What Is Generative AI?

Generative AI is today's buzziest form of artificial intelligence, and it's what powers chatbots like ChatGPT, Ernie, LLaMA, Claude, and Command-as well as image generators like DALL-E 2, Stable Diffusion, Adobe Firefly, and Midjourney. Generative AI is the branch of AI that enables machines to learn patterns from vast datasets and then to autonomously produce new content based on those patterns. Although generative AI is fairly new, there are already many examples of models that can produce text, images, videos, and audio.
Many foundation models" have been trained on enough data to be competent in a wide variety of tasks. For example, a large language model can generate essays, computer code, recipes, protein structures, jokes, medical diagnostic advice, and much more. It can also theoretically generate instructions for building a bomb or creating a bioweapon, though safeguards are supposed to prevent such types of misuse.
What's the difference between AI, machine learning, and generative AI?Artificial intelligence (AI) refers to a wide variety of computational approaches to mimicking human intelligence. Machine learning (ML) is a subset of AI; it focuses on algorithms that enable systems to learn from data and improve their performance. Before generative AI came along, most ML models learned from datasets to perform tasks such as classification or prediction. Generative AI is a specialized type of ML involving models that perform the task of generating new content, venturing into the realm of creativity.
What architectures do generative AI models use?Generative models are built using a variety of neural network architectures-essentially the design and structure that defines how the model is organized and how information flows through it. Some of the most well-known architectures are variational autoencoders (VAEs), generative adversarial networks (GANs), and transformers. It's the transformer architecture, first shown in this seminal 2017 paper from Google, that powers today's large language models. However, the transformer architecture is less suited for other types of generative AI, such as image and audio generation.
Autoencoders learn efficient representations of data through an encoder-decoder framework. The encoder compresses input data into a lower-dimensional space, known as the latent (or embedding) space, that preserves the most essential aspects of the data. A decoder can then use this compressed representation to reconstruct the original data. Once an autoencoder has been trained in this way, it can use novel inputs to generate what it considers the appropriate outputs. These models are often deployed in image-generation tools and have also found use in drug discovery, where they can be used to generate new molecules with desired properties.
With generative adversarial networks (GANs), the training involves a generator and a discriminator that can be considered adversaries. The generator strives to create realistic data, while the discriminator aims to distinguish between those generated outputs and real ground truth" outputs. Every time the discriminator catches a generated output, the generator uses that feedback to try to improve the quality of its outputs. But the discriminator also receives feedback on its performance. This adversarial interplay results in the refinement of both components, leading to the generation of increasingly authentic-seeming content. GANs are best known for creating deepfakes but can also be used for more benign forms of image generation and many other applications.
The transformer is arguably the reigning champion of generative AI architectures for its ubiquity in today's powerful large language models (LLMs). Its strength lies in its attention mechanism, which enables the model to focus on different parts of an input sequence while making predictions. In the case of language models, the input consists of strings of words that make up sentences, and the transformer predicts what words will come next (we'll get into the details below). In addition, transformers can process all the elements of a sequence in parallel rather than marching through it from beginning to end, as earlier types of models did; this parallelization makes training faster and more efficient. When developers added vast datasets of text for transformer models to learn from, today's remarkable chatbots emerged.
How do large language models work?A transformer-based LLM is trained by giving it a vast dataset of text to learn from. The attention mechanism comes into play as it processes sentences and looks for patterns. By looking at all the words in a sentence at once, it gradually begins to understand which words are most commonly found together and which words are most important to the meaning of the sentence. It learns these things by trying to predict the next word in a sentence and comparing its guess to the ground truth. Its errors act as feedback signals that cause the model to adjust the weights it assigns to various words before it tries again.
