PostgreSQL, the much-loved opensource relational database, is
ramping up its nosql game with a new developer kit that gives access to NoSQL features that beat MongoDB in benchmarks.
The PostgreSQL Project, which EnterpriseDB supports, added NoSQL-style JSON processing features back in 2012. Now, the company is encouraging further work around that feature set by providing a developer kit to make it easier for programmers to leverage PostgreSQL's JSON functions and build applications around them. ... The PGXDK (Postgres Extended Datatype Developer Kit) is designed to allow developers "to use Postgres for the kinds of applications that until recently required a specialized NoSQL-only solution," as EnterpriseDB describes it. A sample application is also included to make it easier for developers to get a leg up on working with the product. The whole package will be made available through AWS as a machine image (PostgreSQL has long been a staple Amazon offering).
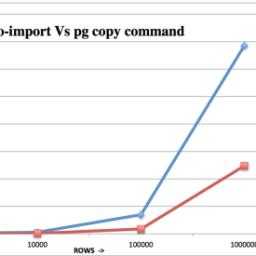
Vibhar Kumar has published a set of benchmarks here that show PostgreSQL eating MongoDB's lunch when measured in use of diskspace, bulk loading, and INSERTs.
Or just consider the cost of an extra server (with SSDs) versus the cost of hours of a DBA's time... For non-critical data in general, you're going to expand the cluster, rather than spend time and effort to tune things.