Forget JPEG, How Would a Person Compress a Picture?

Picture your favorite photograph, say, of an outdoor party. What's in the picture that you care about most? Is it your friends who were present? Is it the food you were eating? Or is it the amazing sunset in the background that you didn't notice at the time you took the picture, but looks like a painting?
Now imagine which of those details you'd choose to keep if you only had enough storage space for one of those features, instead of the entire photo.
Why would I bother to do that, you ask? I can just send the whole picture to the cloud and keep it forever.
That, however, isn't really true. We live in an age in which it's cheap to take photos but will eventually be costly to store them en masse, as backup services set limits and begin charging for overages. And we love to share our photos, so we end up storing them in multiple places. Most users don't think about it, but every image posted to Facebook, Instagram or TikTok is compressed before it shows up on your feed or timeline. Computer algorithms are constantly making choices about what visual details matter, and, based on those choices, generating lower-quality images that take up less digital space.
These compressors aim to preserve certain visual properties while glossing over others, determining what visual information can be thrown away without being noticeable. State-of-the-art image compressors-like the ones resulting in the ubiquitous JPEG files that we all have floating around on our hard drives and shared albums in the cloud-can reduce image sizes between 5 and 100 times. But when we push the compression envelope further, artifacts emerge, including blurring, blockiness, and staircase-like bands.
Still, today's compressors provide pretty good savings in space with acceptable losses in quality. But, as engineers, we are trained to ask if we can do better. So we decided to take a step back from the standard image compression tools, and see if there is a path to better compression that, to date, hasn't been widely traveled.
We started our effort to improve image compression by considering the adage: "a picture is worth a thousand words." While that expression is intended to imply that a thousand words is a lot and an inefficient way to convey the information contained in a picture, to a computer, a thousand words isn't much data at all. In fact, a thousand digital words contain far fewer bits than any of the images we generate with our smartphones and sling around daily.
So, inspired by the aphorism, we decided to test whether it really takes about a thousand words to describe an image. Because if indeed it does, then perhaps it's possible to use the descriptive power of human language to compress images more efficiently than the algorithms used today, which work with brightness and color information at the pixel level rather than attempting to understand the contents of the image.
The key to this approach is figuring out what aspects of an image matter most to human viewers, that is, how much they actually care about the visual information that is thrown out. We believe that evaluating compression algorithms based on theoretical and non-intuitive quantities is like gauging the success of your new cookie recipe by measuring how much the cookie deviates from a perfect circle. Cookies are designed to taste delicious, so why measure quality based on something completely unrelated to taste?
It turns out that there is a much easier way to measure image compression quality-just ask some people what they think. By doing so, we found out that humans are pretty great image compressors, and machines have a long way to go.
Algorithms for lossy compression include equations called loss functions. These measure how closely the compressed image matches the original image. A loss function close to zero indicates that the compressed and original images are very similar. The goal of lossy image compressors is to discard irrelevant details in pursuit of maximum space savings while minimizing the loss function.
We found out that humans are pretty great image compressors, and machines have a long way to go.
Some loss functions center around abstract qualities of an image that don't necessarily relate to how a human views an image. One classic loss function, for example, involves comparing the original and the compressed images pixel-by-pixel, then adding up the squared differences in pixel values. That's certainly not how most people think about the differences between two photographs. Loss functions like this one that don't reflect the priorities of the human visual system tend to result in compressed images with obvious visual flaws.
Most image compressors do take some aspects of the human visual system into account. The JPEG algorithm exploits the fact that the human visual system prioritizes areas of uniform visual information over minor details. So it often degrades features like sharp edges. JPEG, like most other video and image compression algorithms, also preserves more intensity (brightness) information than it does color, since the human eye is much more sensitive to changes in light intensity than it is to minute differences in hues.
For decades, scientists and engineers have attempted to distill aspects of human visual perception into better ways of computing the loss function. Notable among these efforts are methods to quantify the impact of blockiness, contrast, flicker and the sharpness of edges on the quality of the result as perceived by the human eye. The developers of recent compressors like Google's Guetzli encoder, a JPEG compressor that runs far slower but produces smaller files than traditional JPEG tools, tout the fact that these algorithms consider crucial aspects of human visual perception such as the differences in how the eye perceives specific colors or patterns.
But these compressors still use loss functions that are mathematical at their heart, like the pixel-by-pixel sum of squares, which are then adjusted to include some aspects of human perception.