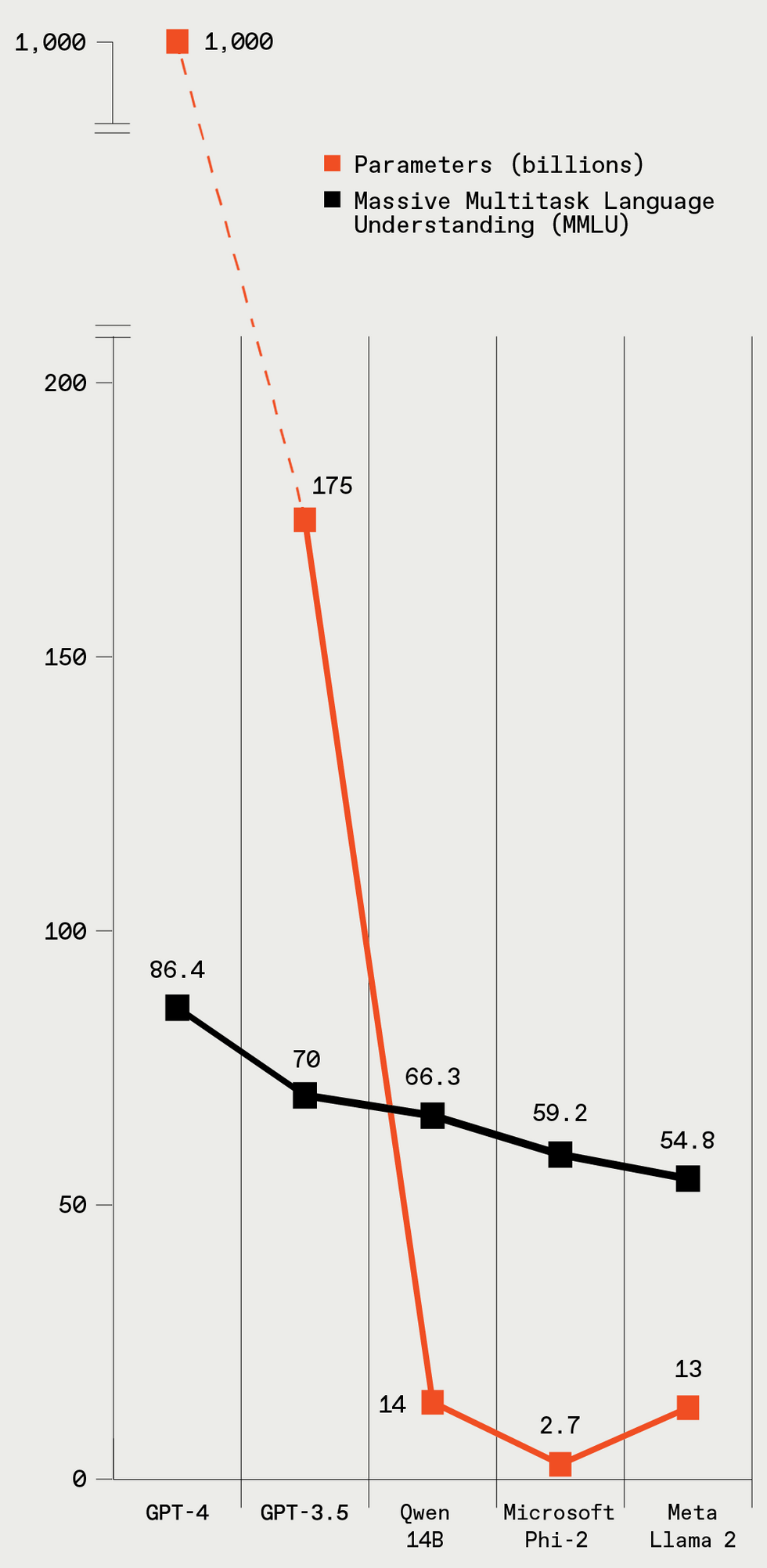 These five LLMs vary greatly in size (given in parameters), and the larger models have better performance on a standard LLM benchmark test. IEEE Spectrum
These five LLMs vary greatly in size (given in parameters), and the larger models have better performance on a standard LLM benchmark test. IEEE Spectrum
To explain the training process in slightly more technical terms, the text in the training data is broken down into elements called tokens, which are words or pieces of words-but for simplicity's sake, let's say all tokens are words. As the model goes through the sentences in its training data and learns the relationships between tokens, it creates a list of numbers, called a vector, for each one. All the numbers in the vector represent various aspects of the word: its semantic meanings, its relationship to other words, its frequency of use, and so on. Similar words, like elegant and fancy, will have similar vectors and will also be near each other in the vector space. These vectors are called word embeddings. The parameters of an LLM include the weights associated with all the word embeddings and the attention mechanism. GPT-4, the OpenAI model that's considered the current champion, is rumored to have more than 1 trillion parameters.
