Deep Learning Could Bring the Concert Experience Home

Now that recorded sound has become ubiquitous, we hardly think about it. From our smartphones, smart speakers, TVs, radios, disc players, and car sound systems, it's an enduring and enjoyable presence in our lives. In 2017, a survey by the polling firm Nielsen suggested that some 90 percent of the U.S. population listens to music regularly and that, on average, they do so 32 hours per week.
Behind this free-flowing pleasure are enormous industries applying technology to the long-standing goal of reproducing sound with the greatest possible realism. From Edison's phonograph and the horn speakers of the 1880s, successive generations of engineers in pursuit of this ideal invented and exploited countless technologies: triode vacuum tubes, dynamic loudspeakers, magnetic phonograph cartridges, solid-state amplifier circuits in scores of different topologies, electrostatic speakers, optical discs, stereo, and surround sound. And over the past five decades, digital technologies, like audio compression and streaming, have transformed the music industry.
And yet even now, after 150 years of development, the sound we hear from even a high-end audio system falls far short of what we hear when we are physically present at a live music performance. At such an event, we are in a natural sound field and can readily perceive that the sounds of different instruments come from different locations, even when the sound field is criss-crossed with mixed sound from multiple instruments. There's a reason why people pay considerable sums to hear live music: It is more enjoyable, exciting, and can generate a bigger emotional impact.
To hear the author's 3D Soundstage audio for yourself, grab your headphones and head over to 3dsoundstage.com/ieee.
