
 |
by staff on (#2GPWM)
Today Penguin Computing announced a significant expansion of their Penguin Computing On-Demand (POD) High Performance Computing Cloud. The new offering includes the latest Intel Xeon processorss, Lustre, and Intel Omni-Path. "As current Penguin POD users, we are excited to have more resources available to handle our mission-critical real-time global environmental prediction workload,†said Dr. Greg Wilson, CEO, EarthCast Technologies. “The addition of the Lustre file system will allow us to scale our applications to full global coverage, run our jobs faster and provide more accurate predictions.â€The post Penguin Computing Adds Omni-Path and Lustre to its HPC Cloud appeared first on insideHPC.
|
| Link | http://insidehpc.com/ |
| Feed | http://insidehpc.com/feed/ |
| Updated | 2026-06-20 01:45 |
 |
by Rich Brueckner on (#2GPTP)
We are sad to report that HPC vendor Scalable Informatics has gone out of business. Headed up by CEO Joe Landman, Scalable Informatics spent the last 12 years building 'Simply Faster" software-defined storage and compute solutions to the financial, research, scientific, and big data analysis markets. "There are days when this reporter wishes he wasn't in the news business. Today is one of those days."The post Scalable Informatics Closes Down their Shop appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2GPN6)
"Marketing is important in good times, but it can be even more important in bad times. If you have the means to invest in marketing, then do it now. Invest, because there will be many others who will hold onto funds until there is more certainty on 2018 budget spend from the US government. If you are one of the few investing in marketing, your voice will be heard while others are silently standing by."The post Federal Budgets Cuts for HPC? How to Gain Market Share in an Uncertain Market appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2GK60)
Today SuperMicro rolled out a wide range of NVMe Flash server and storage systems with support for the new Intel Optane SSD DC P4800X based on 3D XPoint technology. "Being First-To-Market with the latest in computing technology continues to be our corporate strength, the addition of Intel Optane memory technology gives our top tier customers a new memory deployment strategy that provides better write performance and latency than existing NVMe NAND SSD solutions,†said Charles Liang, President and CEO of Supermicro. “In addition this new memory is slated to consume 30 percent lower max-power than SSD NAND memory, supporting our customer’s green computing priorities.â€The post Supermicro Rolls Out Intel Optane SSD Platforms appeared first on insideHPC.
|
 |
by staff on (#2GK4N)
Researchers using the SuperMUC cluster in Germany have discovered a set of unknown species in rainforest soils. As described in a new paper published in Nature Ecology and Evolution, their study on microbial diversity in tropical rainforests required over one million CPU hours to complete. "Without the outstanding high performance computing infrastructure in Germany and especially at LRZ, this study would not have been feasible. The availability of SuperMUC constitutes an essential national advantage in the international scientific competition," states Alexandros Stamatakis.The post SuperMUC Helps Discover New Species Critical to Rainforest Ecosystems appeared first on insideHPC.
|
 |
by staff on (#2GJXZ)
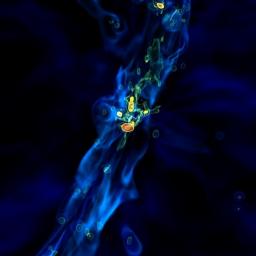
Supermassive black holes have a speed limit that governs how fast and how large they can grow,†said Joseph Smidt of the Theoretical Design Division at LANL. Using computer codes developed at Los Alamos for modeling the interaction of matter and radiation related to the Lab’s stockpile stewardship mission, Smidt and colleagues created a simulation of collapsing stars that resulted in supermassive black holes forming in less time than expected, cosmologically speaking, in the first billion years of the universe.The post Supercomputing the Black Hole Speed Limit appeared first on insideHPC.
|
 |
by staff on (#2GJY1)
“Bret Costelow is an inspiring sales leader with a clear understanding of our customers’ needs and a vision of how DDN’s technologies and solutions can best solve their toughest data storage challenges,†said Robert Triendl, senior vice president, global sales, marketing, and field services, DDN. “Bret’s proven success in high-growth business settings, deep knowledge of the Lustre* and HPC market, proven track record for generating traction with innovative, advanced technologies, and his broad experience with software sales make him a great asset to our team and a great resource for our partners and customers around the world.â€The post DDN Names Bret Costelow VP of Global Sales appeared first on insideHPC.
