
 |
by Rich Brueckner on (#2E4G7)
Today the PASC17 Conference announced Professor Katrin Amunts plenary presentation will be entitled, “Towards the Decoding of the Human Brain.†Regarded as one of the world’s foremost neuroscientists in the field of brain mapping, Dr. Amunts is director of the Cécile and Oskar Vogt Institute of Brain Research at the University of Düsseldorf, and director of the Institute of Neuroscience and Medicine at Forschungszentrum Jülich.The post Katrin Amunts to Present on Decoding the Human Brain at PASC17 appeared first on insideHPC.
|
| Link | http://insidehpc.com/ |
| Feed | http://insidehpc.com/feed/ |
| Updated | 2026-06-20 05:15 |
 |
by Rich Brueckner on (#2E4AT)
“To achieve good scalability performance on the HPC scientific applications typically involves good understanding of the workload though performing profile analysis, and comparing behaviors of using different hardware which pinpoint bottlenecks in different areas of the HPC cluster. In this session, a selection of HPC applications will be shown to demonstrate various methods of profiling and analysis to determine the bottleneck, and the effectiveness of the tuning to improve on the application performance from tests conducted at the HPC Advisory Council High Performance Center.â€The post Application Profiling at the HPCAC High Performance Center appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2E45A)
The International Conference on Parallel Processing (ICPP 2017) has issued its Call for Papers. The event takes place August 14-17 in Bristol, UK. "Parallel and distributed computing is a central topic in science, engineering and society. ICPP, the International Conference on Parallel Processing, provides a forum for engineers and scientists in academia, industry and government to present their latest research findings in all aspects of parallel and distributed computing."The post Call for Papers: International Conference on Parallel Processing in Bristol appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2E41R)
In this podcast, Radio Free HPC looks at a Startup called Storj, which will pay you to use your excess data capacity as cloud-based storage based on Blockchain technology. “Our mission is to rethink cloud storage, to provide the security, privacy, and transparency it’s missing. That’s why we are building an open-source cloud platform, that aim to fundamentally change the way people and devices own data.â€The post Radio Free HPC Looks at Storj Blockchain Technology in the Cloud appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2E12B)
"EuroMPI/USA 2017 will continue to focus on not just MPI, but also extensions or alternative interfaces for high-performance homogeneous/heterogeneous/hybrid systems, benchmarks, tools, parallel I/O, fault tolerance, and parallel applications using MPI and other interfaces. Through the presentation of contributed papers, poster presentations and invited talks, attendees will have the opportunity to share ideas and experiences to contribute to the improvement and furthering of message-passing and related parallel programming paradigms."The post Call for Papers: EuroMPI/USA 2017 in Chicago appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2E0WB)
"With a team of four and less than $2 million, REX has taken a design concept to reality in under a year with a 16 core processor manufactured on a modern TSMC 28nm process node. With this test silicon, REX is breaking the traditional semiconductor industry idea that it takes large teams along with tens or even hundreds of millions of dollars to deliver a groundbreaking processor. This talk will feature an overview of the Neo ISA, microarchitecture review of the first test silicon, along with a live hardware/software demonstration."The post The REX Neo: An Energy Efficient New Processor Architecture appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2DXZ7)
The IEEE High Performance Extreme Computing Conference (HPEC 2017) has issued its Call for Papers. The conference takes place September 12-14 in Waltham, MA. "HPEC is the largest computing conference in New England and is the premier conference in the world on the convergence of High Performance and Embedded Computing. We are passionate about performance. Our community is interested in computing hardware, software, systems and applications where performance matters. We welcome experts and people who are new to the field."The post Call for Papers: HPEC 2017 in Waltham appeared first on insideHPC.
