
 |
by Rich Brueckner on (#4WZHG)
In this video from the DDN User Group at SC19, Gael Delbray from CEA presents: Optimizing Flash at Scale. "The major challenges that the HPC will face in the coming years are manifold, such as the development of hardware and software architectures able to deliver very high computing power, modelling methods combining different scales and physical models and the management of huge volumes of numerical data."The post Video: Optimizing Flash at Scale at CEA appeared first on insideHPC.
|
| Link | http://insidehpc.com/ |
| Feed | http://insidehpc.com/feed/ |
| Updated | 2026-06-16 21:00 |
 |
by Rich Brueckner on (#4WZ7T)
In this TACC podcast, UC Berkeley scientists describe how they are using powerful supercomputers to uncover the mechanism that activates cell mutations found in about 50 percent of melanomas. "The study's computational challenges involved molecular dynamics simulations that modeled the protein at the atomic level, determining the forces of every atom on every other atom for a system of about 200,000 atoms at time steps of two femtoseconds."The post XSEDE Supercomputers Advance Skin Cancer Research appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WYTS)
IBM and the University of Tokyo have announced an agreement to partner to advance quantum computing and make it practical for the benefit of industry, science and society. "Under the agreement, an IBM Q System One will be installed in an IBM facility in Japan. It will be the first installation of its kind in the region and only the third in the world following the United States and Germany. The Q System One will be used to advance research in quantum algorithms, applications and software, with the goal of developing the first practical applications of quantum computing."The post IBM Launches Quantum Computing Initiative for Japan appeared first on insideHPC.
|
 |
by staff on (#4WY6F)
In this podcast, the Radio Free HPC recaps the recent CHPC National Conference in South Africa. "Now a 5-day conference with two days of workshops as book-ends, multiple tracks and many speakers, and yes, a very exciting Student Cluster Competition, the CHPC National Conference has developed into a very important event in the HPC/AI world. Dan Olds takes us through what he saw, who won, and what we can expect at the competition at ISC in 2020, and just how impressive the whole thing was."The post CHPC Student Cluster Winners Get Ready to take ISC by Storm appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WY6H)
Jeffrey Vetter from ORNL gave this talk at ATPESC 2019. "In this talk, I'm going to cover some of the high-level trends guiding our industry. Moore’s Law as we know it is definitely ending for either economic or technical reasons by 2025. Our community must aggressively explore emerging technologies now!"The post The Coming Age of Extreme Heterogeneity in HPC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WX3G)
In this video, Mark Lindsay from the University of Western Australia describes how his research enables Australia's mining industry to efficiently explore for important mineral deposits called e-minerals once associated with electric cars and lithium-ion batteries. His research interests include complexities of uncertainty and ambiguity in 3D geological and mineral exploration modelling, and the process and psychology of data interpretation.The post Video: Using Supercomputers to Explore the Earth’s Crust appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WX3J)
The University of Arkansas is seeking a Research Computing Technical Facilitator in our Job of the Week. "The Research Computing Technical Facilitator is an integral member of the University of Arkansas central IT Services research computing support team, collaborating with diverse and talented team members to help solve multidimensional information technology problems, improve customer experience, and generate value for our campus stakeholders across a broad base of departments and constituencies."The post Job of the Week: Research Computing Technical Facilitator at University of Arkansas appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WVVK)
Global Unichip Corp. has adopted ANSYS to support its unmatched combination of advanced technology, low-power and embedded CPU design capabilities. "GUC is committed to providing world-class custom ASICs to help elevate prospective systems and integrated circuit (IC) companies’ market-leading positions," said Louis Lin, senior vice president, GUC. "As IC manufacturing processes become more complex, there are more elements to simulate and compute during chip design and verification to ensure reliability and minimize power loss. ANSYS helps us minimize this complexity, speed our time to market and reduce development costs. Our partnership with ANSYS has been a cornerstone in helping our clients succeed in the IC market."The post ANSYS Accelerates Electronic Product Design at GUC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WVJ3)
Today Synopsys announced that NEC has selected Synopsys' ZeBu Server 4 as its emulation solution for the verification of its SX-Aurora TSUBASA high-performance compute solution products. "Developing super computers requires running and analyzing many software applications on the new HPC architecture," said Akio Ikeda, deputy general manager, AI Platform Division at NEC Corporation. "ZeBu Server 4 enabled execution of our HPC host software without modifications and running billions of software cycles prior to tapeout. We selected ZeBu Server 4 because of its superior performance and very fast bring-up time."The post NEC Selects Synopsys ZeBu Server 4 Emulation Environment for Supercomputer Verification appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WVJ5)
In this episode of Let’s Talk Exascale, Hartwig Anzt from the University of Tennessee describes how the ECP Ginkgo Library Project is developing a vision for multiprecision algorithms. "Anything reducing the data transfer volume while still communicating the information can help make use of the software more efficient. Benefits are available even if the decreased data transfer volume comes at the cost of additional operations."The post Podcast: Developing Multiprecision Algorithms with the Ginkgo Library Project appeared first on insideHPC.