Given enough data and training time, the LLM begins to understand the subtleties of language. While much of the training involves looking at text sentence by sentence, the attention mechanism also captures relationships between words throughout a longer text sequence of many paragraphs. Once an LLM is trained and is ready for use, the attention mechanism is still in play. When the model is generating text in response to a prompt, it's using its predictive powers to decide what the next word should be. When generating longer pieces of text, it predicts the next word in the context of all the words it has written so far; this function increases the coherence and continuity of its writing.
Why do large language models hallucinate?You may have heard that LLMs sometimes hallucinate." That's a polite way to say they make stuff up very convincingly. A model sometimes generates text that fits the context and is grammatically correct, yet the material is erroneous or nonsensical. This bad habit stems from LLMs training on vast troves of data drawn from the Internet, plenty of which is not factually accurate. Since the model is simply trying to predict the next word in a sequence based on what it has seen, it may generate plausible-sounding text that has no grounding in reality.
Why is generative AI controversial?One source of controversy for generative AI is the provenance of its training data. Most AI companies that train large models to generate text, images, video, and audio have not been transparent about the content of their training datasets. Various leaks and experiments have revealed that those datasets include copyrighted material such as books, newspaper articles, and movies. A number of lawsuits are underway to determine whether use of copyrighted material for training AI systems constitutes fair use, or whether the AI companies need to pay the copyright holders for use of their material.
On a related note, many people are concerned that the widespread use of generative AI will take jobs away from creative humans who make art, music, written works, and so forth. People are also concerned that it could take jobs from humans who do a wide range of white-collar jobs, including translators, paralegals, customer-service representatives, and journalists. There have already been a few troubling layoffs, but it's hard to say yet whether generative AI will be reliable enough for large-scale enterprise applications. (See above about hallucinations.)
Finally, there's the danger that generative AI will be used to make bad stuff. And there are of course many categories of bad stuff it could theoretically be used for. Generative AI can be used for personalized scams and phishing attacks: For example, using voice cloning," scammers can copy the voice of a specific person and call the person's family with a plea for help (and money). All formats of generative AI-text, audio, image, and video-can be used to generate misinformation by creating plausible-seeming representations of things that never happened, which is a particularly worrying possibility when it comes to elections. (Meanwhile, as IEEE Spectrum reported this week, the U.S. Federal Communications Commission has responded by outlawing AI-generated robocalls.) Image- and video-generating tools can be used to produce nonconsensual pornography, although the tools made by mainstream companies disallow such use. And chatbots can theoretically walk a would-be terrorist through the steps of making a bomb, nerve gas, and a host of other horrors. Although the big LLMs have safeguards to prevent such misuse, some hackers delight in circumventing those safeguards. What's more, uncensored" versions of open-source LLMs are out there.
Despite such potential problems, many people think that generative AI can also make people more productive and could be used as a tool to enable entirely new forms of creativity. We'll likely see both disasters and creative flowerings and plenty else that we don't expect. But knowing the basics of how these models work is increasingly crucial for tech-savvy people today. Because no matter how sophisticated these systems grow, it's the humans' job to keep them running, make the next ones better, and with any luck, help people out too.