 |
by ericlippert on (#4DQHC)
[Code for this episode is here.] So far in this series we’ve very briefly looked at continuous distributions on doubles, and spent a lot of time looking at discrete distributions with small supports. Let’s take a look at a completely … Continue reading →
|
 Fabulous adventures in coding
Fabulous adventures in coding
| Link | https://ericlippert.com/ |
| Feed | http://ericlippert.com/feed |
| Updated | 2026-07-04 19:00 |
by ericlippert on (#4DBS5)
So… I’ve got good news and bad news. The good news is: I’ve described an interface for discrete probability distributions and implemented several distributions. I’ve shown how projecting a distribution is logically equivalent to the LINQ Select operator. I’ve shown … Continue reading →
by ericlippert on (#4D6F3)
[Code for this episode is here.] Last time in this series I left you with several challenges for improving our DSL for imperative probabilistic workflows. But first, a puzzle: Question One: You are walking down the street when you see … Continue reading →
by ericlippert on (#4D1KH)
I’m continuing my efforts to port over and update my old blog content. The previous episode is here. We’re still in the first few weeks of me blogging; I was pumping out articles at a rate I now consider to … Continue reading →
by ericlippert on (#4CYT8)
Last time in this series I proposed a stripped-down DSL for probabilistic workflows. Today, let’s see how we could “lower†it to ordinary C# 7 code. I’ll assume of course that we have all of the types and extension methods that … Continue reading →
by ericlippert on (#4CT26)
Thanks again to the good people at Microsoft who have kept my old blog alive for now; my plan is to port the articles from the old site over, and then they will redirect from the old URLs to the … Continue reading →
by ericlippert on (#4CQ6T)
Without further ado, here’s my proposed stripped-down C# that could be a DSL for probabilistic workflows; as we’ll see, it is quite similar to both enumerator blocks from C# 2 and async/await from C# 5. (Code for this episode can … Continue reading →
by ericlippert on (#4CFN9)
I’ve got no code for you this time; instead here are some musings about language design informed by our discussion so far. One of the most important questions to ask when designing a language feature is: what should the balance … Continue reading →
by ericlippert on (#4CAV1)
Before that silly diversion I mentioned that we will be needing the empty distribution; today, we’ll implement it. It’s quite straightforward, as you’d expect. [Code for this episode is here.] public sealed class Empty<T> : IDiscreteDistribution<T> { public static readonly Empty<T> Distribution = new Empty<T>(); private Empty() { } public T Sample() => throw new Exception(“Cannot sample from empty distributionâ€); public IEnumerable<T> Support() => … Continue reading →
 |
by ericlippert on (#4C8F2)
I just thought of a really cute application of the stochastic workflow technology we’ve been working on; most of the series has already been written but it fits in here, so I’m going to insert this extra bonus episode. We’ll … Continue reading →
|
by ericlippert on (#4C0CB)
Before we get going on today’s episode of FAIC, you might want to refresh your memory of what an additive monad is; I wrote an episode of my monad series on this subject. Briefly, an additive monad is a monad … Continue reading →
by ericlippert on (#4BS7G)
[Code is here.] This series is getting quite long and we’re not done yet! This would be a good time to quickly review where we’re at: We’re representing a particular discrete probability distribution P(A) over a small number of members … Continue reading →
by ericlippert on (#4BMBN)
[Code is here.] Last time on FAIC we made a correct, efficient implementation of SelectMany to bind a likelihood function and projection onto a prior, and gave a simple example. I deliberately chose “weird†numbers for all the weights; let’s … Continue reading →
by ericlippert on (#4BHMJ)
UPDATE 3: Rock stars Scott Hanselman and Dan Fernandez and their colleagues have gotten my MSDN blog back up, and will also restore the late cbrumme’s blog as well. Thank you both, and everyone else at what I can only assume … Continue reading →
by ericlippert on (#4BAG7)
[Code is here.] Last time on FAIC we achieved two major results in our effort to build better probability tools. First, we demonstrated that the SelectMany implementation which applies a likelihood function to a prior probability is the bind operation … Continue reading →
by ericlippert on (#4B2MX)
[Code is here.] Last time on FAIC we discovered the interesting fact that conditional probabilities can be represented as likelihood functions, and that applying a conditional probability to a prior probability looks suspiciously like SelectMany, which is usually the bind … Continue reading →
 |
by ericlippert on (#4ATRS)
