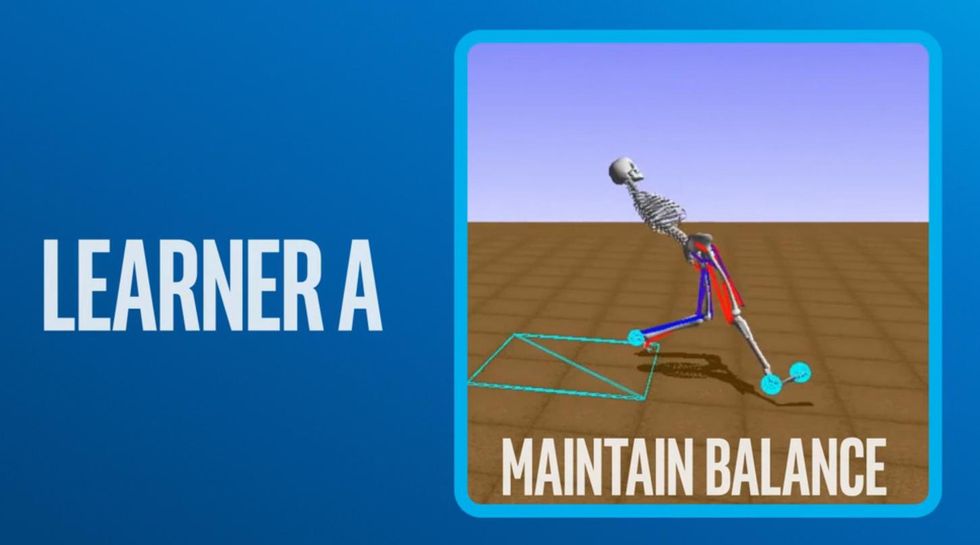
To test RL agents' abilities in such tricky situations, many researchers have made use of a benchmark created by OpenAI called Mujoco Humanoid. Here, researchers must train a computer model of a 3D humanoid figure to walk for a fixed amount of time without falling. While walking sounds simple enough, it's an incredibly difficult task for an RL system to master.
The RL agent's observations include the angles of all the humanoid's joints, each of which has three degrees of freedom. With such a complex array of possible states, a policy of random actions is almost guaranteed to fail. It's incredibly rare that the humanoid stays on its feet and takes enough successful steps to achieve a reward.
For the Mujoco Humanoid challenge, we had many learners working on smaller problems such as not falling over and raising a foot.
We came up with a novel solution, which we call CERL: Collaborative Evolutionary Reinforcement Learning. Our paper about it demonstrated that the challenge at hand can be broken down into two kinds of components: smaller problems for which the system can get some immediate feedback and the larger optimization problem that needs to be solved over a longer time span.
We argued that for each of those smaller problems, we could make faster progress with a population of agents that jointly explore and share experiences. For our hypothetical AI poker player, this would be the equivalent of suddenly spawning many avatars and having them all play hands simultaneously to collectively come up with a strategy.
For the Mujoco Humanoid challenge, we had many learners working on smaller problems such as not falling over, raising a foot, and so forth. The learners received immediate feedback as they tried to achieve these small goals. Each learner thus became an expert in its own skill area, skills that could contribute to the overall goal of sustained walking-although each learner has no chance of attaining that larger objective itself.
 In our approach to the Mujoco Humanoid challenge, a number of "learners" worked on discrete skills, which an "actor" later put together into a complete walking strategy.Intel AI
In our approach to the Mujoco Humanoid challenge, a number of "learners" worked on discrete skills, which an "actor" later put together into a complete walking strategy.Intel AI
In a standard RL process, each agent has its own replay buffer, the memory bank it uses to learn what actions are good or bad. But in our design, we allowed all learners simultaneously to contribute to and draw from a single buffer. This meant that each learner could access the experiences of all the others, helping its own exploration and making it significantly more efficient at its own task. For while they were tackling discrete problems, they were all learning the same rules of basic physics.
A second set of agents, which we called actors, aimed to synthesize all the small movements to achieve the larger objective of sustained walking. Because these agents rarely came close enough to this objective to register a reward, we didn't use RL here. Instead, we employed what's known as a genetic algorithm, a procedure that mimics biological evolution by natural selection. Genetic algorithms, which are a subtype of evolutionary algorithms, start with a population of possible solutions to a problem, and use a fitness function to gradually evolve toward the optimal solution.
In each "generation" we initialized a set of actors, each with a different strategy for carrying out the walking task. We then ranked them by performance, retained the top performing ones, and threw away the rest. The next generation of actors were the "offspring" of the survivors and inherited their policies, though we varied these policies via both mutation (random changes in a single parent's policy) and crossover (mixing two parents' policies).
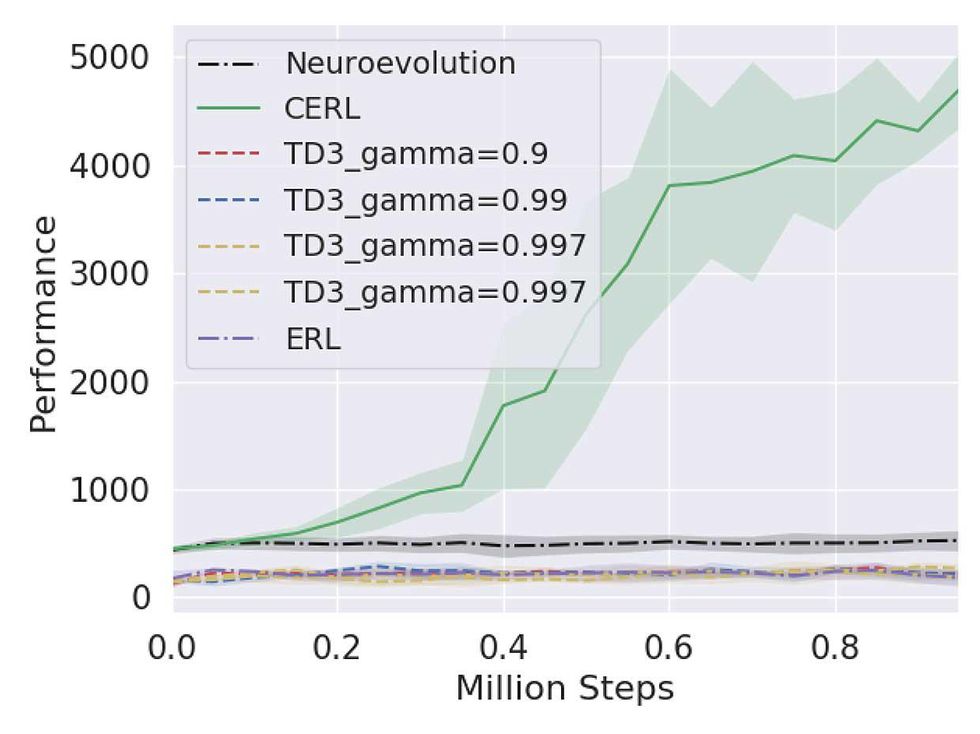 Our system outperformed other baselines on the complex Mujoco Humanoid task.Intel AI
Our system outperformed other baselines on the complex Mujoco Humanoid task.Intel AI
On its own, evolutionary search is known to be extremely slow and inefficient, since it requires a lot of inputs to come up with a good solution. But it's also renowned for its completeness-if a solution exists, it will be found eventually. Our goal was to make use of this completeness while boosting search speed by exploiting fast RL methods. Our RL learners quickly provided reasonably good but sub-optimal solutions, which we inserted into the evolutionary search population to guide our actors towards better solutions. Our hybrid system speedily arrived at an optimal policy that enabled the Mujoco Humanoid to go for a stroll, and greatly outperformed other algorithms at that time.
