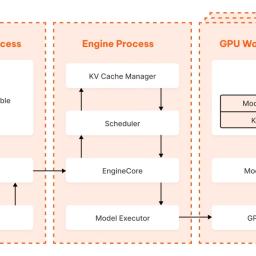
Life of an inference request (vLLM V1): How LLMs are served efficiently at scale from Hacker News on 2025-06-28 18:42 (#6Y9ZH) Comments