[Code is here.] Last time on FAIC we implemented an efficient “conditioned†probability using the Where operator on distributions; that is, we have some “underlying†distribution, and we ask the question “if a particular condition has to be met, what … Continue reading →
|
|
by ericlippert on (#4AJTQ)
[Code is here.] Last time on FAIC we drew a line in the sand and required that the predicates and projections used by Where and Select on discrete distributions be “pure†functions: they must complete normally, produce no side effects, … Continue reading →
|
by ericlippert on (#4ABG6)
[Code is here.] We’re going to spend the next while in this series on expressing probabilities that have some sort of extra condition associated with them. We’ll start with a simple example: I want to roll a fair six-sided die, but … Continue reading →
by ericlippert on (#4A377)
[Code is here.] Last time on FAIC I sketched out the “alias methodâ€, which enables us to implement sampling from a weighted discrete distribution in constant time. The implementation is slightly tricky, but we’ll go through it carefully. The idea … Continue reading →
by ericlippert on (#49Y8E)
[Code is here.] Last time on FAIC we sketched out an O(log n) algorithm for sampling from a weighted distribution of integers by implementing a discrete variation on the “inverse transform†method where the “inverse†step involves a binary search. … Continue reading →
 |
by ericlippert on (#49KM3)
[Code is here.] A few episodes back I made a version of the Bernoulli distribution that took integer “oddsâ€. That is, the distribution randomly produces either zero or one, and we can say “produce on average 23 zeros for every … Continue reading →
|
by ericlippert on (#49EP1)
[Code is here.] Last time on FAIC I showed how we could implement more of the standard, straightforward probability distributions, like the Bernoulli distribution; the episode before I showed the standard discrete uniform distribution, also known as “roll an n-sided … Continue reading →
by ericlippert on (#494RG)
[Code is here.] Last time on FAIC I implemented our first discrete distribution, the “choose an integer between min and max†distribution. I thought I might knock out a couple more of the easy discrete distributions. The easiest discrete distribution … Continue reading →
by ericlippert on (#4903F)
We briefly interrupt my ongoing exploration of stochastic programming to point you at a new blog about pragmatic programming language design. My friend and erstwhile Roslyn colleague Anthony is once more living in Chicago and has just started blogging anew, … Continue reading →
by ericlippert on (#48X2F)
[Code is here.] Last time on FAIC I showed how we could use a simple interface to cleanly implement concepts like “normal distribution†or “standard uniform distribution†in a natural style using fluent programming. For the next many episodes we’ll … Continue reading →
by ericlippert on (#48NJB)
[Code is here.] Last time on FAIC I described a first attempt of how I’d like to fix System.Random: Make every method static and threadsafe Draw a clear distinction between crypto-strength and pseudo-random methods There were lots of good comments … Continue reading →
by ericlippert on (#48E73)
[Code is here.] Last time on FAIC I complained bitterly about the shortcomings of System.Random. In this episode, I’ll take a stab at the sort of thing I’d like to see in a redesigned random library. This is the “fix … Continue reading →
by ericlippert on (#486B3)
[Code is here.] How to say this delicately? I really, really dislike System.Random. Like, with a passion. It is so… awful. The C# design team tries hard to make the language a “pit of successâ€, where the natural way to … Continue reading →
by ericlippert on (#47YM9)
This is the story of how I was no-hired by Microsoft; surprisingly, it is germane to our discussion of unusual list structures. I was a Waterloo co-op intern three times at Microsoft, each time working for the Visual Basic team; … Continue reading →
by ericlippert on (#47PK7)
Last time on FAIC I gave a standard implementation of a persistent immutable linked list, with cheap — O(1) — Push, Pop, Peek and IsEmpty operations, and expensive — O(n) — Append and Concatenate operations. In this episode we’re going … Continue reading →
by ericlippert on (#47HBK)
As long-time readers of my blog know, I’m a big fan of functional persistent immutable list data structures. I recently learned about a somewhat bizarre but very practical implementation of such lists, and naturally I wanted to implement it myself … Continue reading →
by ericlippert on (#479EW)
Pop quiz: Consider these little methods. (They could be static, inline, whatever, that doesn’t matter.) int[] A1() { Console.WriteLine(“Aâ€); return new int[10]; } int[] A2() { Console.WriteLine(“Aâ€); return null; } int B1() { Console.WriteLine(“Bâ€); return 1; } int B2() { Console.WriteLine(“Bâ€); return 11; } int C() { Console.WriteLine(“Câ€); … Continue reading →