|
 |
by staff on (#2DXWS)
“From home assistants like the Amazon Echo to Google’s self-driving cars, artificial intelligence is slowly creeping into our lives. These new technologies could be enormously beneficial, but they also offer hackers unique opportunities to harm us. For instance, a self-driving car isn’t just a robot—it’s also an internet-connected device, and may even have a cell phone number.â€The post Podcast: Cybersecurity Challenges in a World of AI appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2DTFS)
Today the Google Cloud Platform announced that it is the first cloud provider to offer the next generation Intel Xeon processor, codenamed Skylake. "Skylake includes Intel Advanced Vector Extensions (AVX-512), which make it ideal for scientific modeling, genomic research, 3D rendering, data analytics and engineering simulations. When compared to previous generations, Skylake’s AVX-512 doubles the floating-point performance for the heaviest calculations. In our own internal tests, it improved application performance by up to 30%."The post Intel Skylake Comes to Google Cloud Platform appeared first on insideHPC.
|
 |
by staff on (#2DTBY)
The Department of Energy’s Oak Ridge National Laboratory has announced the latest release of its Adaptable I/O System (ADIOS), a middleware that speeds up scientific simulations on parallel computing resources such as the laboratory’s Titan supercomputer by making input/output operations more efficient. "As we approach the exascale, there are many challenges for ADIOS and I/O in general,†said Scott Klasky, scientific data group leader in ORNL’s Computer Science and Mathematics Division. “We must reduce the amount of data being processed and program for new architectures. We also must make our I/O frameworks interoperable with one another, and version 1.11 is the first step in that direction.â€The post ADIOS 1.11 Middleware Moves I/O Framework from Research to Production appeared first on insideHPC.
|
 |
by staff on (#2DT9X)
"Computational science has come a long way with machine learning (ML) and deep learning (DL) in just the last year. Leading centers of high-performance computing are making great strides in developing and running ML/DL workloads on their systems. Users and algorithm scientists are continuing to optimize their codes and techniques that run their algorithms, while system architects work out the challenges they still face on various system architectures. At SC16, I had the honor of hosting three of HPC’s thought leaders in a panel to get their ideas about the state of Artificial Intelligence (AI), today’s challenges with the technology, and where it’s going."The post Artificial Intelligence: It’s No Longer Science Fiction appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2DT5X)
In this video from the 2017 HPC Advisory Council Stanford Conference, Subhasish Mitra from Stanford presents: Beyond the Moore's Law Cliff: The Next 1000X. Professor Subhasish Mitra directs the Robust Systems Group in the Department of Electrical Engineering and the Department of Computer Science of Stanford University, where he is the Chambers Faculty Scholar of Engineering. Prior to joining Stanford, he was a Principal Engineer at Intel Corporation. He received Ph.D. in Electrical Engineering from Stanford University.The post Beyond the Moore’s Law Cliff: The Next 1000X appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2DPTB)
Nvidia is seeking a GPU Performance Analysis Architect in our Job of the Week. "The NVIDIA GPU Compute Architecture group is seeking world-class architects to analyze processor and system architecture performance of full applications in machine learning, automotive, and high-performance computing. This position offers the opportunity to have a real impact on the hardware and software that underlies the most exciting trends in modern computing."The post Job of the Week: GPU Performance Analysis Architect at Nvidia appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2DPPA)
Applications are now being accepted for the Student Volunteers program at the SC17 conference to be held Nov. 12-17 in Denver. Both undergraduate and graduate students are encouraged to apply. "Being a Student Volunteer can be transformative, from helping to find internships to deciding to pursue graduate school. Read about how Ather Sharif’s Student Volunteer experience inspired him to enroll in a Ph.D. program."The post Applications Now Open for Student Volunteers at SC17 Conference appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2DPJ1)
"Through multiscale simulation of the circulatory system, it is now possible to model this surgery and optimize it using the state of the art optimization techniques. In-silico analysis has allowed us to test new surgical design without posing any risk to patient's life. I will show the outcome of this study, which is a novel surgical option that may revolutionize current clinical practice."The post Video: Multi-Physics Methods, Modeling, Simulation & Analysis appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2DPEJ)
Today ISC 2017 announced that data scientist, Prof. Dr. Jennifer Tour Chayes from Microsoft Research will give the opening keynote at the conference. “I'll discuss in some detail two particular applications: the very efficient machine learning algorithms for doing collaborative filtering on massive sparse networks of users and products, like the Netflix network; and the inference algorithms on cancer genomic data to suggest possible drug targets for certain kinds of cancer,†explains Chayes.The post Jennifer Chayes from Microsoft Research to Keynote ISC 2017 appeared first on insideHPC.