Today, researchers, companies, and entrepreneurs, including ourselves, are closing in at last on recorded audio that truly re-creates a natural sound field. The group includes big companies, such as Apple and Sony, as well as smaller firms, such as Creative. Netflix recently disclosed a partnership with Sennheiser under which the network has begun using a new system, Ambeo 2-Channel Spatial Audio, to heighten the sonic realism of such TV shows as Stranger Things" and The Witcher."
There are now at least half a dozen different approaches to producing highly realistic audio. We use the term soundstage" to distinguish our work from other audio formats, such as the ones referred to as spatial audio or immersive audio. These can represent sound with more spatial effect than ordinary stereo, but they do not typically include the detailed sound-source location cues that are needed to reproduce a truly convincing sound field.
We believe that soundstage is the future of music recording and reproduction. But before such a sweeping revolution can occur, it will be necessary to overcome an enormous obstacle: that of conveniently and inexpensively converting the countless hours of existing recordings, regardless of whether they're mono, stereo, or multichannel surround sound (5.1, 7.1, and so on). No one knows exactly how many songs have been recorded, but according to the entertainment-metadata concern Gracenote, more than 200 million recorded songs are available now on planet Earth. Given that the average duration of a song is about 3 minutes, this is the equivalent of about 1,100 years of music.
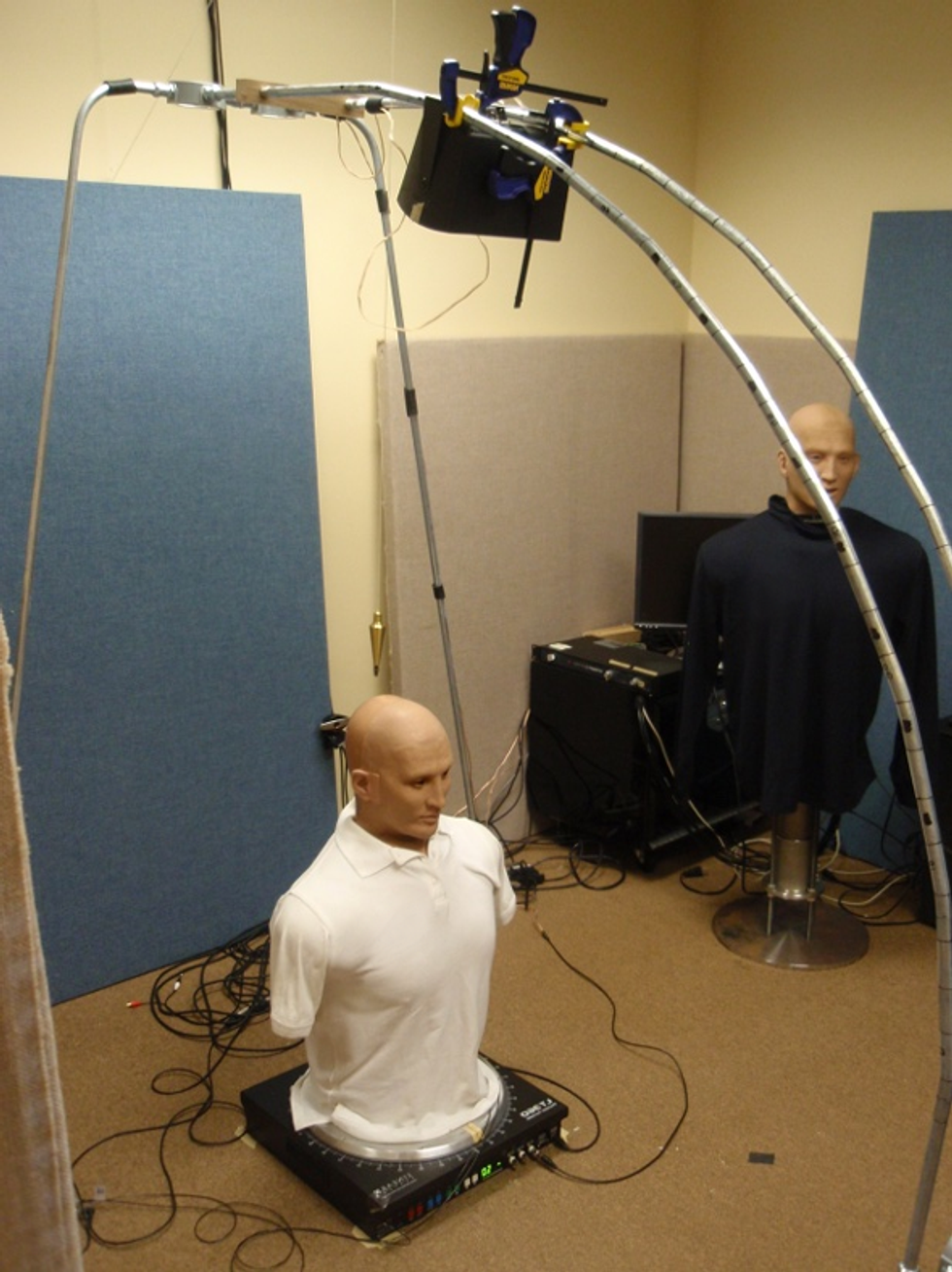
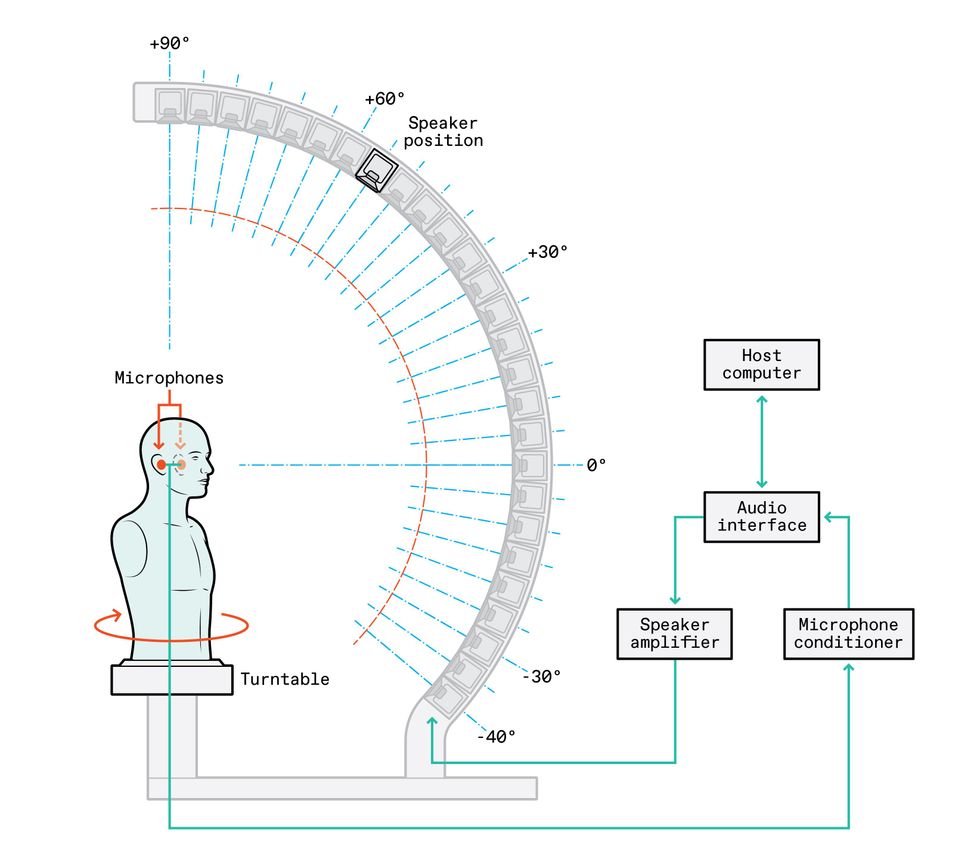
Measuring a Head-Related Transfer FunctionTo provide a high degree of spatial realism for a listener, you need to precisely map the details of how that listener's unique head shape, ears, and nasal cavity affect how he or she hears sound. This is done by determining the listener's head-related transfer function, which is accomplished by playing sounds from a variety of angles and recording how the user's head affects the sounds at each position.