|
 |
by staff on (#4WT5Q)
Inspur recently launched all-flash storage systems with dual-port Intel Optane SSDs. "With the Optane SSD as the high-speed cache layer, AS5000G5-F combines innovative technologies such as intelligent data layering, on-board hardware acceleration and online compression/deduplication, which achieves up to 8 million IOPS and a latency of 0.1ms, representing one of the highest performing mid-range storage systems available in the industry."The post Intel Optane comes to new Inspur Storage Products appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WT5S)
Today GIGABYTE announced two new single socket ATX motherboards ready for Intel’s new Xeon W-3200 processor. This new platform is purpose built and optimized for advanced workstation professionals, enabling fast visualization, simulations and renderings with up to 28 cores, 56 threads, a maximum base frequency of 3.7 GHz and a maximum turbo frequency of 4.6GHz in a single socket solution. The MU71-SU0 can also be used instead for a single 2nd Gen Intel Xeon Scalable Family processor that features support for Intel® Optane™ DC Persistent Memory Modules.The post GIGABYTE Launches Intel Xeon W-3200 & Xeon Scalable Workstation & Server Motherboards appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WT5V)
Today the PASC20 conference announced that Vivien Kendon from Durham University will deliver a keynote talk on quantum computing. With a theme of New Challenges, New Computing Paradigms, the event takes place June 29 - July 1 in Geneva, Switzerland. "Quantum computing promises more efficient computation for some important types of problems, such as simulation of quantum systems, non-convex optimization, and (famously) factoring large semi-primes. However, the first useful quantum computers will be limited in what they can do. Applying them to bottlenecks that are hard for classical computers is key to extracting the best performance out of combined classical and quantum hardware."The post Vivien Kendon from Durham University to Keynote PASC20 in Geneva appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WSVR)
"This years BoF will follow this traditional format and present detailed analyses of the TOP500 and discuss the changes in the HPC marketplace during the past years. Results from the Green500 and the HPCG benchmark will also be discussed. The BoF is meant as an open forum for discussion and feedback between the TOP500 authors and the user community."The post Video: SC19 BoF session on TOP500 supercomputers appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WSVT)
Today Mississippi State University and the NOAA celebrated one of the country’s most powerful supercomputers with a ribbon-cutting ceremony for the Orion supercomputer, the fourth-fastest computer system in U.S. academia. Funded by NOAA and managed by MSU’s High Performance Computing Collaboratory, the Orion system is powering research and development advancements in weather and climate modeling, autonomous systems, materials, cybersecurity, computational modeling and more.The post Orion Supercomputer comes to Mississippi State University appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WREM)
Today NVIDIA announced that it will provide the transportation industry with access to its NVIDIA DRIVE deep neural networks (DNNs) for autonomous vehicle development. "NVIDIA DRIVE has become a de facto standard for AV development, used broadly by automakers, truck manufacturers, robotaxi companies, software companies and universities. Now, NVIDIA is providing access of its pre-trained AI models and training code to AV developers. Using a suite of NVIDIA AI tools, the ecosystem can freely extend and customize the models to increase the robustness and capabilities of their self-driving systems."The post NVIDIA Provides Transportation Industry Access to its DNNs for Autonomous Vehicles appeared first on insideHPC.
|
 |
by staff on (#4WREP)
The ASC Student Supercomputer Challenge 2020 (ASC20) officially kicked off its event at SC19 in Denver, announcing the location and timeline for the upcoming event. "The ASC cluster competition is the biggest in the world with 20 university teams of undergraduate students competing to build the most powerful cluster while keeping power consumption under 3,000 watts. Inspur provides servers to the competitors who then configure their own cluster designs, put them together, and then optimize them and tune the benchmarking and HPC/AI applications for maximum performance."The post 2020 Asia Student Cluster Competition Kick-Off appeared first on insideHPC.
