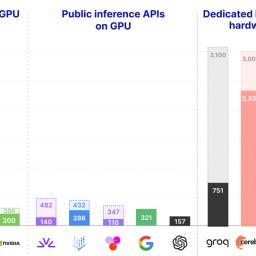
Real-time LLM Inference on Standard GPUs: 3k tokens/s per request from Hacker News on 2026-05-29 09:47 (#75YSG) Comments