In pursuit of a more human-centric loss function, we set out to determine how much information it takes for a human to accurately describe an image. Then we considered how concise these descriptions can get, if the describer can tap into the large repository of images on the Internet that are open to the public. Such public image databases are under-utilized in image compression today.
Our hope was that, by pairing them with human visual priorities, we could come up with a whole new paradigm for image compression.
When it comes to developing an algorithm, relying on humans for inspiration is not unusual. Consider the field of language processing. In 1951, Claude Shannon-founder of the field of information theory-used humans to determine the variability of language in order to come to an estimate of its entropy. Knowing the entropy would enable researchers to determine how far the text compression algorithms are from the optimal theoretical performance. His setup was simple: he asked one human subject to select a sample of English text, and another to sequentially guess the contents of that sample. The first subject would provide the second with feedback about their guesses-confirmation for every correct guess, and either the correct letter or a prompt for another guess in the case of incorrect guesses, depending on the exact experiment.
With these experiments plus a lot of elegant mathematics, Shannon estimated the theoretically optimal performance of a system designed to compress English-language texts. Since then, other engineers have used experiments with humans to set standards for gauging the performance of artificial intelligence algorithms. Shannon's estimates also inspired the parameters of the Hutter Prize, a long-standing English text compression contest.
We created a similarly human-based scheme that we hope will also inspire ambitious future applications. (This project was a collaboration between our lab at Stanford and three local high schoolers who were interning with the lab; its success inspired us to launch a full-fledged high school summer internship program at Stanford, called STEM to SHTEM, where the "H" stands for the humanities and the human element.)
Our setup used two human subjects, like Shannon's. But instead of selecting text passages, the first subject, dubbed the "describer," selected a photograph. The second test subject, the "reconstructor," attempted to recreate the photograph using only the describer's descriptions of the photograph and image editing software.
 In tests of human image compression, the describer sent text messages to the resconstructor, to which the reconstructor could reply by voice. These messages could include references to images found on public websites.Ashutosh Bhown, Irena Hwang, Soham Mukherjee, and Sean Yang
In tests of human image compression, the describer sent text messages to the resconstructor, to which the reconstructor could reply by voice. These messages could include references to images found on public websites.Ashutosh Bhown, Irena Hwang, Soham Mukherjee, and Sean Yang
In our tests, the describers used text-based messaging and, crucially, could include links to any publicly available image on the internet. This allowed the reconstructors to start with a similar image and edit it, rather than forcing them to create an image from scratch. We used video-conferencing software that allowed the reconstructors to react orally and share their screens with the describers, so the describers could follow the process of reconstruction in real time.
Limiting the describers to text messaging-and allowing links to image databases-helped us measure the amount of information it took to accurately convey the contents of an image given access to related images. In order to ensure that the description and reconstruction exercise wasn't trivially easy, the describers started with original photographs that are not available publicly.
The process of image reconstruction-involving image editing on the part of the reconstructor and text-based commands and links from the describer-proceeded until the describer deemed the reconstruction satisfactory. In many cases, this took an hour or less, in some, depending on the availability of like images on the Internet and the familiarity of the reconstructor with Photoshop, it took all day.
We then processed the text transcript and compressed it using a typical text compressor. Because that transcript contains all the information that the reconstructor needed to satisfactorily recreate the image for the describer, we could consider it to be the compressed representation of the original image.
Our next step involved determining how much other people agreed that the image reconstructions based on these compressed text transcripts were accurate representations of the original images. To do this, we crowdsourced via Amazon's Mechanical Turk (MTurk) platform. We uploaded 13 human-reconstructed images side-by-side with the original images and asked Turk workers (Turkers) to rate the reconstructions on a scale of 1-completely unsatisfied-to 10-completely satisfied.
Such a scale is admittedly vague, but we left it vague by design. Our goal was to measure how much people liked the images produced by our reconstruction scheme, without constraining "likeability" by definitions.