|
 |
by Richard Friedman on (#2DP89)
Intel DAAL is a high-performance library specifically optimized for big data analysis on the latest Intel platforms, including Intel Xeon®, and Intel Xeon Phi™. It provides the algorithmic building blocks for all stages in data analysis in offline, batch, streaming, and distributed processing environments. It was designed for efficient use over all the popular data platforms and APIs in use today, including MPI, Hadoop, Spark, R, MATLAB, Python, C++, and Java.The post Intel DAAL Accelerates Data Analytics and Machine Learning appeared first on insideHPC.
|
 |
by staff on (#2DKG4)
"It is extremely important that customers using the Veloce emulation platform maximize the usability of their datacenter-based emulation resources," said Eric Selosse, vice president and general manager of the Mentor Emulation Division. "We've worked with Univa on a tight integration between Univa Grid Engine and the Veloce Enterprise Server App to streamline the workload management task."The post Mentor Graphics Adds Univa Grid Engine to Veloce Emulation Platform appeared first on insideHPC.
|
 |
by staff on (#2DK3X)
Today liquid-cooling technology provider Asetek announced that the company has signed a development agreement with a "major player" in the data center space. "This development agreement is the direct result of several years of collaboration and I am very pleased that we have come this far with our partner. I expect this is the major breakthrough we have been waiting for,†said André Sloth Eriksen, CEO and founder of Asetek.The post Asetek Enters Product Development Agreement with Major Datacenter Player appeared first on insideHPC.
|
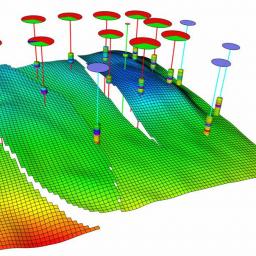 |
by Rich Brueckner on (#2DJQ2)
Today UK-based ebb3 announced that Emerson Automation Solutions is deploying high-performance software for the oil and gas industry virtually using ebb3’s remote visualization technology. "The Roxar reservoir management software has to handle very large models, and many models simultaneously for uncertainty analysis," Robert Frost, Product Development Manager at Emerson. "The more refined these are, the more graphical processing is required. This is one of the most challenging areas of virtualization, and virtual desktops with the power to support such high-powered graphics are almost unheard of. Along with the platform and partnership services that ebb3 provides, the power they’ve harnessed for virtual access to 3D visualization software is impressive. Being able to keep data in the data centre for fast access without compromising visualization and usability is a huge step forward.â€The post Emerson Roxar Applies ebb3 Remote Visualization for Oil & Gas appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2DJMV)
Hagen Toennies from Gaikai Inc. presented these Best Practices at the 2017 HPC Advisory Council Stanford Conference. "In this talk we will present how we enable distributed, Unix style programming using Docker and Apache Kafka. We will show how we can take the famous Unix Pipe Pattern and apply it to a Distributed Computing System."The post Video: Containerizing Distributed Pipes appeared first on insideHPC.