 |
by ericlippert on (#47473)
Last time on FAIC I gave a hand-wavy intuitive explanation for why it is that lifting a function on doubles to duals gives us “automatic differentiation†on that function — provided of course that the original function is well-behaved to … Continue reading →
|
 |
by ericlippert on (#46Z0B)
Last time on FAIC we discovered that when you “lift†a polynomial on doubles to a polynomial on duals and then evaluate it with x+1ε, the “real†part of the returned dual exactly corresponds to the original polynomial at x; … Continue reading →
|
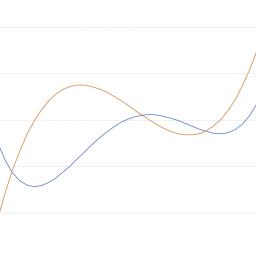 |
by ericlippert on (#46Q04)
Last time on FAIC I introduced a fun variation on complex numbers called “dual numbers†consisting of a value “plus a tiny bit†notated as ε, where the really tiny part has the interesting property that ε2 is zero. Well, … Continue reading →
|
by ericlippert on (#46F2D)
I’ve recently been looking into a fascinating corner of mathematics that at first glance appears a little bit silly, but actually has far-reaching applications, from physics to numerical methods to machine learning. I thought I’d share what I’ve learned over … Continue reading →
|
by ericlippert on (#464V8)
Happy New Year all and welcome to another year of having fabulous adventures in coding. I thought I’d start this year off by answering a question I get quite frequently: I have a public outer class with a public nested … Continue reading →
|
|
by ericlippert on (#456G0)
Good day all, before we get into the continuation of the previous episode, a few bookkeeping notes. First, congratulations to the Python core developers on successfully choosing a new governance model. People who follow Python know that the Benevolent Dictator … Continue reading →
|
|
by ericlippert on (#447C8)
For the last two decades or so I’ve admired the simplicity and power of the Python language without ever actually doing any work in it or learning about the details. I’ve been taking a closer look lately and having a … Continue reading →
|
|
by ericlippert on (#43WDB)
Many thanks to Phil Burgess, who invited me to be this week’s guest on his podcast, IT Career Energizer. I enjoyed our conversation, and I’m looking forward to listening to past episodes. Check it out on the link above, or … Continue reading →
|
|
by ericlippert on (#43925)
Sorry for that unexpected interlude into customer service horrors; thanks for your patience and let’s get right back to coding horrors! So as not to bury the lede: the C# compiler is correct to flag the program from the last … Continue reading →
|
 |
by ericlippert on (#431Y7)
I’ve banked with First Tech Credit Union since 1994, when they were the only bank that would give a non-resident Microsoft intern like me an account. I had nothing but good service from them for many years, but in the … Continue reading →
|
|
by ericlippert on (#42YCT)
I’ve often noted that “dynamic†in C# is just “object†with a funny hat on, but there are some subtleties to that. Here’s a little puzzle; see if you can figure it out. I’ll post the answer next time. Suppose … Continue reading →
|
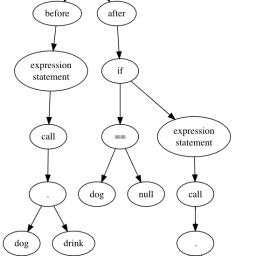 |
by ericlippert on (#42ERW)
Last time I gave a simple C# implementation of the first-order anti-unification algorithm. This is an interesting algorithm, but it’s maybe not so clear why anti-unification is useful at all. It’s pretty clear why unification is interesting: we have equations … Continue reading →
|
|
by ericlippert on (#42CCM)
Last time we wrote all the boring boilerplate code for substitutions and trees. Now let’s implement the algorithm. As I noted a couple of episodes back, we can reduce the algorithm to repeated application of two rules that mutate three … Continue reading →
|
|
by ericlippert on (#429WR)
All right, let’s implement this thing. We’ll start with a few caveats: In the previous post I worked an example on function calls; in this code, we’ll do the algorithm on syntax trees. Hopefully it is obvious that they’re equivalent. … Continue reading →
|
|
by ericlippert on (#424PZ)
Last time we described the classic first-order anti-unification algorithm, and reduced it from three rules to only two. Let’s work an example, the same example that we gave a while back. s is cons(cons(1, 2), cons(cons(1, 2), nil)) t is … Continue reading →
|
|
by ericlippert on (#41ZPE)
Last time on FAIC we learned what the first-order anti-unification problem is: given two expressions, s and t, either in the form of operators, or method calls, or syntax trees, doesn’t matter, find the most specific generalizing expression g, and … Continue reading →
|
|
by ericlippert on (#41TP6)
Last time on FAIC we noted that there was a simple, recursive, linear-time first-order unification algorithm. We didn’t give the algorithm, but hopefully you see how it would go. The point is, we start with two expressions that contain some … Continue reading →
|