While a sparsity of rewards make RL hard enough, it becomes even more complicated when a task requires several agents to work cooperatively to achieve a common goal. For example, in a benchmark involving simulated Mars rovers, two rovers have to work together to find multiple targets in the shortest amount of time. For this task, we needed to train the individual rovers not only on skills like navigation, but also on cooperative strategies that would allow a pair of rovers to achieve a joint objective, even without communicating directly.
Rover 1 scrapped its local objective and instead took the longer route to a different target-for the greater good of the team.
Here, the global objective is for the team as a whole to visit the largest number of targets. To achieve that objective, each rover needs to learn how to navigate quickly to a target and also needs to learn how to strategize with its partner. At first, the rovers explore the landscape randomly, using LIDAR sensors to scan for targets. Over a given time interval, one rover might well stumble across a target, so we say that the local objective of navigating to a target has dense rewards. The global objective is achieved only if both rovers find targets, which is a much sparser reward signal.
Imagine that both rovers have a certain target in view. Rover 1 has just enough fuel to reach the target, but can go no farther. In this scenario, the best team strategy is for Rover 1 to go to that visible destination and for Rover 2 to sacrifice its local objective-minimizing its time to a target-and to head out in search of other targets.
 In a benchmark involving simulated rovers, the agents have to work together to achieve the overall goal. Intel AI
In a benchmark involving simulated rovers, the agents have to work together to achieve the overall goal. Intel AI
This problem can be made tougher still by adding another requirement. Imagine that the teams are larger and that several rovers must reach a target simultaneously for it to count. This condition represents situations like search and rescue where multiple agents might be needed to complete a task, such as lifting a heavy beam. If fewer than the required number of rovers reach a target, they receive no reward at all. The rovers therefore have to learn the skills needed to find a target and must also learn to link up with others and visit targets together to achieve the team's global objective. What's more, at the outset, the rovers on a team don't know how many rovers must visit a target together-they get that information only when they are successful.