That is a lot of music. Any attempt to popularize a new audio format, no matter how promising, is doomed to fail unless it includes technology that makes it possible for us to listen to all this existing audio with the same ease and convenience with which we now enjoy stereo music-in our homes, at the beach, on a train, or in a car.
We have developed such a technology. Our system, which we call 3D Soundstage, permits music playback in soundstage on smartphones, ordinary or smart speakers, headphones, earphones, laptops, TVs, soundbars, and in vehicles. Not only can it convert mono and stereo recordings to soundstage, it also allows a listener with no special training to reconfigure a sound field according to their own preference, using a graphical user interface. For example, a listener can assign the locations of each instrument and vocal sound source and adjust the volume of each-changing the relative volume of, say, vocals in comparison with the instrumental accompaniment. The system does this by leveraging artificial intelligence (AI), virtual reality, and digital signal processing (more on that shortly).
To re-create convincingly the sound coming from, say, a string quartet in two small speakers, such as the ones available in a pair of headphones, requires a great deal of technical finesse. To understand how this is done, let's start with the way we perceive sound.
When sound travels to your ears, unique characteristics of your head-its physical shape, the shape of your outer and inner ears, even the shape of your nasal cavities-change the audio spectrum of the original sound. Also, there is a very slight difference in the arrival time from a sound source to your two ears. From this spectral change and the time difference, your brain perceives the location of the sound source. The spectral changes and time difference can be modeled mathematically as head-related transfer functions (HRTFs). For each point in three-dimensional space around your head, there is a pair of HRTFs, one for your left ear and the other for the right.
So, given a piece of audio, we can process that audio using a pair of HRTFs, one for the right ear, and one for the left. To re-create the original experience, we would need to take into account the location of the sound sources relative to the microphones that recorded them. If we then played that processed audio back, for example through a pair of headphones, the listener would hear the audio with the original cues, and perceive that the sound is coming from the directions from which it was originally recorded.
If we don't have the original location information, we can simply assign locations for the individual sound sources and get essentially the same experience. The listener is unlikely to notice minor shifts in performer placement-indeed, they might prefer their own configuration.
Even now, after 150 years of development, the sound we hear from even a high-end audio system falls far short of what we hear when we are physically present at a live music performance.
There are many commercial apps that use HRTFs to create spatial sound for listeners using headphones and earphones. One example is Apple's Spatialize Stereo. This technology applies HRTFs to playback audio so you can perceive a spatial sound effect-a deeper sound field that is more realistic than ordinary stereo. Apple also offers a head-tracker version that uses sensors on the iPhone and AirPods to track the relative direction between your head, as indicated by the AirPods in your ears, and your iPhone. It then applies the HRTFs associated with the direction of your iPhone to generate spatial sounds, so you perceive that the sound is coming from your iPhone. This isn't what we would call soundstage audio, because instrument sounds are still mixed together. You can't perceive that, for example, the violin player is to the left of the viola player.
Apple does, however, have a product that attempts to provide soundstage audio: Apple Spatial Audio. It is a significant improvement over ordinary stereo, but it still has a couple of difficulties, in our view. One, it incorporates Dolby Atmos, a surround-sound technology developed by Dolby Laboratories. Spatial Audio applies a set of HRTFs to create spatial audio for headphones and earphones. However, the use of Dolby Atmos means that all existing stereophonic music would have to be remastered for this technology. Remastering the millions of songs already recorded in mono and stereo would be basically impossible. Another problem with Spatial Audio is that it can only support headphones or earphones, not speakers, so it has no benefit for people who tend to listen to music in their homes and cars.
So how does our system achieve realistic soundstage audio? We start by using machine-learning software to separate the audio into multiple isolated tracks, each representing one instrument or singer or one group of instruments or singers. This separation process is called upmixing. A producer or even a listener with no special training can then recombine the multiple tracks to re-create and personalize a desired sound field.