|
 |
by staff on (#2DJGM)
The Penn State Cyber-Laboratory for Astronomy, Materials, and Physics (CyberLAMP) is acquiring a high-performance computer cluster that will facilitate interdisciplinary research and training in cyberscience and is funded by a grant from the National Science Foundation. The hybrid computer cluster will combine general purpose central processing unit (CPU) cores with specialized hardware accelerators, including the latest generation of NVIDIA graphics processing units (GPUs) and Intel Xeon Phi processors.The post NSF Funds HPC Cluster at Penn State appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2DJ8D)
In this video from KAUST, Dan Stanzione, executive director of the Texas Advanced Computing Center, shares his insight on the future of high performance computing and the challenges faced by institutions as the demand for HPC, cloud and big data analysis grows. "Dr. Stanzione is the Executive Director of the Texas Advanced Computing Center (TACC) at The University of Texas at Austin. A nationally recognized leader in high performance computing, Stanzione has served as deputy director since June 2009 and assumed the Executive Director post on July 1, 2014."The post TACC’s Dan Stanzione on the Challenges Driving HPC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2DJEV)
Today DDN announced that it was once again ranked as the top storage provider among HPC sites surveyed by Intersect360 Research. “High-performance sites are incredibly challenging IT environments with massive data requirements across very diverse application and user types,†said Laura Shepard, senior director of product marketing, DDN. “Because we are a leader in this space, we have the expertise to provide the optimal solutions for traditional and commercial high-performance customers to ensure they are maximizing their compute investment with the right storage infrastructure.â€The post DDN Ranked #1 in HPC Storage Market appeared first on insideHPC.
|
 |
by staff on (#2DFEE)
Today One Stop Systems introduced an all-flash array Data Storage Unit. The Data Storage Unit is available in both a rugged version and a commercial version. The rugged version as deployed in a military aircraft is an all-flash array capable of supplying 200TB of usable PCIe NVMe flash and a DOD approved flash file system that has been a part of numerous government programs. "One Stop Systems' expertise in PCIe expansion has helped evolve our flash products from purely expansion systems to powerful all-flash arrays," said Steve Cooper, OSS CEO. "All-flash arrays have increasingly replaced traditional spinning disks in environments ranging from mobile devices to data centers and defense vehicles. Both the commercial and the rugged versions provide a new level of performance for applications such as real-time HPC analytics, big data and high speed data recording."The post One Stop Systems Rolls Out Rugged 4U All-Flash Array Data Storage Unit appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2DEPV)
In this video, Robert Brunner from NCSA presents: Blue Waters System Overview. "Blue Waters is one of the most powerful supercomputers in the world. Scientists and engineers across the country use the computing and data power of Blue Waters to tackle a wide range of challenging problems, from predicting the behavior of complex biological systems to simulating the evolution of the cosmos."The post Video: An Overview of the Blue Waters Supercomputer at NCSA appeared first on insideHPC.
|
 |
by staff on (#2DEF0)
In this RCE Podcast, Brock Palen and Jeff Squyres speak with the creators of SAGE2 Scalable Amplified Group Environment. SAGE2 is a browser tool to enhance data-intensive, co-located, and remote collaboration. "The original SAGE software, developed in 2004 and adopted at over one hundred international sites, was designed to enable groups to work in front of large shared displays in order to solve problems that required juxtaposing large volumes of information in ultra high-resolution. We have developed SAGE2, as a complete redesign and implementation of SAGE, using cloud-based and web-browser technologies in order to enhance data intensive co-located and remote collaboration."The post RCE Podcast Looks at SAGE2 Scalable Amplified Group Environment appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2DE9K)
"Increased system size and a greater reliance on utilizing system parallelism to achieve computational needs, requires innovative system architectures to meet the simulation challenges. As a step towards a new network class of co-processors intelligent network devices, which manipulate data traversing the data-center network, SHARP technology designed to offload collective operation processing to the network. This tutorial will provide an overview of SHARP technology, integration with MPI, SHARP software components and live example of running MPI collectives."The post Tutorial on In-Network Computing: SHARP Technology for MPI Offloads appeared first on insideHPC.
|
 |
by staff on (#2DE6S)
In this week’s Sponsored Post, Katie Garrison, of One Stop Systems explains how GPUs and Flash solutions are used in radar simulation and anti-submarine warfare applications. "High-performance compute and flash solutions are not just used in the lab anymore. Government agencies, particularly the military, are using GPUs and flash for complex applications such as radar simulation, anti-submarine warfare and other areas of defense that require intensive parallel processing and large amounts of data recording."The post GPUs and Flash in Radar Simulation and Anti-Submarine Warfare Applications appeared first on insideHPC.
