The Global Project to Make a General Robotic Brain

The generative AI revolution embodied in tools like ChatGPT, Midjourney, and many others is at its core based on a simple formula: Take a very large neural network, train it on a huge dataset scraped from the Web, and then use it to fulfill a broad range of user requests. Large language models (LLMs) can answer questions, write code, and spout poetry, while image-generating systems can create convincing cave paintings or contemporary art.
So why haven't these amazing AI capabilities translated into the kinds of helpful and broadly useful robots we've seen in science fiction? Where are the robots that can clean off the table, fold your laundry, and make you breakfast?
Unfortunately, the highly successful generative AI formula-big models trained on lots of Internet-sourced data-doesn't easily carry over into robotics, because the Internet is not full of robotic-interaction data in the same way that it's full of text and images. Robots need robot data to learn from, and this data is typically created slowly and tediously by researchers in laboratory environments for very specific tasks. Despite tremendous progress on robot-learning algorithms, without abundant data we still can't enable robots to perform real-world tasks (like making breakfast) outside the lab. The most impressive results typically only work in a single laboratory, on a single robot, and often involve only a handful of behaviors.
If the abilities of each robot are limited by the time and effort it takes to manually teach it to perform a new task, what if we were to pool together the experiences of many robots, so a new robot could learn from all of them at once? We decided to give it a try. In 2023, our labs at Google and the University of California, Berkeley came together with 32 other robotics laboratories in North America, Europe, and Asia to undertake the RT-X project, with the goal of assembling data, resources, and code to make general-purpose robots a reality.
Here is what we learned from the first phase of this effort.
How to create a generalist robotHumans are far better at this kind of learning. Our brains can, with a little practice, handle what are essentially changes to our body plan, which happens when we pick up a tool, ride a bicycle, or get in a car. That is, our embodiment" changes, but our brains adapt. RT-X is aiming for something similar in robots: to enable a single deep neural network to control many different types of robots, a capability called cross-embodiment. The question is whether a deep neural network trained on data from a sufficiently large number of different robots can learn to drive" all of them-even robots with very different appearances, physical properties, and capabilities. If so, this approach could potentially unlock the power of large datasets for robotic learning.
The scale of this project is very large because it has to be. The RT-X dataset currently contains nearly a million robotic trials for 22 types of robots, including many of the most commonly used robotic arms on the market. The robots in this dataset perform a huge range of behaviors, including picking and placing objects, assembly, and specialized tasks like cable routing. In total, there are about 500 different skills and interactions with thousands of different objects. It's the largest open-source dataset of real robotic actions in existence.
Surprisingly, we found that our multirobot data could be used with relatively simple machine-learning methods, provided that we follow the recipe of using large neural-network models with large datasets. Leveraging the same kinds of models used in current LLMs like ChatGPT, we were able to train robot-control algorithms that do not require any special features for cross-embodiment. Much like a person can drive a car or ride a bicycle using the same brain, a model trained on the RT-X dataset can simply recognize what kind of robot it's controlling from what it sees in the robot's own camera observations. If the robot's camera sees a UR10 industrial arm, the model sends commands appropriate to a UR10. If the model instead sees a low-cost WidowX hobbyist arm, the model moves it accordingly.
To test the capabilities of our model, five of the laboratories involved in the RT-X collaboration each tested it in a head-to-head comparison against the best control system they had developed independently for their own robot. Each lab's test involved the tasks it was using for its own research, which included things like picking up and moving objects, opening doors, and routing cables through clips. Remarkably, the single unified model provided improved performance over each laboratory's own best method, succeeding at the tasks about 50 percent more often on average.
While this result might seem surprising, we found that the RT-X controller could leverage the diverse experiences of other robots to improve robustness in different settings. Even within the same laboratory, every time a robot attempts a task, it finds itself in a slightly different situation, and so drawing on the experiences of other robots in other situations helped the RT-X controller with natural variability and edge cases. Here are a few examples of the range of these tasks:


 Building robots that can reason
Building robots that can reasonEncouraged by our success with combining data from many robot types, we next sought to investigate how such data can be incorporated into a system with more in-depth reasoning capabilities. Complex semantic reasoning is hard to learn from robot data alone. While the robot data can provide a range of physical capabilities, more complex tasks like Move apple between can and orange" also require understanding the semantic relationships between objects in an image, basic common sense, and other symbolic knowledge that is not directly related to the robot's physical capabilities.
So we decided to add another massive source of data to the mix: Internet-scale image and text data. We used an existing large vision-language model that is already proficient at many tasks that require some understanding of the connection between natural language and images. The model is similar to the ones available to the public such as ChatGPT or Bard. These models are trained to output text in response to prompts containing images, allowing them to solve problems such as visual question-answering, captioning, and other open-ended visual understanding tasks. We discovered that such models can be adapted to robotic control simply by training them to also output robot actions in response to prompts framed as robotic commands (such as Put the banana on the plate"). We applied this approach to the robotics data from the RT-X collaboration.