|
 |
by staff on (#4WR4Z)
Today NVIDIA introduced NVIDIA DRIVE AGX Orin, a highly advanced software-defined platform for autonomous vehicles and robots. "The platform is powered by a new system-on-a-chip (SoC) called Orin, which consists of 17 billion transistors and is the result of billions of dollars in R&D investment over a four-year period. The Orin SoC integrates NVIDIA’s next-generation GPU architecture and Arm Hercules CPU cores, as well as new deep learning and computer vision accelerators that, in aggregate, deliver 200 trillion operations per second—nearly 7x the performance of NVIDIA’s previous generation Xavier SoC."The post NVIDIA Unveils Advanced, Software-Defined Platform for Autonomous Machines appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WR51)
An extensive collaboration led by Argonne won the Inaugural SCinet Technology Challenge at the SC19 conference by demonstrating real-time analysis of light source data from Argonne’s APS to the ALCF. "Accelerator-based light sources — large-scale instruments used to investigate the fundamental properties of matter — generate large amounts of data that require computational analysis. The Argonne team won by designing an innovative method to support such investigations."The post Argonne-led team wins SCinet Technology Challenge at SC19 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WR53)
The convergence of HPC and AI is driving a paradigm shift in computing. Learn about Intel’s software-first strategy to further accelerate this convergence and extend the boundaries of HPC as we know it today. oneAPI will ease application development and accelerate innovation in the xPU era. Intel delivers a diverse mix of scalar, vector, spatial, and matrix architectures deployed in a range of silicon platforms (such as CPUs, GPUs, FPGAs), and specialized accelerators—each being unified by an open, industry-standard programming model. The talk concludes with innovations in a new graphics architecture and the capabilities it will bring to the Argonne exascale system in 2021.The post Intel HPC Devcon Keynote: Exascale for Everyone appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WPTX)
Today Nortek Air Solutions celebrated the completion of its first manufactured StatePoint Liquid Cooling (SPLC) system, billed as “The World’s First Sustainable Data Center Cooling Technology.†SPLC technology was co-developed through a partnership with Facebook. "StatePoint Liquid Cooling provides a data center cooling option that facilitates our ‘To Create a Better Tomorrow Every Day’ mission by reducing carbon emissions and water consumption versus other digital environment HVAC methods,†said Bruno Biasiotta, CEO, Nortek Air Solutions, who signed the first manufactured SPLC system with other attending NAS executives. “HVAC equipment is expected to increase the world’s carbon emissions from today’s 15-percent to 25-percent by 2030. Water is also a precious commodity that is limited supply. Therefore, StatePoint is an HVAC solution that will ultimately promote a conscientious stewardship of our planet.â€The post Nortek Builds First StatePoint Liquid Cooling System appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WPJ5)
Today the Internet2 advanced technology community announced it has selected CenturyLink’s new low-loss fiber network to transform its research and education network. The improved network performance that results will benefit researchers within the community as they strive to further our understanding of our world and the universe. "This acquisition will upgrade Internet2’s Network with new fiber optimized to support the demands of its new all-coherent open-line system. CenturyLink has also been selected to provide the professional services to migrate Internet2 to its new platform, which will be equipped with a flex-grid open-line system being provided by Ciena."The post Internet2 to Maximize Research Network Performance with CenturyLink’s Advanced Optical Fiber appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WPJ6)
In this special guest feature, IBM's VP of AI Research Sriram Raghavan shares the company's predictions for AI in 2020. "In 2020, three themes will shape the advancement of AI: automation, natural language processing (NLP), and trust. Broadly, we’ll see AI systems work more quickly and more easily for data scientists, businesses, and consumers through automation."The post IBM Research AI Predictions for 2020 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WPJ8)
Cisco is announcing its intent to acquire Exablaze, a privately held, Australia-based designer and manufacturer of advanced network devices. Exablaze’s design and manufacturing innovation offer customers the latest Field Programmable Gate Array (FPGA) technology with the required flexibility and programmability for environments where ultra-low-latency and high performance is critical. These next-generation products include advanced ultra-low latency FPGA-based switches and network interface cards (NICs), as well as picosecond resolution timing technology. "In the case of the high frequency trading sector, every sliver of time matters. By adding Exablaze’s segment leading ultra-low latency devices and FPGA-based applications to our portfolio, financial and HFT customers will be better positioned to achieve their business objectives and deliver on their customer value proposition."The post Cisco to Acquire Exablaze appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WPJA)
In this video from LAD'19 in Paris, Peter Jones from Whamcloud presents: Lustre Community Release Update. "Lustre is a vibrant Open Source project with many organizations working on new features and improvements in parallel. We coordinate those efforts primarily through OpenSFS and EOFS. Meeting development target dates is a difficult task for any software project, but doubly so in a globally distributed Open Source project."The post Video: Lustre Community Release Update appeared first on insideHPC.
