Researchers Use AI to Generate Images Based on People's Brain Activity
What if an AI could interpret your imagination, turning images in your mind's eye into reality? While that sounds like a detail in a cyberpunk novel, researchers have now accomplished exactly this, according to a recently-published paper.
Researchers found that they could reconstruct high-resolution and highly accurate images from brain activity by using the popular Stable Diffusion image generation model, as outlined in a paper published in December. The authors wrote that unlike previous studies, they didn't need to train or fine-tune the AI models to create these images.
The researchers-from the Graduate School of Frontier Biosciences at Osaka University-said that they first predicted a latent representation, which is a model of the image's data, from fMRI signals. Then, the model was processed and noise was added to it through the diffusion process. Finally, the researchers decoded text representations from fMRI signals within the higher visual cortex and used them as input to produce a final constructed image.
 Screenshot from paper
Screenshot from paper The researchers wrote that a few studies have produced high-resolution reconstructions of images but it was only after training and fine-tuning generative models. This resulted in limitations because training complex models are challenging and there are not many samples in neuroscience to work with. Prior to this new study, no other researchers had tried using diffusion models for visual reconstruction.
This study was a peek into the internal processes of diffusion models, the researchers concluded, saying that the study was the first to provide a quantitative interpretation of the model from a biological perspective. For example, there is a diagram that the researchers created showing the correlation between stimuli and noise levels in the brain. The higher-level the stimuli, the higher-level the noise level would be, and the higher resolution the image would be. In another diagram, the researchers show the engagement of different neural networks in the brain and how it would de-noise an image to reconstruct it.
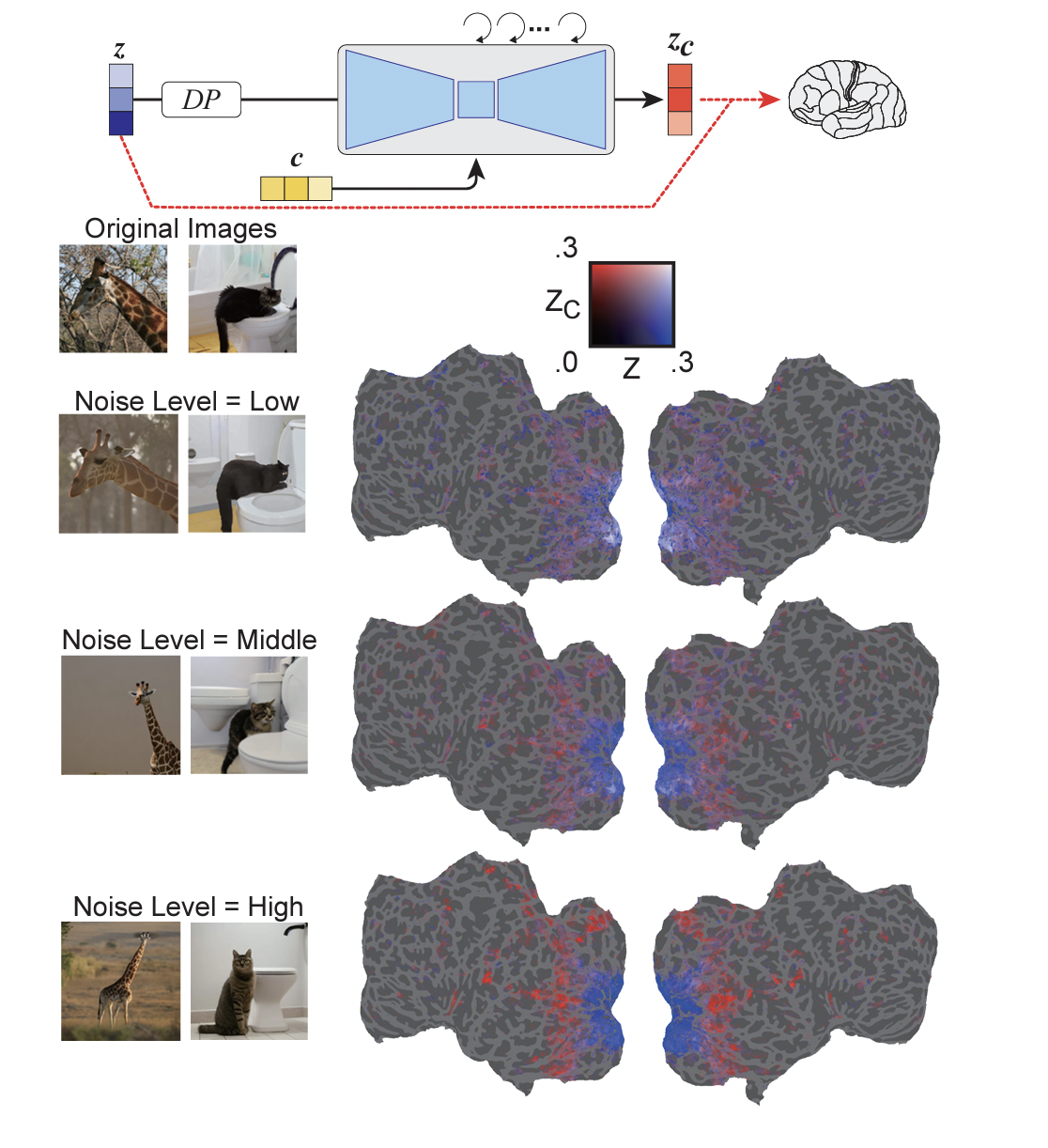 Screenshot from paper
Screenshot from paper These results suggest that, at the beginning of the reverse diffusion process, image information is compressed within the bottleneck layer. As denoising progresses, a functional dissociation among U-Net layers emerges within visual cortex: i.e., the first layer tends to represent fine-scale details in early visual areas, while the bottleneck layer corresponds to higher-order information in more ventral, semantic areas," the researchers wrote.
In the past, we've seen other examples of how brainwaves and brain functions can create images. In 2014, a Shanghai-based artist Jody Xiong used EEG biosensors to connect sixteen people with disabilities to balloons of paint. The people would then use their thoughts to burst specific balloons and create their own paintings. In another EEG example, artist Lia Chavez created an installation that allowed the electrical impulses in the brain to create sounds and light works. Audiences would wear EEG headsets, which would transfer the signals to an A/V system, where the brainwaves would be reflected through color and sound.
With the advancement of generative AI, more and more researchers have been testing the ways AI models can work with the human brain. In a January 2022 study, researchers at Radboud University in the Netherlands trained a generative AI network, a predecessor of Stable Diffusion, on fMRI data from 1,050 unique faces and convert the brain imaging results into actual images. The study found that the AI was able to perform unparalleled stimulus reconstruction. In the latest study released in December, the researchers revealed that current diffusion models can now achieve high-resolution visual reconstruction.