Myths About /dev/urandom
 The differences between /dev/random and /dev/urandom have spawned some misconceptions. This article attempts to explain some of the myths surrounding this perplexing random number device.
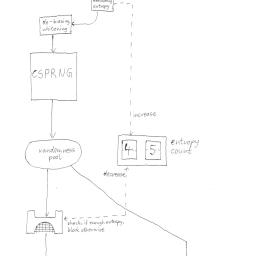
The differences between /dev/random and /dev/urandom have spawned some misconceptions. This article attempts to explain some of the myths surrounding this perplexing random number device.Also of interest, is a report on weak entropy in key generation, especially during bootup, and another report on the aftermath of Debian's recent OpenSSL vulnerability.
His whole article is riddled with "I believe" and "I don't think that's important". His pretty rough simplification is wrong. That's the argument I'm making. The pools are completely separate buffers. Berstein goes on to say in his post:
"I'm not saying that /dev/urandom has a perfect API. It's disappointingly
common for vendors to deploy devices where the randomness pool has never
been initialized; BSD /dev/urandom catches this configuration bug by
blocking, but Linux /dev/urandom (unlike Linux /dev/random) spews
predictable data, causing (e.g.) the widespread RSA security failures
documented on http://factorable.net. But fixing this configuration bug
has nothing to do with the /dev/random superstitions."
So using /dev/urandom may be all fine and dandy (I disagree but I've got time to wait for blocking 256 bits from /dev/random), unless it's not initialized or there is some other implementation problem. With the blocking source, at least you get some bits from source that are local and largely not reproducible (time between keyboard interrupts sampled possibly in the gigahertz), you're already ahead when you get through the hash function. So why not raise the bar when generating keys, if you're this concerned with security and have a high performance need for key generation there are solutions out there also.
tl;dr Blog author doesn't care about some of the theoretical attacks, they're too hard and other crypto will probably break first so why bother