|
 |
by staff on (#4WN4A)
On December 5, OpenSFS announced Lustre 2.13.0 Release has been declared GA and is available for download. The Lustre file system is a open source, parallel file system that supports the requirements of leadership class HPC and Enterprise environments worldwide. Lustre provides a POSIX compliant interface and scales to thousands of clients, petabytes of storage, and has demonstrated over a terabyte per second of sustained I/O bandwidth. "New features include: Persistent Client Cache, Multi-Rail Routing, Overstriping, and self-extending layouts."The post OpenSFS Announces Lustre 2.13.0 Release appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WMVH)
Today Intel announced it has acquired Habana Labs, an Israel-based developer of programmable deep learning accelerators for the data center for approximately $2 billion. "This acquisition advances our AI strategy, which is to provide customers with solutions to fit every performance need – from the intelligent edge to the data center.â€The post Intel Acquires AI Chipmaker Habana Labs appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WMVK)
In this Let's Talk Exascale podcast, Kathryn Mohror LLNL and Sarp Oral of ORNL provide an update ECP’s ExaIO project and UnifyFS. "UnifyFS can provide ECP applications performance-portable I/O across changing storage system architectures, including the upcoming Aurora, Frontier, and El Capitan exascale machines. “It is critically important that we provide this portability so that application developers don’t need to spend their time changing their I/O code for every system."The post Podcast: UnifyFS Software Project steps up to Exascale appeared first on insideHPC.
|
 |
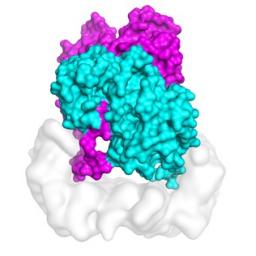
by Rich Brueckner on (#4WMVN)
Scientists are getting better at modeling the complex tangle of physics properties at play in one of the most powerful events in the known universe: the merger of two neutron stars. "We’re starting from a set of physical principles, carrying out a calculation that nobody has done at this level before, and then asking, ‘Are we reasonably close to observations or are we missing something important?’†said Rodrigo Fernández, a co-author of the latest study and a researcher at the University of Alberta.The post Supercomputing a Neutron Star Merger appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WMVQ)
In this keynote from HPE Discover More in Paris, Dr. Eng Lim Goh from HPE offers up some inspiring real-world use cases that demonstrate the transformative power of AI and supercomputing. "Solving the biggest challenges of tomorrow will require powerful computers running complex systems with minimal human input."The post Dr. Eng Lim Goh presents: Transforming Tomorrow with AI & HPC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WKH8)
Ewa Deelman from the University of Southern California gave this Invited Talk at SC19. "This presentation examines selected modern scientific discoveries, such as the detection of gravitational waves from the CI perspective. It aims to answer the following key questions: first, what were the key CI solutions that enabled a particular scientific result? and second, what were the challenges that needed to be overcome?"The post The Role of Cyberinfrastructure in Science: Challenges and Opportunities appeared first on insideHPC.
|
 |
by staff on (#4WKHA)
Today Aldec, Inc. launched a powerful, versatile and time-saving FPGA-based NVMe Data Storage solution to aid in the development of High Performance Computing applications such as High Frequency Trading and Machine Learning. "NVMe SSDs are very popular in a wide range of high-performance computing applications, as are FPGAs because of their ability to handle parallel processing, their speed and programmability, plus the fact MPSoC FPGAs also feature ARM processor cores,†comments Louie De Luna, Director of Marketing. “Our newest FPGA-based embedded solution is aimed at engineers developing systems that will combine the power and benefits of NVMe and FPGAs."The post Aldec’s new FPGA-based NVMe Data Storage Targets HPC Applications appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WJHV)
SAIC in Monterey, California is seeking an NRL Research Scientist in our Job of the Week. "SAIC is a premier technology integrator, solving our nation's most complex modernization and systems engineering challenges across the defense, space, federal civilian, and intelligence markets. Our robust portfolio of offerings includes high-end solutions in systems engineering and integration; enterprise IT, including cloud services; cyber; software; advanced analytics and simulation; and training."The post Job of the Week: NRL Research Scientist at SAIC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WJHX)
In this podcast, the Radio Free HPC team looks back the “State Fair for Nerds†that was SC19. "At this year’s conference, we not only learned the latest discoveries in our evolving field – but also celebrated the countless ways in which HPC is improving our lives … our communities … our world. So many people worked together to make SC19 possible – more than: 780 volunteers, 370 exhibitors, 1,150 presenters, and a record 13,950 attendees."The post Radio Free HPC Recaps SC19 appeared first on insideHPC.