 In this reconstruction of the compressed images of a sketch (left), the human compression system (center) did much better than the WebP algorithm (right), in terms of both compression ratio and score, as determined by MTurk worker ratings.Ashutosh Bhown, Irena Hwang, Soham Mukherjee, and Sean Yang
In this reconstruction of the compressed images of a sketch (left), the human compression system (center) did much better than the WebP algorithm (right), in terms of both compression ratio and score, as determined by MTurk worker ratings.Ashutosh Bhown, Irena Hwang, Soham Mukherjee, and Sean Yang
Given our unorthodox setup for performing image reconstruction-the use of humans, video chat software, enormous image databases, and reliance on internet search engine capabilities to search said databases-it's nearly impossible to directly compare the reconstructions from our scheme to any existing image compression software. Instead, we decided to compare how well a machine can do with an amount of information comparable to that generated by our describers. We used one of the best available lossy image compressors, WebP, to compress the describer's original images down to file sizes equivalent to the describer's compressed text transcripts. Because even the lowest quality level allowed by WebP created compressed image files larger than our humans did, we had to reduce the image resolution and then compress it using WebP's minimum quality level.
We then uploaded the same set of original and WebP compressed images on MTurk.
The verdict? The Turkers generally preferred the images produced using our human compression scheme. In most cases, the humans beat the WebP compressor, for some images, by a lot. For a reconstruction of a sketch of the wolf, the Turkers gave the humans a mean rating of more than eight, compared with one of less than four for WebP. When it came to reconstructing the human face, WebP had a significant edge, with a mean rating of 5.47 to 2.95, and slightly beat the human reconstructions in two other cases.
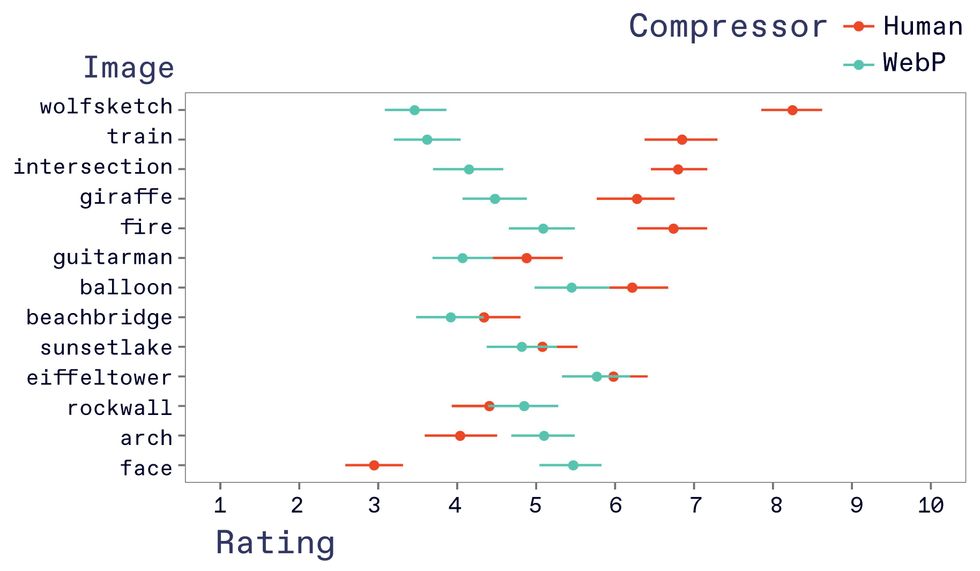 In tests of human compression vs the WebP compression algorithm at equivalent file sizes, the human reconstruction was generally rated higher by a panel of MTurk workers, with some notable exceptionsJudith Fan
In tests of human compression vs the WebP compression algorithm at equivalent file sizes, the human reconstruction was generally rated higher by a panel of MTurk workers, with some notable exceptionsJudith Fan
This is good news, because our scheme resulted in extraordinarily large compression ratios. Our human compressors condensed the original images, which all clocked in around a few megabytes, down to only a few thousand bytes each, a compression ratio of some 1000-fold. This file size turned out to be surprisingly close-within the same order of magnitude-to the proverbial thousand words that pictures supposedly contain.
The reconstructions also provided valuable insight about the important visual priorities of humans. Consider one of our sample images, a safari scene featuring two majestic giraffes. The human reconstruction retained almost all discernible details (albeit somewhat lacking in botanical accuracy): individual trees just behind the giraffes, a row of low-lying shrubbery in the distance, individual blades of parched grass. This scored very highly among the Turkers compared to WebP compression. The latter resulted in a blurred scene in which it was hard to tell where the trees ended and the animals began. This example demonstrates that when it comes to complex images with numerous elements, what matters to humans is that all of the semantic details of an image are still present after compression-never mind their precise positioning or color shade.