|
|
by staff on (#2DB3B)
Missouri-based Advanced Clustering Technologies is helping customers solve challenges by integrating NVIDIA Tesla P100 accelerators into its line of high performance computing clusters. Advanced Clustering Technologies builds custom, turn-key HPC clusters that are used for a wide range of workloads including analytics, deep learning, life sciences, engineering simulation and modeling, climate and weather study, energy exploration, and improving manufacturing processes. "NVIDIA-enabled GPU clusters are proving very effective for our customers in academia, research and industry,†said Jim Paugh, Director of Sales at Advanced Clustering. “The Tesla P100 is a giant step forward in accelerating scientific research, which leads to breakthroughs in a wide variety of disciplines.â€The post NVIDIA Pascal GPUs come to Advanced Clustering Technologies appeared first on insideHPC.
|
 |
by staff on (#2DB0T)
Today UK-based Hammer PLC announced that it will be a distributer of Spectra Logic storage technology in Europe. "This is an excellent opportunity to increase our high-performance computing offering to our partners and customers," said Jason Beeson, Hammer’s Commercial Director. "By adding Spectra Logic’s bespoke data workflow storage solutions we can reach a whole new genre of highly data-dependent users who are seeking a complete data workflow, from input and day-to-day use right through to deep storage and archiving.â€The post Hammer PLC to Distribute Spectra Logic Storage in Europe appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2DAWK)
In this video from KAUST, Steve Scott from at Cray explains where supercomputing is going and why there is a never-ending demand for faster and faster computers. Responsible for guiding Cray's long term product roadmap in high-performance computing, storage and data analytics, Mr. Scott is chief architect of several generations of systems and interconnects at Cray.The post Interview: Cray’s Steve Scott on What’s Next for Supercomputing appeared first on insideHPC.
|
|
by Rich Brueckner on (#2DAPB)
In this podcast, the Radio Free HPC team hosts Dan’s daughter Elizabeth. How did Dan get this way? We’re on a mission to find out even as Elizabeth complains of the early onset of Curmudgeon's Syndrome. After that, we take a look at the Tsubame3.0 supercomputer coming to Tokyo Tech.The post Radio Free HPC Gets the Scoop from Dan’s Daughter in Washington, D.C. appeared first on insideHPC.
|
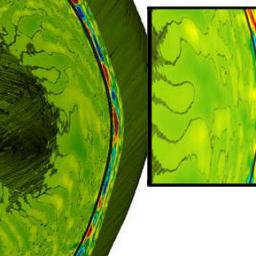 |
by Rich Brueckner on (#2D80P)
When the DOE's pre-exascale supercomputers come online soon, all three will be running an optimized version of the XGC dynamic fusion code. Developed by a team at the DOE's Princeton Plasma Physics Laboratory (PPPL), the XGC code was one of only three codes out of more than 30 science and engineering programs selected to participate in Early Science programs on all three new supercomputers, which will serve as forerunners for even more powerful exascale machines that are to begin operating in the United States in the early 2020s.The post XGC Fusion Code Selected for all 3 Pre-exascale Supercomputers appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2D7WV)
In this fascinating talk, Cockcroft describes how hardware networking has reshaped how services like Machine Learning are being developed rapidly in the cloud with AWS Lamda. "We've seen the same service oriented architecture principles track advancements in technology from the coarse grain services of SOA a decade ago, through microservices that are usually scoped to a more fine grain single area of responsibility, and now functions as a service, serverless architectures where each function is a separately deployed and invoked unit."The post Adrian Cockcroft Presents: Shrinking Microservices to Functions appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2D4Y8)
Industry and academic institutions are invited to showcase their R&D at PASC17, an interdisciplinary event in high performance computing that brings together domain science, applied mathematics and computer science. The event takes place June 26-28 in Lugano, Switzerland. "The PASC17 Conference offers a unique opportunity for your organization to gain visibility at a national and international level, to showcase your R&D and to network with leaders in the fields of HPC simulation and data science. PASC17 builds on a successful history – with 350 attendees in 2016 – and continues to expand its program and international profile year on year."The post Call for Exhibitors: PASC17 in Lugano appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2D4VX)
Addison Snell presented this deck at the Stanford HPC Conference. "Intersect360 Research returns with an annual deep dive into the trends, technologies and usage models that will be propelling the HPC community through 2017 and beyond. Emerging areas of focus and opportunities to expand will be explored along with insightful observations needed to support measurably positive decision making within your operations."The post Addison Snell Presents: HPC Computing Trends appeared first on insideHPC.