|
 |
by staff on (#4WHA5)
Bright Computing recently announced that the University of Siegen has expanded its use of the company's HPC system management software to address the increasingly varied and challenging demands from its research staff. "We have had nothing but positive experiences with Bright Cluster Manager and the Bright support team," said Daniel Harlacher, HPC team leader at University of Siegen. "I would highly recommend the technology. Bright increases the performance of my team by automating many everyday tasks, freeing my team to concentrate on delivering exceptional service to our university departments."The post University of Siegen Doubles Down on Bright Computing for HPC Management appeared first on insideHPC.
|
 |
by staff on (#4WHA6)
In this special guest feature, Dan Olds from OrionX.net continues his series of stories on the SC19 Student Cluster Competition. Held as part of the Students@SC program, the competition is designed to introduce the next generation of students to the high-performance computing community. "Nanyang Tech took home the Highest LINPACK Award at the recently concluded SC19 Student Cluster Competition. The team, also known as the Pride of Singapore (at least to me), easily topped the rest of the field with their score of 51.74 Tflop/s."The post SC19 Cluster Competition: Students Pack LINs and HPCG’s appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WHA7)
In this special guest feature, Trish Damkroger from Intel writes that only HPC can handle the pending wave of Big Data coming to datacenters from Smart Cities. "While each individual city’s data footprint depends on the unique mix of smart applications deployed, you could guess that each smart city still has a lot of data to contend with. In the future, many cities may turn to AI algorithms to tap into this data to manage city operations. However, the scale of the data and need for rapid insights will make HPC-level computing resources a requirement to make the most of this opportunity."The post Why HPC is no longer just for government labs and academic institutions appeared first on insideHPC.
|
 |
by staff on (#4WH1F)
Julia is already well regarded for programming multicore CPUs and large parallel computing systems, but recent developments make the language suited for GPU computing as well. The performance possibilities of GPUs can be democratized by providing more high-level tools that are easy to use by a large community of applied mathematicians and machine learning programmers.The post Julia Computing and GPU Acceleration appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WH1H)
Dr. Ilkay Altintas from SDSC gave this Invited Talk at SC19. "This talk will review some of our recent work on building this dynamic data driven cyberinfrastructure and impactful application solution architectures that showcase integration of a variety of existing technologies and collaborative expertise. The lessons learned on use of edge and cloud computing on top of high-speed networks, open data integrity, reproducibility through containerization, and the role of automated workflows and provenance will also be summarized."The post SC19 Invited Talk: Next Generation Disaster Intelligence Using the Continuum of Computing and Data Technologies appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WFKS)
Today Atos launched the global User Group of the Atos Quantum Learning Machine (QLM). Chaired by a representative from French multi-national energy company Total, the User Group ecosystem is supported by the Atos’ Quantum Scientific Council, which includes universally recognized quantum physicists. It is also further enhanced by partners such as leading software company Zapata and start-up Xofia. "Now, with the creation of this Group of Atos QLM Users, we are ensuring that we continue to support them to develop new advances in deep learning, algorithmics and artificial intelligence with the support of the breakthrough computing acceleration capacities that quantum simulation provides.â€The post Atos Launches Quantum Learning Machine User Group appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WFKT)
In this special guest feature, David Fellinger from the iRODS Consortium writes that, as eResearch has evolved to accommodate sensor and other types of big data, iRODS can enable complete workflow control, data lifecycle management, and present discoverable data sets with assured traceability and reproducibility.The post Building a Tiered Digital Storage Environment Based on User-Defined Metadata to Enable eResearch appeared first on insideHPC.