The human reconstructors did best on images involving elements for which similar images were widely available, including landmarks and monuments as well as more mundane scenes, like traffic intersections. The success of these reconstructions emphasizes the power of using a comprehensive public image database during compression. Given the existing body of public images, plus user-provided images via social networking services, it is conceivable that a compression scheme that taps into public image databases could outperform today's pixel-centric compressors.
Our human compression system did worst on an up-close, portrait photograph of the describer's close friend. The describer tried to communicate details like clothing type (hoodie sweatshirt), hair (curly and brown) and other notable facial features (a typical case of adolescent acne). Despite these details, the Turkers judged the reconstruction to be severely lacking, for the very simple reason that the person in the reconstruction was undeniably not the person in the original photo.
 Human image compressors fell short when working with human faces. Here, the WebP algorithm's reconstruction (right) is clearly more successful than the human attempt (center) Ashutosh Bhown, Irena Hwang, Soham Mukherjee, and Sean Yang
Human image compressors fell short when working with human faces. Here, the WebP algorithm's reconstruction (right) is clearly more successful than the human attempt (center) Ashutosh Bhown, Irena Hwang, Soham Mukherjee, and Sean Yang
What was easy for a human to perceive in this case was hard to break into discrete, describable components. Was it not the same person because the friend's jaw was more angular? Because his mouth curved up more at the edges? The answer is some combination of all of these reasons and more, some ineffable quality that humans struggle to verbalize.
It's worth pointing out that, for our tests, we used high schoolers for the tasks of description and reconstruction, not trained experts. If these experiments were performed, for example, with experts at image description working in cultural accessibility for people with low or no vision and paired with expert artists, they would likely have much better results. That is, this strategy has far more potential than we were able to demonstrate.
Of course, our human-to-human compression setup isn't anything like a computer algorithm. The key feature of modern compression algorithms, which our scheme sorely lacks, is reproducibility: every time you shove the same image into the type of compressor that can be found on most computers, you can be absolutely sure that you'll get the exact same compressed result.
We are not envisioning a commercial compressor that involves sets of humans around the world discussing images. Rather, a practical implementation of our compression scheme would likely be made up of various artificial intelligence techniques.
One potential replacement for the human describer and reconstructor pair is something called a generative adversarial network (GAN). A GAN is a fascinating blend of two neural networks: one that attempts to generate a realistic image ("generator") and another that attempts to distinguish between real and fake images ("discriminator"). GANs have been used in recent years to accomplish a variety of tasks: transmuting zebras into horses, re-rendering photographs a la the most popular Impressionist styles, and even generating phony celebrities.
Our human compressors condensed the original images, which all clocked in around a few megabytes, down to only a few thousand bytes each.
A GAN similarly designed to create images using a stunningly low number of bits could easily automate the task of breaking down an input image into different features and objects, then compress them according to their relative importance, possibly utilizing similar images. And a GAN-based algorithm would be perfectly reproducible, fulfilling the basic requirement of compression algorithms.
Another key component of our human-centric scheme that would need to be automated is, ironically, human judgment. Although the MTurk platform can be useful for small experiments, engineering a robust compression algorithm that includes an appropriate loss function would require not only a vast number of responses, but also consistent ones that agree on the same definition of image quality. As paradoxical as it seems, AI in the form of neural networks able to predict human scores could provide a far more efficient and reliable representation of human judgment here, compared to the opinions of a horde of Turkers.
We believe that the future of image compression lies in the hybridization of human and machine. Such mosaic algorithms with human-inspired priorities and robotic efficiency are already being seen in a wide array of other fields. For decades, learning from nature has pushed forward the entire field of biomimetics, resulting in robots that locomote as animals do and uncanny military or emergency rescue robots that almost-but not quite-look like man's best friend. Human computer interface research, in particular, has long taken cues from humans, leveraging crowdsourcing to create more conversational AI.
It is time that similar partnerships between man and machine worked to improve image compression. We think, that with our experiments, we moved the goalposts for image compression beyond what was assumed to be possible, giving a glimpse of the astronomical performance that image compressors might attain if we rethink the pixel-centric approach of the compressors we have today. And then we truly might be able to say that a picture is worth a thousand words.
The authors would like to acknowledge Ashutosh Bhown, Soham Mukherjee, Sean Yang, and Judith Fan, who also contributed to this research.