Myths About /dev/urandom
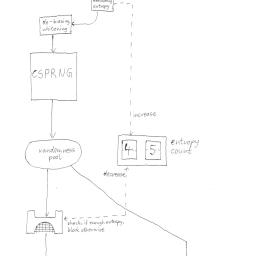 The differences between /dev/random and /dev/urandom have spawned some misconceptions. This article attempts to explain some of the myths surrounding this perplexing random number device.
The differences between /dev/random and /dev/urandom have spawned some misconceptions. This article attempts to explain some of the myths surrounding this perplexing random number device.Also of interest, is a report on weak entropy in key generation, especially during bootup, and another report on the aftermath of Debian's recent OpenSSL vulnerability.
Here's a concrete example I like to use:
Say you have a DRBG/PRNG that has the following algorithm: starting at num=1 emit byte streams from sha1hash(num). Then increment to the next number and repeat. The resulting output stream will be indecipherable from random noise because sha1 is cryptographically strong. But the seed material is incredibly weak. (The algorithm is not really an issue in this case because it's just a deterministic algo with a hash conditioning function.)