|
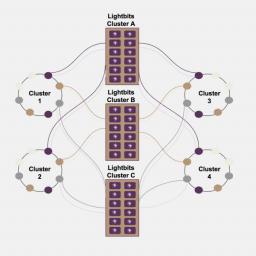 |
by Rich Brueckner on (#4WFAV)
Today Lightbits Labs announced it has delivered the industry's first NVMe/TCP clustered storage solution with the company's LightOS technology. "At cloud scale, everything fails, so we built LightOS to capture all the benefits of disaggregated storage while providing exceptional durability and availability to prevent service disruption,†said Kam Eshghi, Chief Strategy Officer at Lightbits Labs."The post Lightbits Labs Launches Industry’s First NVMe/TCP Clustered Storage Solution appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WFAX)
In this video from SC19, Greg Stewart from Novel Therm describes how the company provides HPC As a Service using geothermal energy. "Novel Therm has a unique solution that allows them to build low-cost HPC data centers that are powered by low temperature geothermal energy. With their innovative technology, they provide 100% green powered data centers with no upfront customer investment and at significantly lower cost than competitors can offer."The post Novel Therm Demonstrates Sustainable Data Center Tech at SC19 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WFAZ)
Today Lenovo and Intel announced their collaboration to modernize HPC infrastructure at Austria’s most powerful supercomputer – the Vienna Scientific Cluster-4 (VSC-4). Built on Lenovo ThinkSystem servers and 2nd generation Intel Xeon Scalable processors, VSC-4 supports more than 300 research projects led by scientists from higher education institutions throughout Austria, covering life-enhancing challenges such as meteorology to materials science, quantum chemistry to genetics.The post Lenovo and Intel Partner for VSC-4 Supercomputer in Vienna appeared first on insideHPC.
|
 |
by staff on (#4WDY8)
Today D-Wave Systems announced the company has signed agreements with NEC Corporation to drive development of hybrid services that combine the best features of quantum and classical computers, and make it easy to incorporate quantum capabilities into integrated workflows. D-Wave and NEC plan to market and sell D-Wave’s Leap quantum cloud service, which includes hybrid tools and services, as well as new hybrid capabilities to be jointly developed. NEC has committed to invest $10 million in D-Wave. The collaboration will take effect upon the closing of NEC’s investment, which is subject to certain conditions.The post D-Wave and NEC to Accelerate Commercial Quantum Computing appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4W69E)
Now that SC19 is behind us, it's time to gather our booth tour videos in one place. Throughout the course of the show, insideHPC talked to dozens of HPC innovators showcasing the very latest in hardware, software, and cooling technologies.The post Full Roundup: SC19 Booth Tour Videos from insideHPC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WDM6)
Researchers from the University of Bristol and the French National Centre for Scientific Research, teamed up with computer technology giant Oracle and vaccine innovator startup Imophoron to find a way to make vaccines that are thermostable, can be designed quickly, and are easily produced. "The research resulted in a new type of vaccine that can be stored at warmer temperatures, removing the need for refrigeration, in a major advance in vaccine technology."The post Developing Better Vaccines with Oracle Cloud Infrastructure appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WDM8)
Today WekaIO announced that Innoviz, a leading manufacturer of high-performance, solid-state Light Detection and Ranging (LiDAR) sensors and Perception Software that enables the mass-production of autonomous vehicles, has selected the Weka File System (WekaFS) to accelerate its Artificial Intelligence (AI) and deep learning workflows. WekaFS has been chosen by Innoviz to improve application performance at scale and deliver high bandwidth I/O to its GPU cluster.The post Innoviz to Accelerate AI for Autonomous Vehicles with WekaIO appeared first on insideHPC.
|
 |
by staff on (#4WDMA)
Today the InfiniBand Trade Association (IBTA) reported the latest TOP500 List results show that HDR 200Gb/s InfiniBand accelerates 31 percent of new InfiniBand-based systems on the List, including the fastest TOP500 supercomputer built this year. The results also highlight InfiniBand’s continued position in the top three supercomputers in the world and acceleration of six of the top 10 systems. Since the TOP500 List release in June 2019, InfiniBand’s presence has increased by 12 percent, now accelerating 141 supercomputers on the List.The post HDR 200Gb/s InfiniBand Sees Major Growth on Latest TOP500 List appeared first on insideHPC.
|
 |
by Rich Brueckner on (#4WDMB)
In this video from the Arm booth at SC19, Scott Shadley from NGD Systems describes the company's innovative computational storage technology. "In a nutshell, Computational Storage is an IT architecture where data is processed at the storage device level to reduce the amount of data that has to move between the storage and compute planes. As such, the technology provides a faster and more efficient means to address the unique challenges of our data-heavy world – satisfying reduced excess bandwidth and providing very low latency response times by reducing data movement and allowing response for analytics as much as 20 to 40-times faster."The post NGD Systems Steps up with Arm Processors on SSDs at SC19 appeared first on insideHPC.
|