|
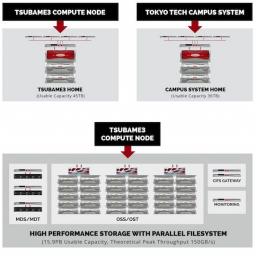 |
by staff on (#2D1C1)
"The IO infrastructure of TSUBAME3.0 combines fast in-node NVMe SSDs and a large, fast, Lustre-based system from DDN. The 15.9PB Lustre* parallel file system, composed of three of DDN’s high-end ES14KX storage appliances, is rated at a peak performance of 150GB/s. The TSUBAME collaboration represents an evolutionary branch of HPC that could well develop into the dominant HPC paradigm at about the time the most advanced supercomputing nations and consortia achieve Exascale computing."The post DDN and Lustre to Power TSUBAME3.0 Supercomputer appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2D1M8)
In this video, Dr Tim Stitt from the Earlham Institute describes why moving their HPC workload to Iceland made economic sense. Through the Verne Global datacenter, the Earlham Institute will have access to one of the world’s most reliable power grids producing 100% geothermal and hydro-electric renewable energy. As EI’s HPC analysis requirements continue to grow, Verne Global will enable the institute to save up to 70% in energy costs (based on 14p to 4p KWH rate and with no additional power for cooling, significantly benefiting the organization in their advanced genomics and bioinformatics research of living systems.The post Earlham Institute Moves HPC Workloads to Iceland appeared first on insideHPC.
|
 |
by staff on (#2D1DY)
Today Dutch startup Asperitas rolled out Immersed Computing cooling technology for datacenters. "The company's first market ready solution, the AIC24, 'the first water-cooled oil-immersion system which relies on natural convection for circulation of the dielectric liquid.' This results in a fully self-contained and Plug and Play modular system. The AIC24 needs far less infrastructure than any other liquid installation, saving energy and costs on all levels of datacentre operations. The AIC24 is the most sustainable solution available for IT environments today. Ensuring the highest possible efficiency in availability, energy reduction and reuse, while increasing capacity. Greatly improving density, while saving energy at the same time."The post Asperitas Startup Brings Immersive Cooling to Datacenters appeared first on insideHPC.
|
 |
by staff on (#2D15Z)
"TSUBAME3.0 is expected to deliver more than two times the performance of its predecessor, TSUBAME2.5," writes Marc Hamilton from Nvidia. "It will use Pascal-based Tesla P100 GPUs, which are nearly three times as efficient as their predecessors, to reach an expected 12.2 petaflops of double precision performance. That would rank it among the world’s 10 fastest systems according to the latest TOP500 list, released in November. TSUBAME3.0 will excel in AI computation, expected to deliver more than 47 PFLOPS of AI horsepower. When operated concurrently with TSUBAME2.5, it is expected to deliver 64.3 PFLOPS, making it Japan’s highest performing AI supercomputer."The post Pascal GPUs to Accelerate TSUBAME 3.0 Supercomputer at Tokyo Tech appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2D14E)
"Servers today have hundreds of knobs that can be tuned for performance and energy efficiency. While some of these knobs can have a dramatic effect on these metrics, manually tuning them is a tedious task. It is very labor intensive, it requires a lot of expertise, and the tuned settings are only relevant for the hardware and software that were used in the tuning process. In addition to that, manual tuning can't take advantage of application phases that may each require different settings. In this presentation, we will talk about the concept of dynamic tuning and its advantages. We will also demo how to improve performance using manual tuning as well as dynamic tuning using DatArcs Optimizer."The post Video: The Era of Self-Tuning Servers appeared first on insideHPC.