Consider a song featuring a quartet consisting of guitar, bass, drums, and vocals. The listener can decide where to locate" the performers and can adjust the volume of each, according to his or her personal preference. Using a touch screen, the listener can virtually arrange the sound-source locations and the listener's position in the sound field, to achieve a pleasing configuration. The graphical user interface displays a shape representing the stage, upon which are overlaid icons indicating the sound sources-vocals, drums, bass, guitars, and so on. There is a head icon at the center, indicating the listener's position. The listener can touch and drag the head icon around to change the sound field according to their own preference.
Moving the head icon closer to the drums makes the sound of the drums more prominent. If the listener moves the head icon onto an icon representing an instrument or a singer, the listener will hear that performer as a solo. The point is that by allowing the listener to reconfigure the sound field, 3D Soundstage adds new dimensions (if you'll pardon the pun) to the enjoyment of music.
The converted soundstage audio can be in two channels, if it is meant to be heard through headphones or an ordinary left- and right-channel system. Or it can be multichannel, if it is destined for playback on a multiple-speaker system. In this latter case, a soundstage audio field can be created by two, four, or more speakers. The number of distinct sound sources in the re-created sound field can even be greater than the number of speakers.
An Audio Taxonomy
For a listener seeking a high degree of spatial realism, a variety of audio formats and systems are now available for enjoyment through speakers or headphones. On the low end, ordinary mono and stereo recordings provide a minimal spatial-perceptual experience. In the middle range, multichannel recordings, such as 5.1 and 7.1 surround sound, offer somewhat higher levels of spatial realism. At the highest levels are audio systems that start with the individual, separated instrumental tracks of a recording and recombine them, using audio techniques and tools such as head-related transfer functions, to provide a highly realistic spatial experience.
This multichannel approach should not be confused with ordinary 5.1 and 7.1 surround sound. These typically have five or seven separate channels and a speaker for each, plus a subwoofer (the .1"). The multiple loudspeakers create a sound field that is more immersive than a standard two-speaker stereo setup, but they still fall short of the realism possible with a true soundstage recording. When played through such a multichannel setup, our 3D Soundstage recordings bypass the 5.1, 7.1, or any other special audio formats, including multitrack audio-compression standards.
A word about these standards. In order to better handle the data for improved surround-sound and immersive-audio applications, new standards have been developed recently. These include the MPEG-H 3D audio standard for immersive spatial audio with Spatial Audio Object Coding (SAOC). These new standards succeed various multichannel audio formats and their corresponding coding algorithms, such as Dolby Digital AC-3 and DTS, which were developed decades ago.
While developing the new standards, the experts had to take into account many different requirements and desired features. People want to interact with the music, for example by altering the relative volumes of different instrument groups. They want to stream different kinds of multimedia, over different kinds of networks, and through different speaker configurations. SAOC was designed with these features in mind, allowing audio files to be efficiently stored and transported, while preserving the possibility for a listener to adjust the mix based on their personal taste.
To do so, however, it depends on a variety of standardized coding techniques. To create the files, SAOC uses an encoder. The inputs to the encoder are data files containing sound tracks; each track is a file representing one or more instruments. The encoder essentially compresses the data files, using standardized techniques. During playback, a decoder in your audio system decodes the files, which are then converted back to the multichannel analog sound signals by digital-to-analog converters.
Our 3D Soundstage technology bypasses this. We use mono or stereo or multichannel audio data files as input. We separate those files or data streams into multiple tracks of isolated sound sources, and then convert those tracks to two-channel or multichannel output, based on the listener's preferred configurations, to drive headphones or multiple loudspeakers. We use AI technology to avoid multitrack rerecording, encoding, and decoding.
In fact, one of the biggest technical challenges we faced in creating the 3D Soundstage system was writing that machine-learning software that separates (or upmixes) a conventional mono, stereo, or multichannel recording into multiple isolated tracks in real time. The software runs on a neural network. We developed this approach for music separation in 2012 and described it in patents that were awarded in 2022 and 2015 (the U.S. patent numbers are 11,240,621 B2 and 9,131,305 B2).
The listener can decide where to locate" the performers and can adjust the volume of each, according to his or her personal preference.
A typical session has two components: training and upmixing. In the training session, a large collection of mixed songs, along with their isolated instrument and vocal tracks, are used as the input and target output, respectively, for the neural network. The training uses machine learning to optimize the neural-network parameters so that the output of the neural network-the collection of individual tracks of isolated instrument and vocal data-matches the target output.
A neural network is very loosely modeled on the brain. It has an input layer of nodes, which represent biological neurons, and then many intermediate layers, called hidden layers." Finally, after the hidden layers there is an output layer, where the final results emerge. In our system, the data fed to the input nodes is the data of a mixed audio track. As this data proceeds through layers of hidden nodes, each node performs computations that produce a sum of weighted values. Then a nonlinear mathematical operation is performed on this sum. This calculation determines whether and how the audio data from that node is passed on to the nodes in the next layer.