To tackle this difficult multi-agent task, we extended our CERL framework. We presented our new technique, which we call Multiagent Evolutionary Reinforcement Learning (MERL), at the 2020 International Conference on Machine Learning. We again broke down the problem into two parts. Each rover used RL to master a local objective, such as reducing its distance to a target. But that success didn't help with the larger problems of forming alliances and maximizing the total number of targets visited.
Again, we solved the global problem with evolutionary search. This time, we were working with teams, so we essentially made many copies of an entire rover team. Across those teams, all the Rover 1s shared a single replay buffer, as did all the Rover 2s, and so forth. We deliberately separated the replay buffers by rovers because it allowed each to focus on its own local learning. (We've run similar experiments with a simulated soccer team, where this approach enables goalies, strikers, and other players to learn different skills.)
Because each target was counted only when enough rovers reached it, the rovers were required to work together. Just as in CERL, locally optimized policies were injected into the evolutionary search, which could try out the best policies from the Rover 1s, Rover 2s, and so on. Evolution only needed to deal with the larger team strategy.
We compared the performance of MERL with that of another state-of-the-art system for multi-agent RL, the MADDPG algorithm from the University of California, Berkeley. First we tested our virtual robots on the simpler rover problem where only one rover must reach a target. We found that MERL reached more targets than MADDPG, and also saw interesting team behavior emerge in MERL.

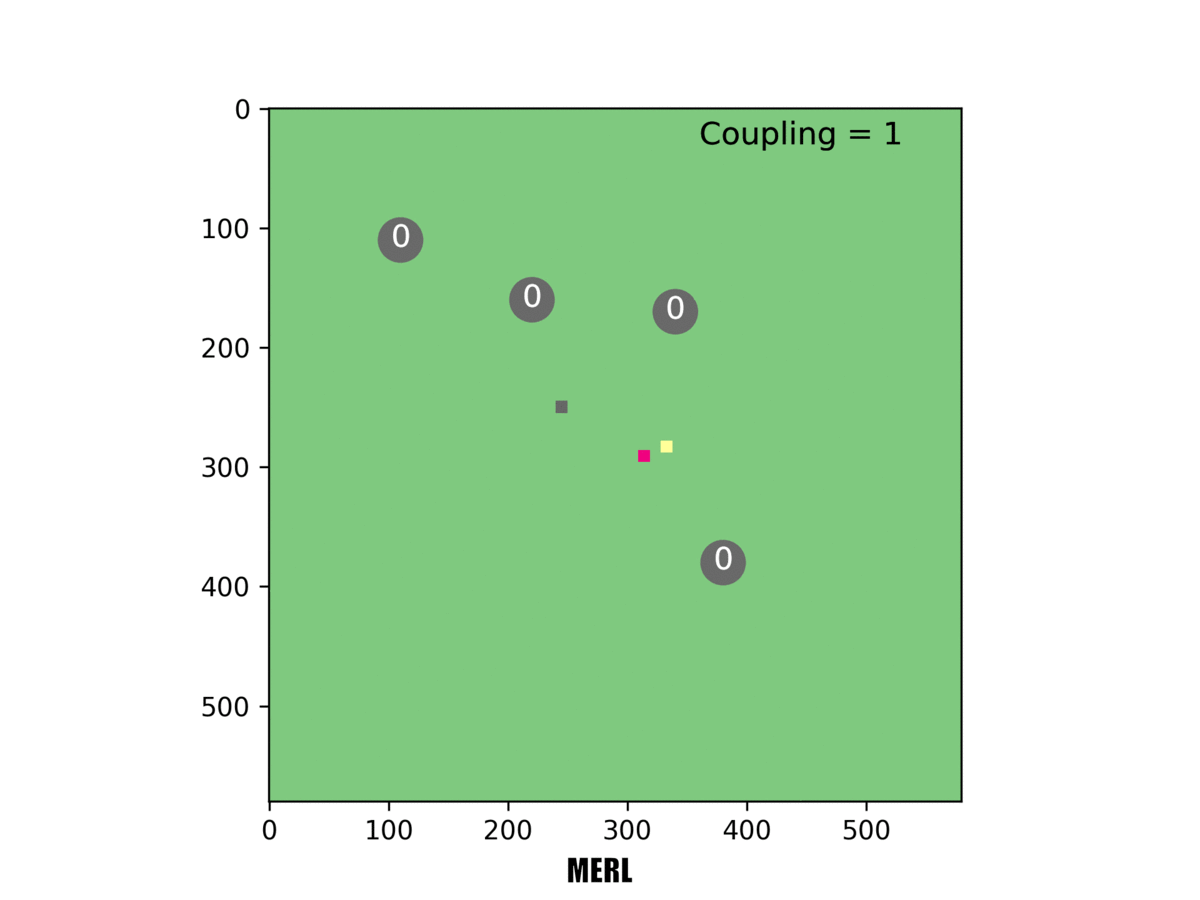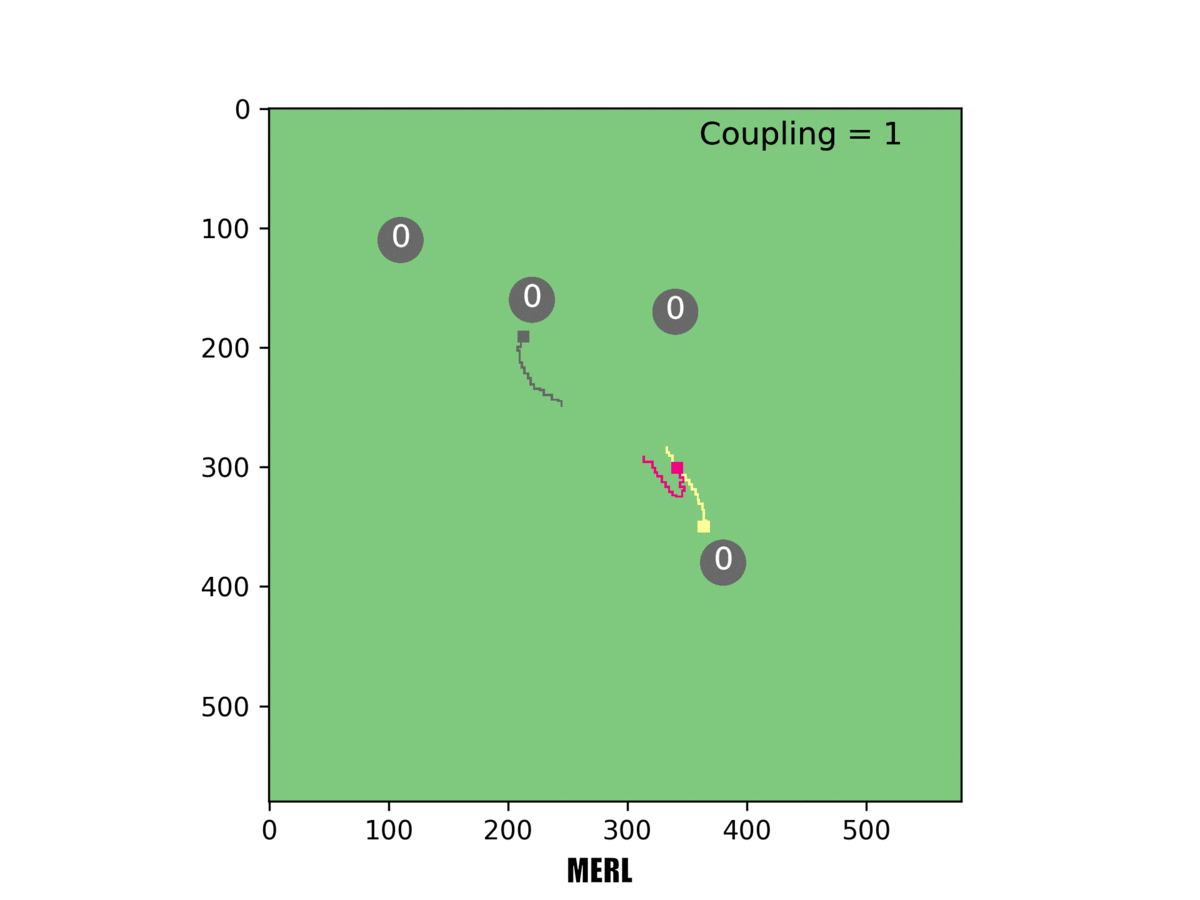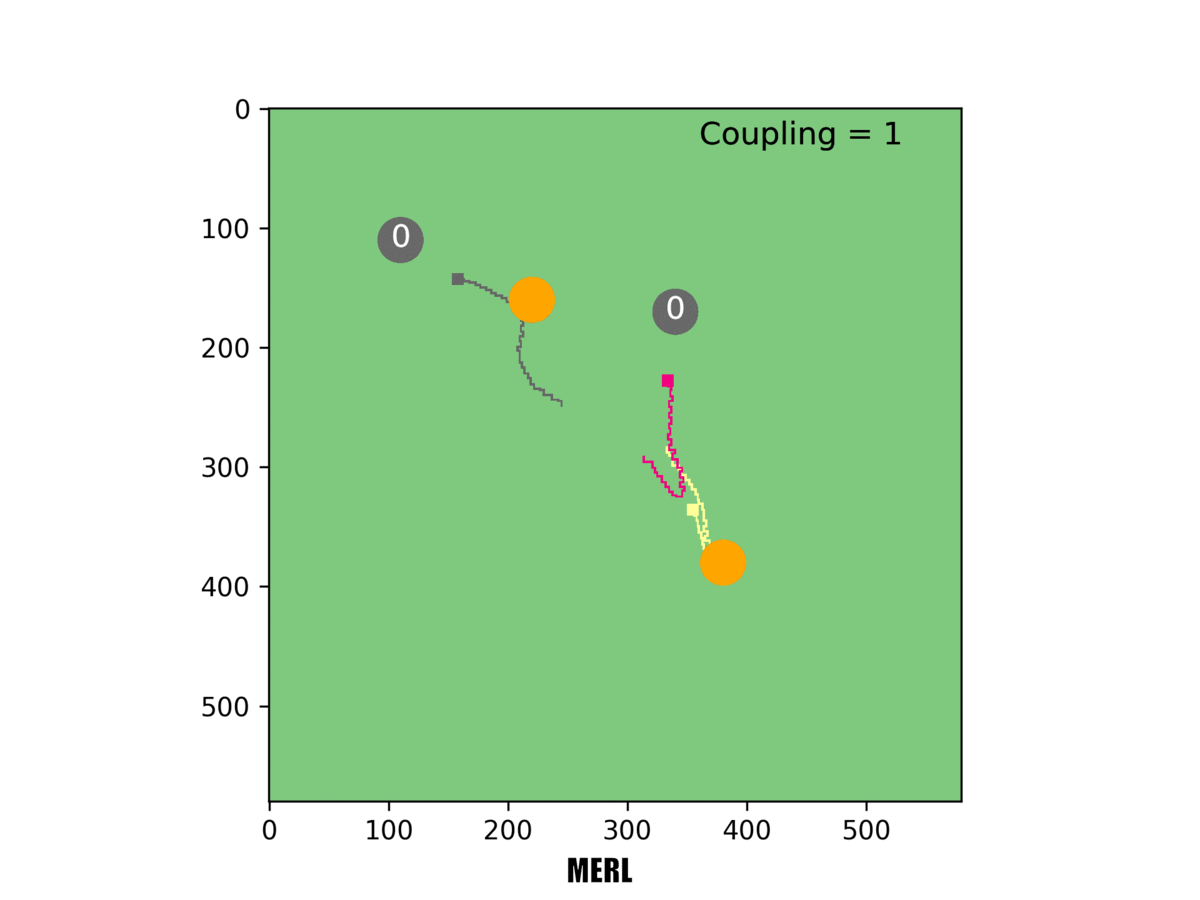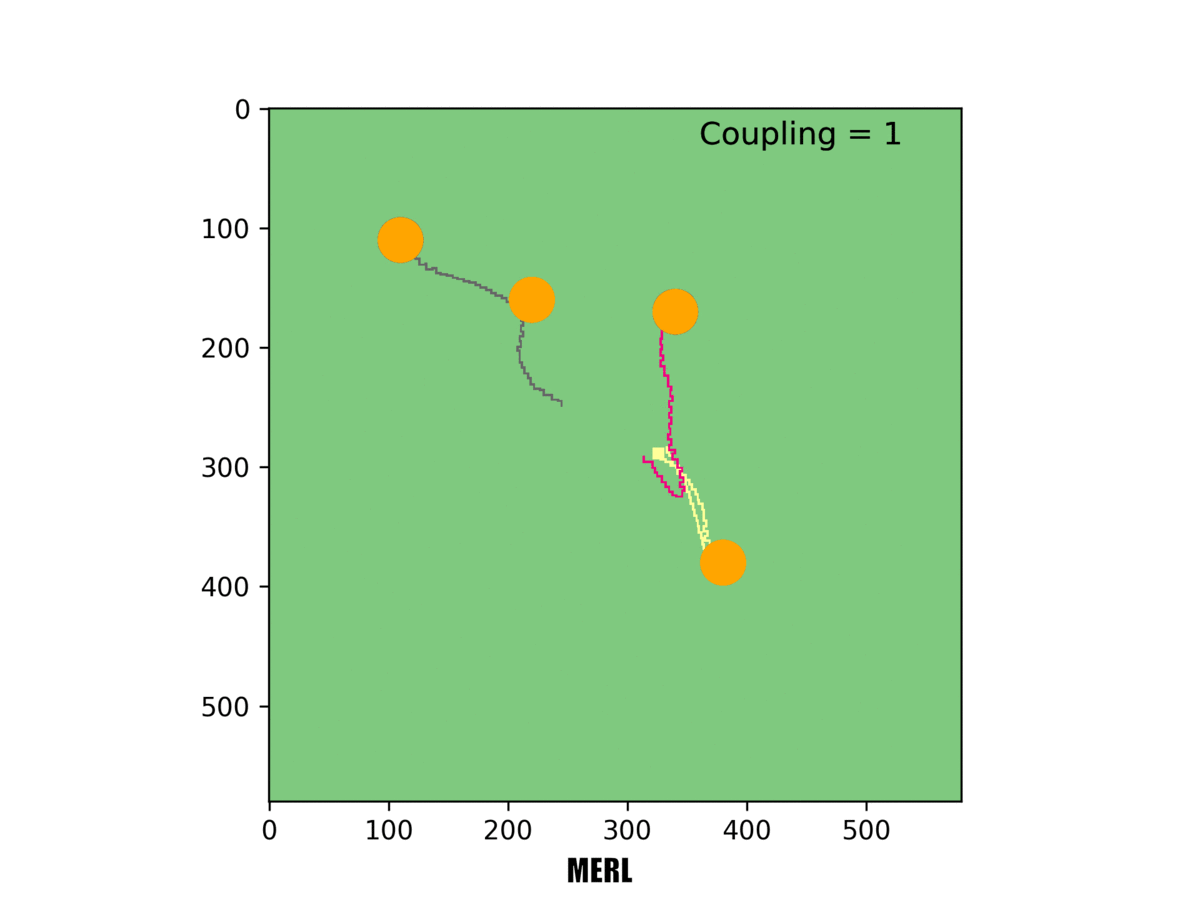
In our system [right], the red rover sacrifices its local objective to help the team. In this example, only one rover must reach a target for it to be counted.
Intel AI
In one example, Rovers 1 and 2 both set out towards the same target, but Rover 1 changed course mid-way and headed for a different target. That made sense: If both rovers reached the target, they wouldn't score additional points. So Rover 1 scrapped its local objective and instead took the longer route to a different target-for the greater good of the team.