|
 |
by staff on (#2CXMS)
"This breakthrough has unlocked new potential for ExxonMobil's geoscientists and engineers to make more informed and timely decisions on the development and management of oil and gas reservoirs," said Tom Schuessler, president of ExxonMobil Upstream Research Company. "As our industry looks for cost-effective and environmentally responsible ways to find and develop oil and gas fields, we rely on this type of technology to model the complex processes that govern the flow of oil, water and gas in various reservoirs."The post Exxon Mobil and NCSA Achieve New Levels of Scalability on complex Oil & Gas Reservoir Simulation Models appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2CXK0)
SC17 has issued its Call for Panel Sessions. The conference takes place Nov. 12-17 in Denver. "As in past years, panels at SC17 will be some of the most heavily attended events of the Conference. Panels will bring together the key thinkers and producers in the field to consider in a lively and rapid-fire context some of the key questions challenging high performance computing, networking, storage and associated analysis technologies for the foreseeable future."The post Call for Panels: SC17 in Denver appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2CXEH)
"In recent years, major breakthroughs were achieved in different fields using deep learning. From image segmentation, speech recognition or self-driving cars, deep learning is everywhere. Performance of image classification, segmentation, localization have reached levels not seen before thanks to GPUs and large scale GPU-based deployments, leading deep learning to be a first class HPC workload."The post Deep Learning & HPC: New Challenges for Large Scale Computing appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2CXC7)
Today ISC 2017 announced that it's Distinguished Talk series will focus on Data Analytics in manufacturing and scientific applications. One of the Distinguished Talks will be given by Dr. Sabine Jeschke from the Cybernetics Lab at the RWTH Aachen University on the topic of, “Robots in Crowds – Robots and Clouds.†Jeschke’s presentation will be followed by one from physicist Kerstin Tackmann, from the German Electron Synchrotron (DESY) research center, who will discuss big data and machine learning techniques used for the ATLAS experiment at the Large Hadron Collider.The post ISC 2017 Distinguished Talks to Focus on Data Analytics in Manufacturing & Science appeared first on insideHPC.
|
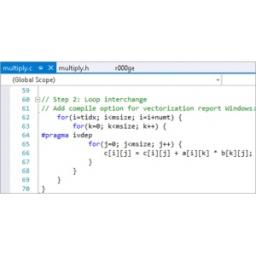 |
by MichaelS on (#2CX6J)
"As with all new technology, developers will have to create processes in order to modernize applications to take advantage of any new feature. Rather than randomly trying to improve the performance of an application, it is wise to be very familiar with the application and use available tools to understand bottlenecks and look for areas of improvement."The post Six Steps Towards Better Performance on Intel Xeon Phi appeared first on insideHPC.
|
 |
by staff on (#2CTS8)
"Machine Learning and deep learning represent new frontiers in analytics. These technologies will be foundational to automating insight at the scale of the world’s critical systems and cloud services,†said Rob Thomas, General Manager, IBM Analytics. “IBM Machine Learning was designed leveraging our core Watson technologies to accelerate the adoption of machine learning where the majority of corporate data resides. As clients see business returns on private cloud, they will expand for hybrid and public cloud implementations.â€The post IBM Machine Learning Platform Comes to the Private Cloud appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2CSMG)
"In this guide, we take a high-level view of AI and deep learning in terms of how it’s being used and what technological advances have made it possible. We also explain the difference between AI, machine learning and deep learning, and examine the intersection of AI and HPC. We also present the results of a recent insideBIGDATA survey to see how well these new technologies are being received. Finally, we take a look at a number of high-profile use case examples showing the effective use of AI in a variety of problem domains."The post Defining AI, Machine Learning, and Deep Learning appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2CSH9)
"Coursera has named Intel as one of its first corporate content partners. Together, Coursera and Intel will develop and distribute courses to democratize access to artificial intelligence and machine learning. In this interview, Ibrahim talks about her and Coursera's history, reports on Coursera's progress delivering education at massive scale, and discusses Coursera and Intel's unique partnership for AI."The post Podcast: Democratizing Education for the Next Wave of AI appeared first on insideHPC.
|