There are dozens of these layers. As the audio data goes from layer to layer, the individual instruments are gradually separated from one another. At the end, in the output layer, each separated audio track is output on a node in the output layer.
That's the idea, anyway. While the neural network is being trained, the output may be off the mark. It might not be an isolated instrumental track-it might contain audio elements of two instruments, for example. In that case, the individual weights in the weighting scheme used to determine how the data passes from hidden node to hidden node are tweaked and the training is run again. This iterative training and tweaking goes on until the output matches, more or less perfectly, the target output.
As with any training data set for machine learning, the greater the number of available training samples, the more effective the training will ultimately be. In our case, we needed tens of thousands of songs and their separated instrumental tracks for training; thus, the total training music data sets were in the thousands of hours.
After the neural network is trained, given a song with mixed sounds as input, the system outputs the multiple separated tracks by running them through the neural network using the system established during training.
Unmixing Audio With a Neural Network
After separating a recording into its component tracks, the next step is to remix them into a soundstage recording. This is accomplished by a soundstage signal processor. This soundstage processor performs a complex computational function to generate the output signals that drive the speakers and produce the soundstage audio. The inputs to the generator include the isolated tracks, the physical locations of the speakers, and the desired locations of the listener and sound sources in the re-created sound field. The outputs of the soundstage processor are multitrack signals, one for each channel, to drive the multiple speakers.
The sound field can be in a physical space, if it is generated by speakers, or in a virtual space, if it is generated by headphones or earphones. The function performed within the soundstage processor is based on computational acoustics and psychoacoustics, and it takes into account sound-wave propagation and interference in the desired sound field and the HRTFs for the listener and the desired sound field.
For example, if the listener is going to use earphones, the generator selects a set of HRTFs based on the configuration of desired sound-source locations, then uses the selected HRTFs to filter the isolated sound-source tracks. Finally, the soundstage processor combines all the HRTF outputs to generate the left and right tracks for earphones. If the music is going to be played back on speakers, at least two are needed, but the more speakers, the better the sound field. The number of sound sources in the re-created sound field can be more or less than the number of speakers.
We released our first soundstage app, for the iPhone, in 2020. It lets listeners configure, listen to, and save soundstage music in real time-the processing causes no discernible time delay. The app, called 3D Musica, converts stereo music from a listener's personal music library, the cloud, or even streaming music to soundstage in real time. (For karaoke, the app can remove vocals, or output any isolated instrument.)
Earlier this year, we opened a Web portal, 3dsoundstage.com, that provides all the features of the 3D Musica app in the cloud plus an application programming interface (API) making the features available to streaming music providers and even to users of any popular Web browser. Anyone can now listen to music in soundstage audio on essentially any device.
When sound travels to your ears, unique characteristics of your head-its physical shape, the shape of your outer and inner ears, even the shape of your nasal cavities-change the audio spectrum of the original sound.
We also developed separate versions of the 3D Soundstage software for vehicles and home audio systems and devices to re-create a 3D sound field using two, four, or more speakers. Beyond music playback, we have high hopes for this technology in videoconferencing. Many of us have had the fatiguing experience of attending videoconferences in which we had trouble hearing other participants clearly or being confused about who was speaking. With soundstage, the audio can be configured so that each person is heard coming from a distinct location in a virtual room. Or the location" can simply be assigned depending on the person's position in the grid typical of Zoom and other videoconferencing applications. For some, at least, videoconferencing will be less fatiguing and speech will be more intelligible.
Just as audio moved from mono to stereo, and from stereo to surround and spatial audio, it is now starting to move to soundstage. In those earlier eras, audiophiles evaluated a sound system by its fidelity, based on such parameters as bandwidth, harmonic distortion, data resolution, response time, lossless or lossy data compression, and other signal-related factors. Now, soundstage can be added as another dimension to sound fidelity-and, we dare say, the most fundamental one. To human ears, the impact of soundstage, with its spatial cues and gripping immediacy, is much more significant than incremental improvements in fidelity. This extraordinary feature offers capabilities previously beyond the experience of even the most deep-pocketed audiophiles.
Technology has fueled previous revolutions in the audio industry, and it is now launching another one. Artificial intelligence, virtual reality, and digital signal processing are tapping in to psychoacoustics to give audio enthusiasts capabilities they've never had. At the same time, these technologies are giving recording companies and artists new tools that will breathe new life into old recordings and open up new avenues for creativity. At last, the century-old goal of convincingly re-creating the sounds of the concert hall has been achieved.