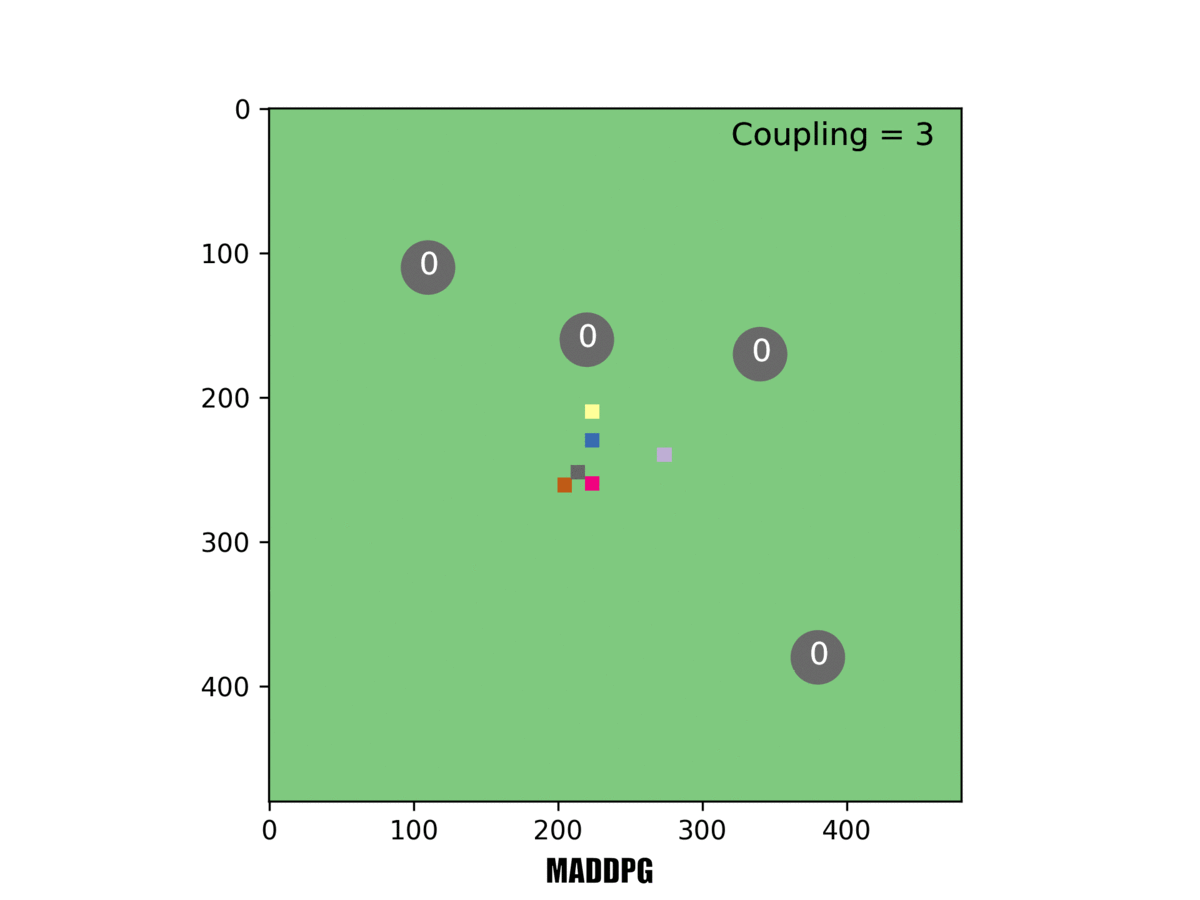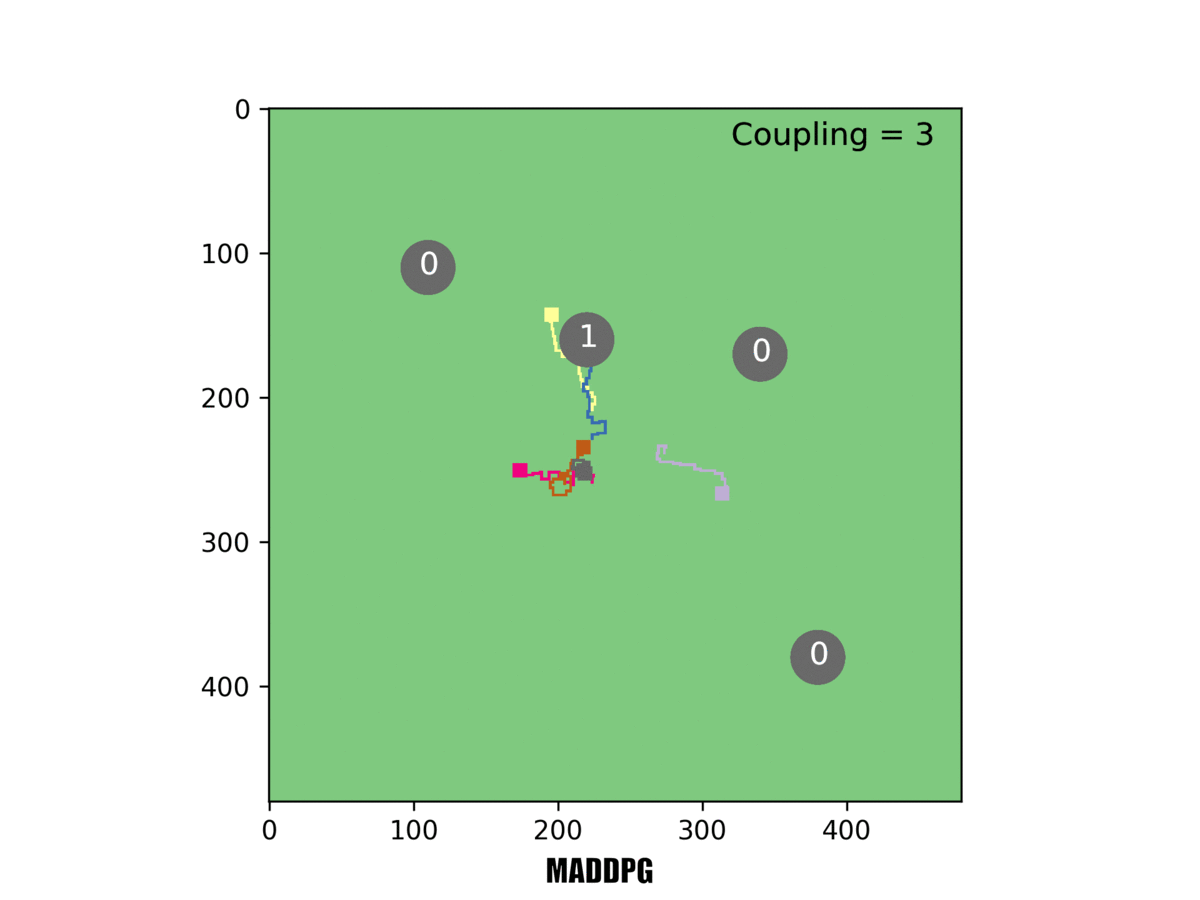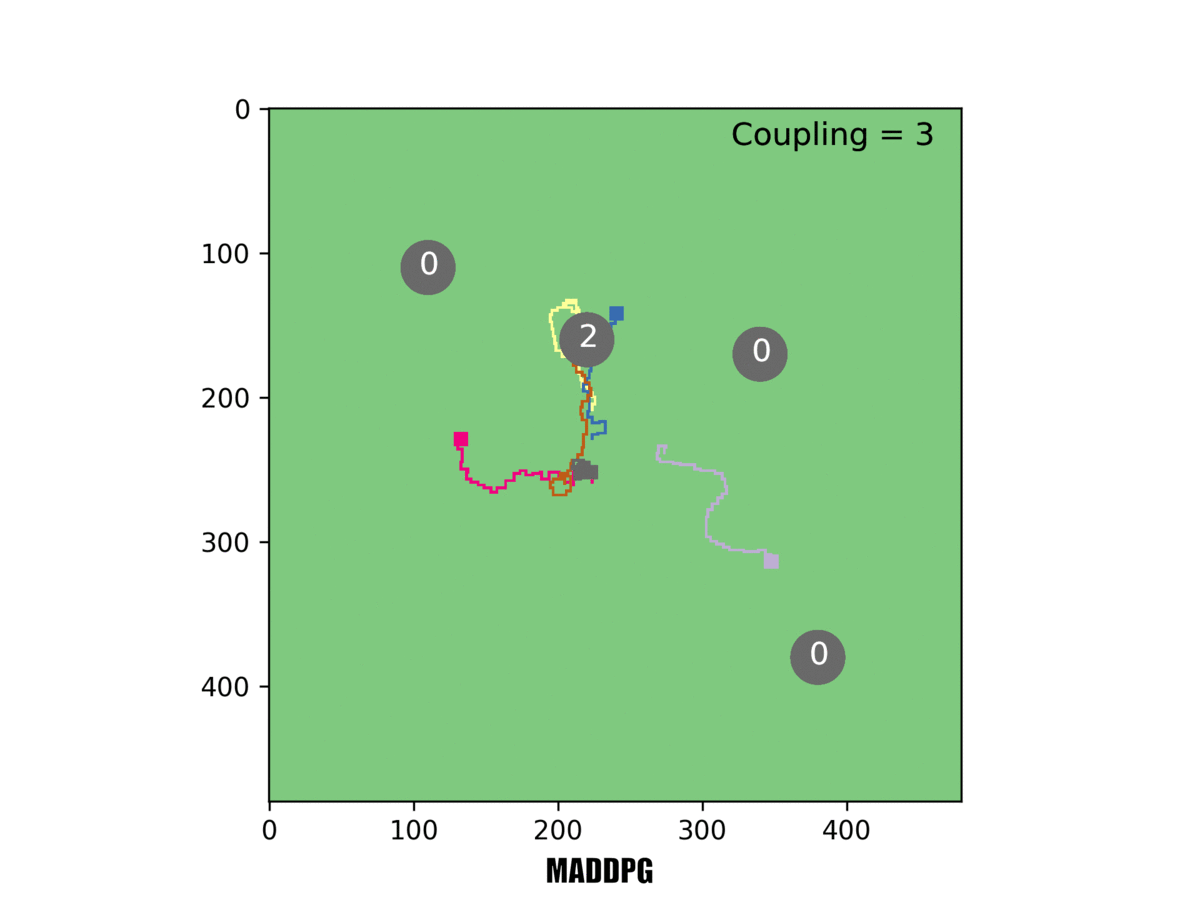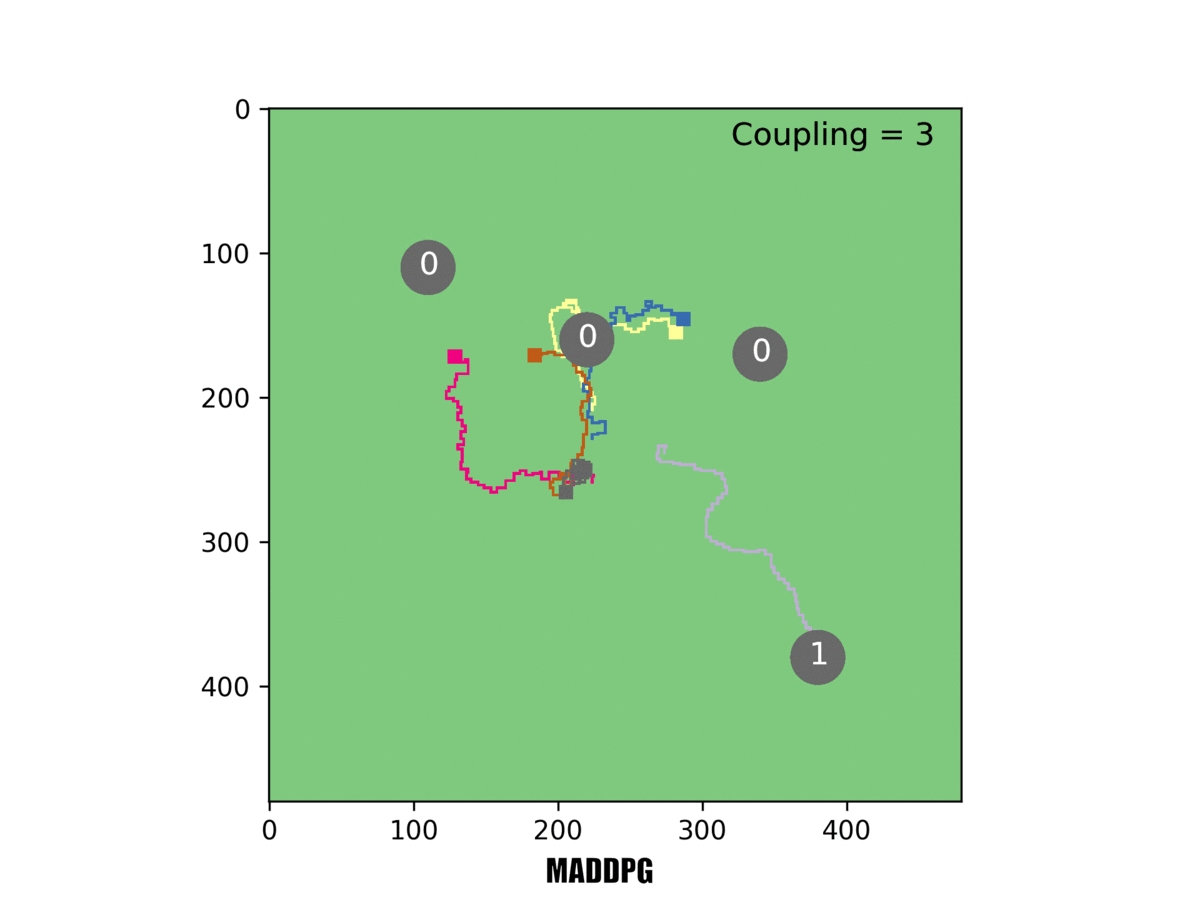
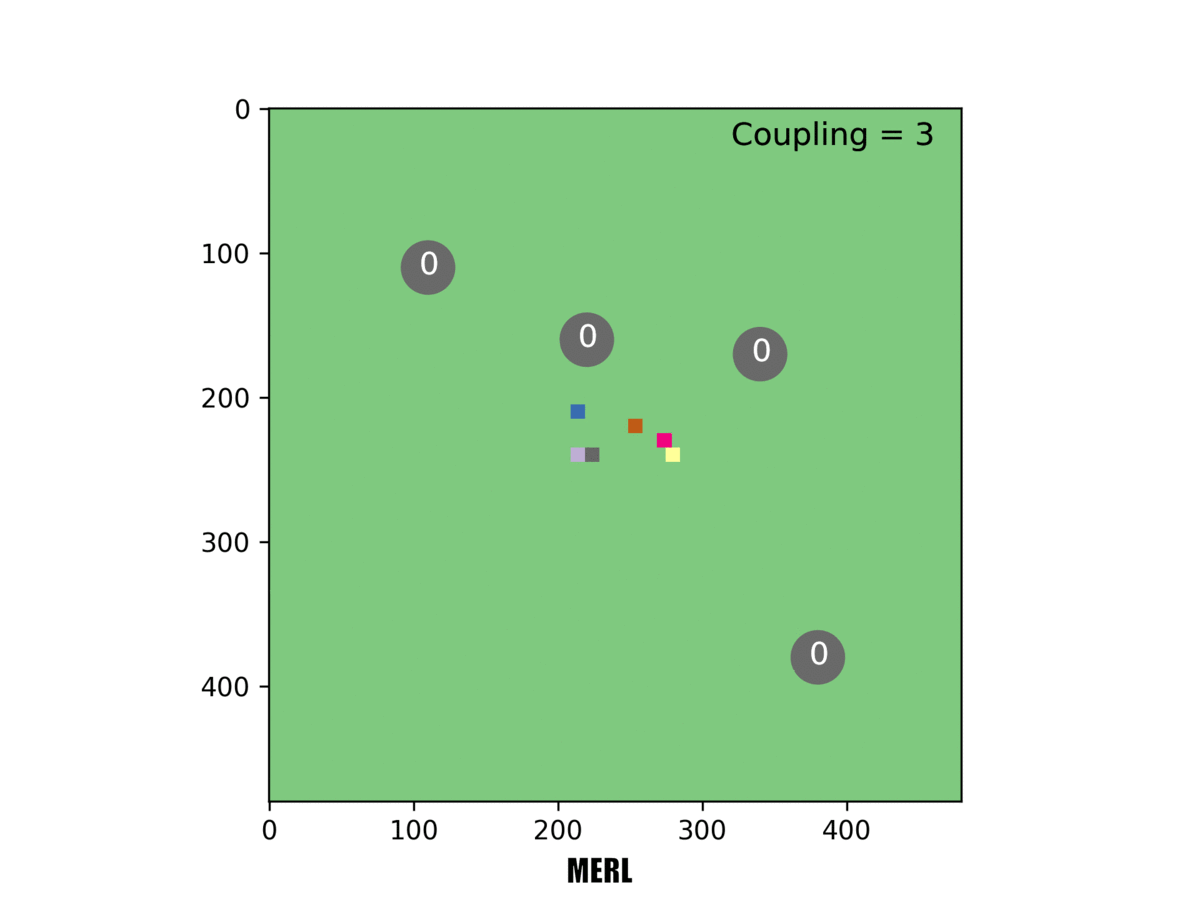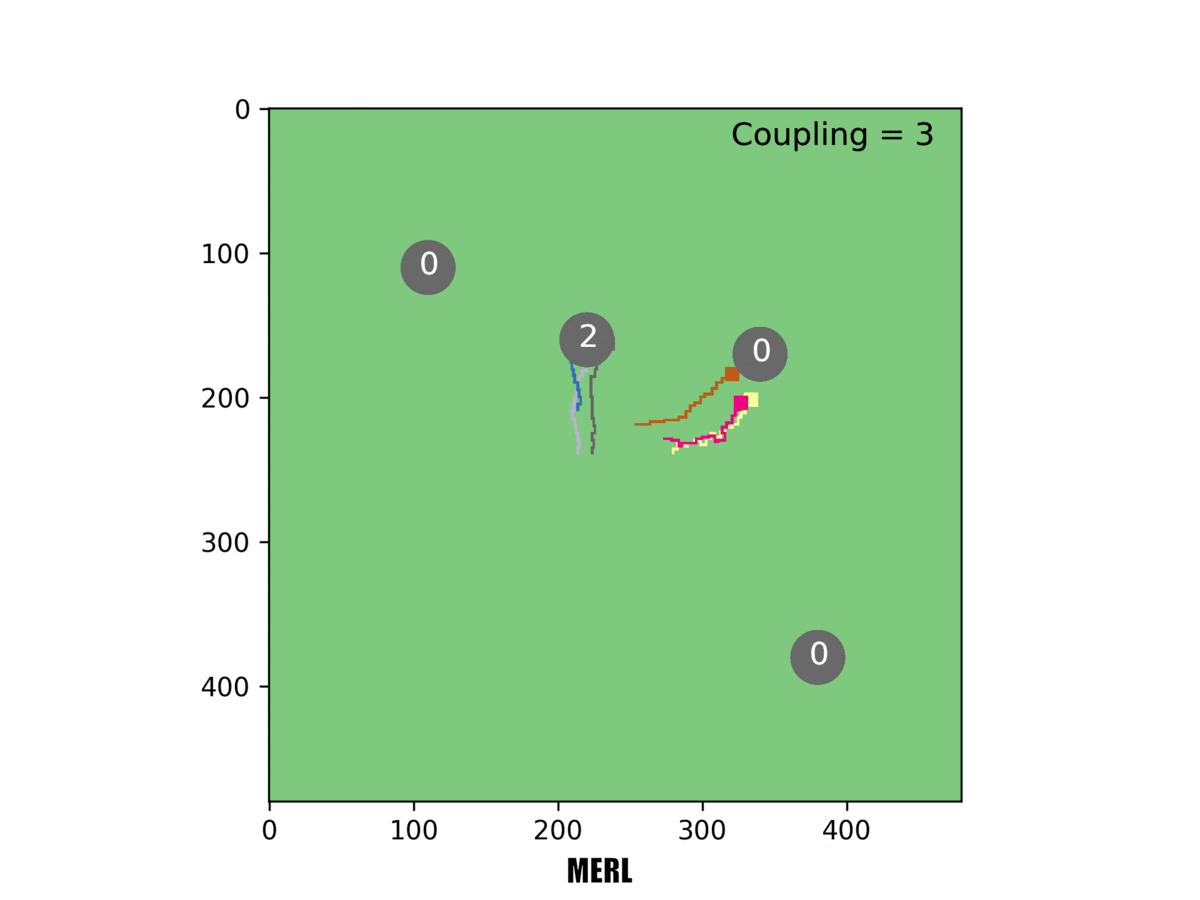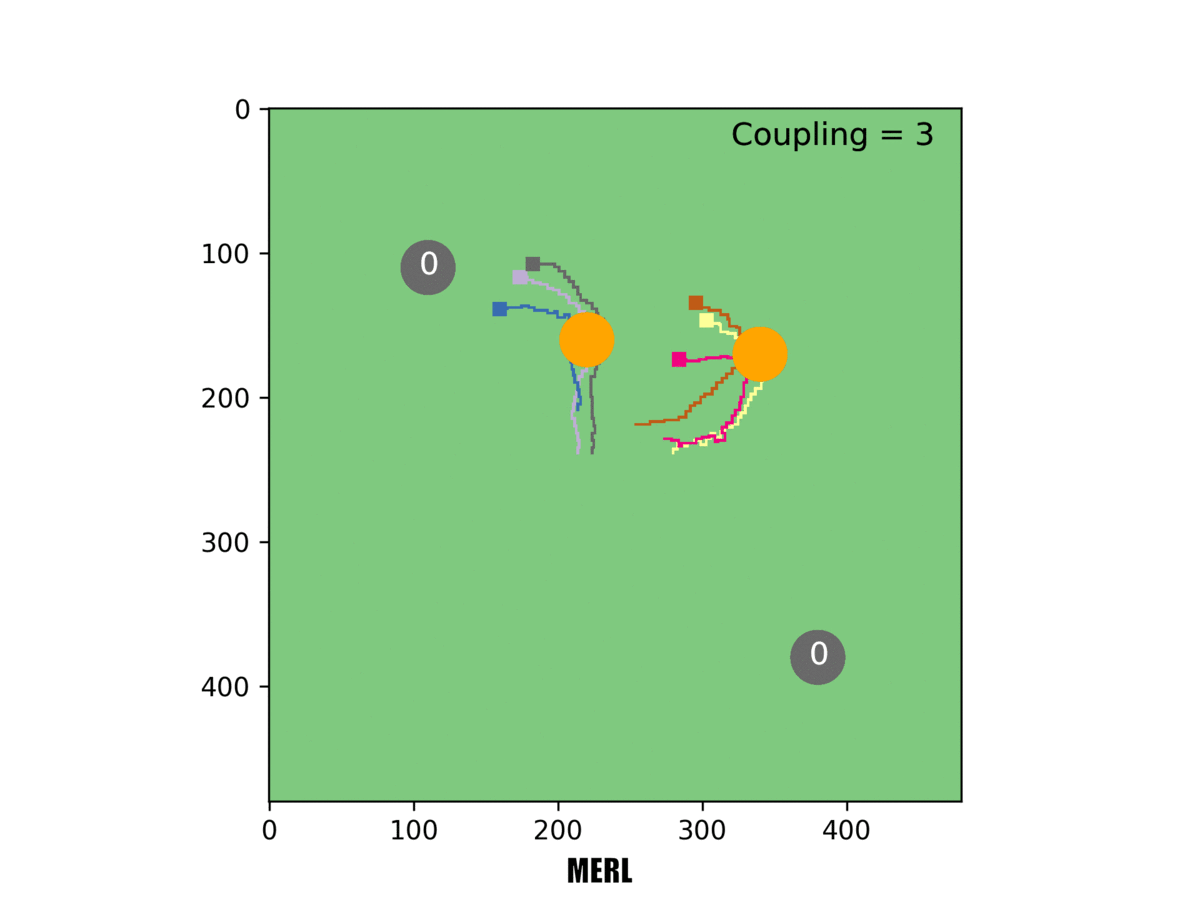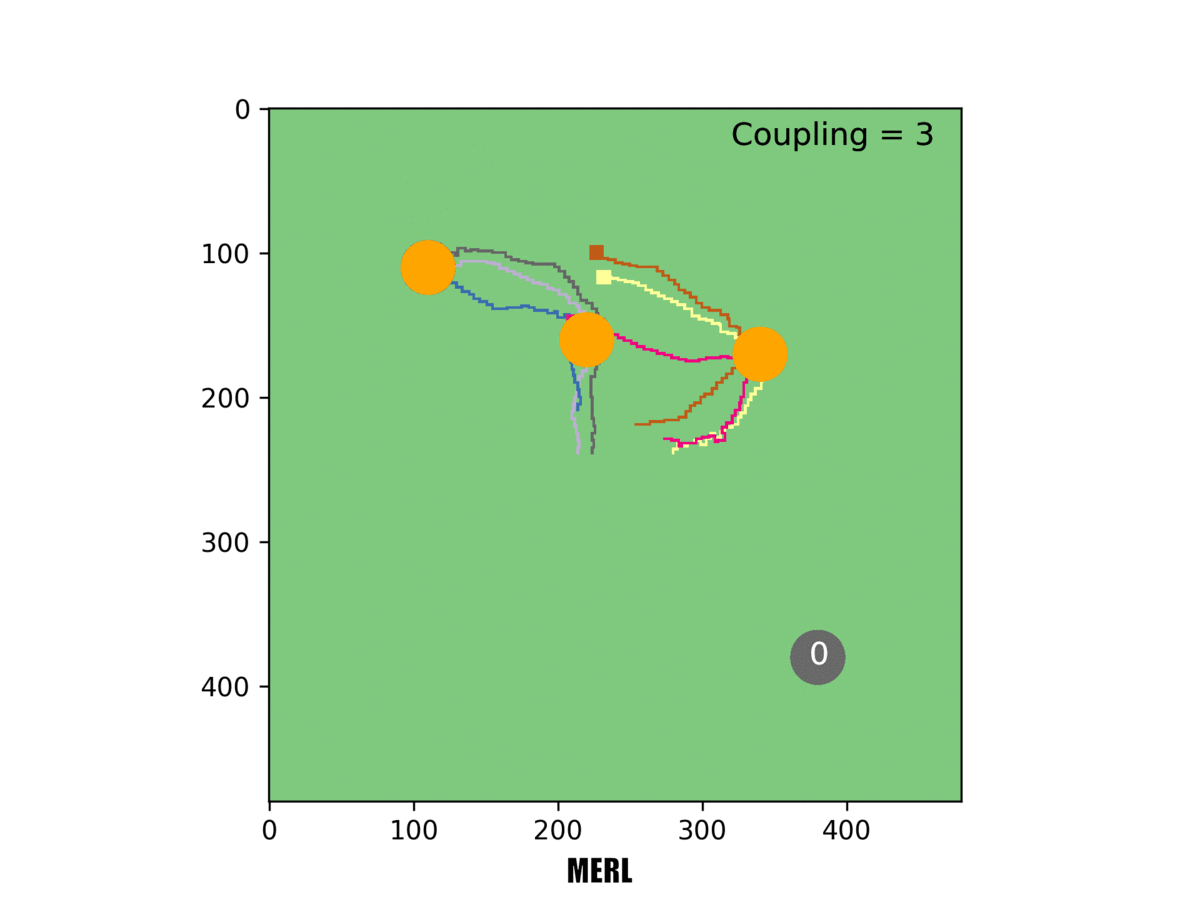
In this example, three rovers must reach a target for it to be counted. Our system [right] can handle this challenging task, but others failed at it.
Intel AI
When three rovers had to reach a target simultaneously, MADDPG completely failed and MERL's emergent team formation was even more obvious, a trend we increasingly observed as the required number of rovers mounted. We checked our work using several different multiagent benchmarks. In each case, the two-part optimization of MERL substantially outperformed existing state-of-the-art algorithms.
At Intel's AI lab, we're also exploring how communication could help multi-agent systems optimize performance. In particular, we're investigating whether agents on a team that are in communication with one another can form a language of sorts.