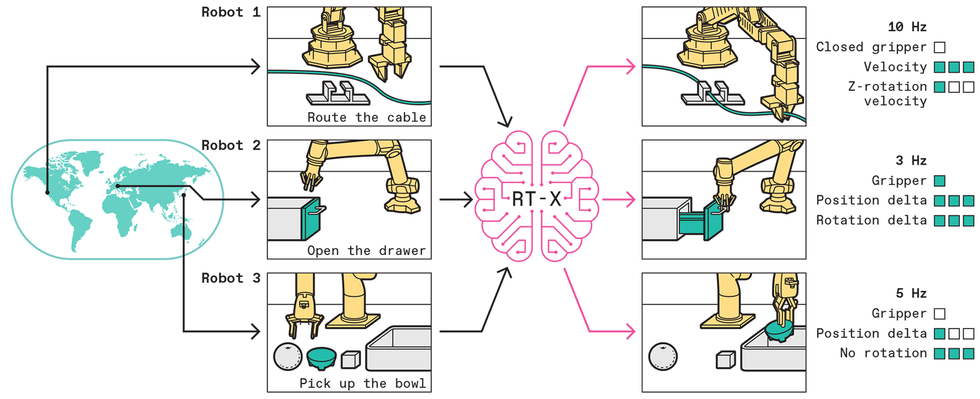 The RT-X model uses images or text descriptions of specific robot arms doing different tasks to output a series of discrete actions that will allow any robot arm to do those tasks. By collecting data from many robots doing many tasks from robotics labs around the world, we are building an open-source dataset that can be used to teach robots to be generally useful.Chris Philpot
The RT-X model uses images or text descriptions of specific robot arms doing different tasks to output a series of discrete actions that will allow any robot arm to do those tasks. By collecting data from many robots doing many tasks from robotics labs around the world, we are building an open-source dataset that can be used to teach robots to be generally useful.Chris Philpot
To evaluate the combination of Internet-acquired smarts and multirobot data, we tested our RT-X model with Google's mobile manipulator robot. We gave it our hardest generalization benchmark tests. The robot had to recognize objects and successfully manipulate them, and it also had to respond to complex text commands by making logical inferences that required integrating information from both text and images. The latter is one of the things that make humans such good generalists. Could we give our robots at least a hint of such capabilities?
We conducted two sets of evaluations. As a baseline, we used a model that excluded all of the generalized multirobot RT-X data that didn't involve Google's robot. Google's robot-specific dataset is in fact the largest part of the RT-X dataset, with over 100,000 demonstrations, so the question of whether all the other multirobot data would actually help in this case was very much open. Then we tried again with all that multirobot data included.
In one of the most difficult evaluation scenarios, the Google robot needed to accomplish a task that involved reasoning about spatial relations (Move apple between can and orange"); in another task it had to solve rudimentary math problems (Place an object on top of a paper with the solution to 2+3'"). These challenges were meant to test the crucial capabilities of reasoning and drawing conclusions.
In this case, the reasoning capabilities (such as the meaning of between" and on top of") came from the Web-scale data included in the training of the vision-language model, while the ability to ground the reasoning outputs in robotic behaviors-commands that actually moved the robot arm in the right direction-came from training on cross-embodiment robot data from RT-X. An example of an evaluation where we asked the robot to perform a task not included in its training data is shown in the video below.
Even without specific training, this Google research robot is able to follow the instruction move apple between can and orange." This capability is enabled by RT-X, a large robotic manipulation dataset and the first step towards a general robotic brain.
While these tasks are rudimentary for humans, they present a major challenge for general-purpose robots. Without robotic demonstration data that clearly illustrates concepts like between," near," and on top of," even a system trained on data from many different robots would not be able to figure out what these commands mean. By integrating Web-scale knowledge from the vision-language model, our complete system was able to solve such tasks, deriving the semantic concepts (in this case, spatial relations) from Internet-scale training, and the physical behaviors (picking up and moving objects) from multirobot RT-X data. To our surprise, we found that the inclusion of the multirobot data improved the Google robot's ability to generalize to such tasks by a factor of three. This result suggests that not only was the multirobot RT-X data useful for acquiring a variety of physical skills, it could also help to better connect such skills to the semantic and symbolic knowledge in vision-language models. These connections give the robot a degree of common sense, which could one day enable robots to understand the meaning of complex and nuanced user commands like Bring me my breakfast" while carrying out the actions to make it happen.
The RT-X project shows what is possible when the robot-learning community acts together. Because of this cross-institutional effort, we were able to put together a diverse robotic dataset and carry out comprehensive multirobot evaluations that wouldn't be possible at any single institution. Since the robotics community can't rely on scraping the Internet for training data, we need to create that data ourselves. We hope that more researchers will contribute their data to the RT-X database and join this collaborative effort. We also hope to provide tools, models, and infrastructure to support cross-embodiment research. We plan to go beyond sharing data across labs, and we hope that RT-X will grow into a collaborative effort to develop data standards, reusable models, and new techniques and algorithms.
Our early results hint at how large cross-embodiment robotics models could transform the field. Much as large language models have mastered a wide range of language-based tasks, in the future we might use the same foundation model as the basis for many real-world robotic tasks. Perhaps new robotic skills could be enabled by fine-tuning or even prompting a pretrained foundation model. In a similar way to how you can prompt ChatGPT to tell a story without first training it on that particular story, you could ask a robot to write Happy Birthday" on a cake without having to tell it how to use a piping bag or what handwritten text looks like. Of course, much more research is needed for these models to take on that kind of general capability, as our experiments have focused on single arms with two-finger grippers doing simple manipulation tasks.
As more labs engage in cross-embodiment research, we hope to further push the frontier on what is possible with a single neural network that can control many robots. These advances might include adding diverse simulated data from generated environments, handling robots with different numbers of arms or fingers, using different sensor suites (such as depth cameras and tactile sensing), and even combining manipulation and locomotion behaviors. RT-X has opened the door for such work, but the most exciting technical developments are still ahead.
This is just the beginning. We hope that with this first step, we can together create the future of robotics: where general robotic brains can power any robot, benefiting from data shared by all robots around the world.