 |
by Wiley on (#73VPT)
|
 IEEE Spectrum
IEEE Spectrum
| Link | https://spectrum.ieee.org/ |
| Feed | http://feeds.feedburner.com/IeeeSpectrum |
| Updated | 2026-07-28 08:00 |
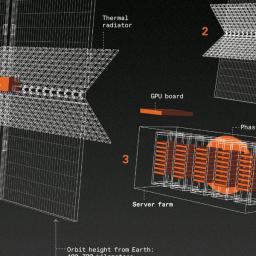 |
by Glenn Zorpette on (#73VPV)
|
 |
by Boston Micro Fabrication on (#73VHR)
|
 |
by Brian Jenney on (#73TZ8)
|
 |
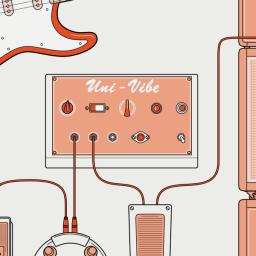
by Benjamin Skuse on (#73TVP)
|
 |
by Rohan S. Puranik on (#73TVQ)
|
 |
by Liz Wegerer on (#73T3H)
|
 |
by Samuel K. Moore on (#73SXS)
|
 |
by Dina Genkina on (#73RZ8)
|
by Johns Hopkins University on (#73RT1)
 |
by Waydell D. Carvalho on (#73RT2)
|
 |
by Paul Jones on (#73RA0)
|
 |
by Drew Robb on (#73QT8)
|
 |
by Kathy Pretz on (#73QC1)
|
 |
by Evan Ackerman on (#73QC2)
|
 |
by Vanessa Bates Ramirez on (#73PDV)
|
 |
by Angelique Parashis on (#73NPS)
|
 |
by Reza Ghodssi on (#73NHD)
|
 |
by Willie D. Jones on (#73MVW)
|
 |
by Arjun Sharma on (#73MGF)
|
 |
by Gwendolyn Rak on (#73KV6)
|
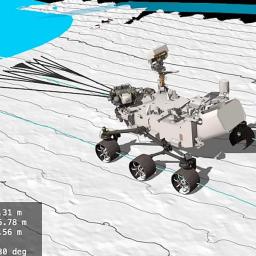 |
by Evan Gough on (#73K52)
|
 |
by Willie D. Jones on (#73JRB)
|
 |
by Robert Schneider on (#73J8S)
|
 |
by Evan Ackerman on (#73J8T)
|
 |
by Rahul Rao on (#73HA3)
|
 |
by Catherine Arnold on (#73H6C)
|
 |
by Joanna Goodrich on (#73GHG)
|
|
by Brian Jenney on (#73GHH)
|
 |
by Gwendolyn Rak on (#73G8J)
|
 |
by Gwendolyn Rak on (#73G8K)
|
 |
by Samuel K. Moore on (#73FF9)
|
 |
by Tanya Steinhauser on (#73ETK)
|
 |
by Rahul Rao on (#73EDP)
|
 |
by Samantha Hurley on (#73DB6)
|
 |
by Angelique Parashis on (#73CYH)
|
 |
by Evan Ackerman on (#73CW7)
|
 |
by Dina Genkina on (#73BVX)
|
 |
by Sheppard J. Salon on (#73B55)
|
 |
by Maurizio Arseni on (#73B56)
|
 |
by Remcom on (#73A6G)
|
 |
by Matthew Hutson on (#73A30)
|
 |
by Kathy Pretz on (#739H1)
|
 |
by John deVadoss on (#7398N)
|
 |
by Harry Goldstein on (#738H3)
|
 |
by Jason Hahr on (#7388B)
|
 |
by David Schneider on (#7387D)
|
 |
by Paul Jones on (#737X7)
|
by Paul McLaughlin on (#737X8)