To give an example from the rover simulation: If we allowed each rover a limited bandwidth to communicate with the others, what kind of messages would it transmit? And would the rovers jointly come up with codewords for certain actions? This experiment could give us insight into how language develops to achieve a common goal.
Autonomous systems of many forms are now becoming part of everyday life. While your Roomba is unlikely to do much damage, even if it went haywire, a robotic truck driving down the highway erratically could kill people. So we need to ensure that any agent that's been trained via RL will operate safely in the real world. How to do that, though, isn't particularly clear.
We're exploring ways to define a common safety benchmark for various RL algorithms and a common framework which can be used to train RL agents to operate safely, regardless of the application. This is easier said than done, because an abstracted concept of safety is hard to define, and a task-specific definition of safety is hard to scale across tasks. It's important to figure out now how to get such systems to act safely, because we believe that RL systems have a big role to play in society. Today's AI excels at perception tasks such as object and speech recognition, but it's ill-suited to taking actions. For robots, self-driving cars, and other such autonomous systems, RL training will enable them to learn how to act in an environment with changing and unexpected conditions.
In one ongoing test of our theories, we're using RL combined with search algorithms to teach robots how to develop successful trajectories with minimal interaction with the real world. This technique could allow robots to try out new actions without the risk of damaging themselves in the process. We're now applying knowledge acquired in this way to an actual bipedal robot at Oregon State University.
Finally, in a leap from robotic systems to systems design, we have applied the same approach to improving various aspects of software and hardware systems. In a recent paper, we demonstrated that an RL agent can learn how to efficiently perform memory management on a hardware accelerator. Our approach, Evolutionary Graph RL, was able to almost double the speed of execution on hardware compared to the native compiler simply by efficiently allocating chunks of data to various memory components. This accomplishment and other recent works by the research community show that RL is moving from solving games to solving problems in real life.