|
 |
by staff on (#2GJVB)
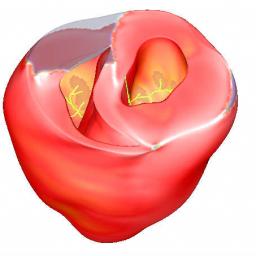
The Allinea Forge parallel code development suite is helping to speed up exciting computational cardiology research at the Medical University of Graz. "Utilizing the power of the VSC-3 supercomputer at the University of Vienna, Postdoctoral researcher Dr. Aurel Neic and his team are developing a simulation framework for the human heart called the Cardiac Arrythmia Research Package (CARP). It replicates the electric, mechanic and haemodynamic (the forces associated with the flow of blood) phenomena in the heart in a coupled manner and is bringing exciting new possibilities to medical science."The post Allinea Software Powers Heart Simulation Framework appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2GFVD)
"Artificial Intelligence will deliver the next wave of societal transformation on parallel with the industrial, technical and internet revolutions that preceded it. As our AI-fueled future evolves, we have a tremendous opportunity to address opportunities from scare resource utilization and scientific exploration to inclusion and human rights expansion. Intel Executive VP Diane Bryant will share Intel’s vision for unleashing AI as well as a perspective on how to accelerate the delivery of #AIforgood."The post Intel’s Diane Bryant on How AI Will Change Lives appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2GFGY)
Today Mellanox introduced a new line of 200Gb/s silicon photonics and VCSEL-based transceivers in the same QSFP28 package as today’s 100Gb/s products. These new transceivers double the bandwidth for hyperscale Web 2.0 and cloud 100Gb/s networks. Mellanox is also introducing 200Gb/s Active Optical Cables (AOCs) and Direct Attach Copper Cables (DACs), including breakout cables, to […]The post Mellanox Doubles Silicon Photonics Ethernet Transceiver Speeds to 200Gb/s appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2GFDJ)
Earlier this month, the European PRACE initiative went into Phase 2, with Switzerland becoming a new Hosting Member. As a Hosting Member, Switzerland is now making its Piz Daint supercomputer at CSCS available for cutting-edge PRACE research. The other Hosting Members are Spain, Italy, Germany and France.The post PRACE 2 Adds Piz Daint Supercomputer appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2GF7E)
PEARC17 provides students with a range of opportunities in the Technical Program and in targeted student activities. For all student attendees, PEARC17 will include a one-day intensive collaborative modeling and analysis challenge; a session on careers in modeling and large data analytics; a mentorship program; and opportunities for students to volunteer to assist with conference activities. Participation from traditionally under-represented communities including women, minorities, and people with disabilities, is strongly encouraged.The post Apply Now for the PEARC17 Student Program appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2GF5Z)
In this podcast, Radio Free HPC looks at a recent report that the USA needs to take aggresive action to keep up with China in High Performance Computing. Produced by the NSA-DOE Technical Meeting on High Performance Computing, the report states that we need to change course now or the U.S. will lose leadership and not control its own future in HPC.The post Does the US Need to Change Course to Compete with China in HPC? appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2GCJ2)
"Delivering an industry-leading combination of low latency, ultra endurance, high QoS, and high throughput, the Intel Optane SSD DC P4800X Series is the most responsive data center SSD. Built with the revolutionary new 3D XPoint memory media, the SSD DC P4800X is the first product to combine the attributes of memory and storage. This innovative solution is optimized to break through storage bottlenecks by providing a new data tier."The post Intel Rolls Out First Optane SSD with 3D XPoint Technology appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2GCEK)
"SC17 is excited to hold another nail-biting Student Cluster Competition, or SCC, now in its eleventh year, as an opportunity to showcase student expertise in a friendly yet spirited competition. Held as part of SC17’s Students@SC, the Student Cluster Competition is designed to introduce the next generation of students to the high-performance computing community."The post Video Preview of the SC17 Student Cluster Competition appeared first on insideHPC.
|
 |
by Richard Friedman on (#2GA3A)
When used in a TBB environment, Intel has demonstrated a many-fold performance improvement over the same parallelized code using Intel MKL in an OpenMP environment. Intel TBB-enabled Intel MKL is ideal when there is heavy threading in the Intel TBB application. Intel TBB-enabled Intel MKL shows solid performance improvements through better interoperability with other parts of the workload.The post Intel MKL and Intel TBB Working Together for Performance appeared first on insideHPC.
|
 |
by staff on (#2G9QS)
Today NEC Corporation announced the deployment of an LX supercomputer at RWTH Aachen University in Germany. Featuring offering high performance computing services for engineering and scientific research. "We selected the NEC LX technology because of its superior performance, as well as low total cost of ownership due to innovative cooling technology," said Professor Matthias Muller, head of the IT Center at RWTH Aachen University. "Going forward, we are excited to work with NEC as a strong corporate partner in expanding our IT research."The post RWTH Aachen University Deploys NEC LX Supercomputer appeared first on insideHPC.
|
 |
by staff on (#2G9Q2)
Today Hewlett Packard Enterprise announced plans to deploy one of the world’s largest supercomputers for industrial chemical research at BASF's Ludwigshafen headquarters. Based on the latest generation of HPE Apollo 6000 systems, the new supercomputer will drive the digitalization of BASF's worldwide research. “The new supercomputer will promote the application and development of complex modeling and simulation approaches, opening up completely new avenues for our research at BASF,†said Dr. Martin Brudermueller, Vice Chairman of the Board of Executive Directors and Chief Technology Officer at BASF.The post HPE Supercomputer to Power Chemical Research at BASF appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2G6FA)
In this video from The Good Stuff program, Katherine Riley and Argonne National Laboratory describes what a supercomputer really is and how Argonne uses high performance computing to solve the world's most challenging problems. "This is a great program for explaining HPC to your friends, neighbors, and even your kids."The post Video: How Smart is a Supercomputer? appeared first on insideHPC.
|
 |
by staff on (#2G6DT)
"The OpenFabrics Alliance (OFA) workshop is an annual event devoted to advancing the state of the art in networking. The workshop is known for showcasing a broad range of topics all related to network technology and deployment through an interactive, community-driven event. The comprehensive event includes a rich program made up of more than 50 sessions covering a variety of critical networking topics, which range from current deployments of RDMA to new and advanced network technologies."The post OFA Workshop in Austin to Put Spotlight on InfiniBand and RoCE appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2G6C2)
The 2nd International Workshop on Performance Portable Programming Models for Accelerators (P^3MA) has issued its Call for Papers. He held in conjunction with ISC 2017, the event takes place June 22 in Frankfurt, Germany.The post Call for Papers: 2nd International Workshop on Performance Portable Programming Models for Accelerators appeared first on insideHPC.
|
 |
by staff on (#2G6A9)
Los Alamos National Laboratory has donated a decommissioned supercomputer to the University of New Mexico Center for Advanced Research Computing. The machine was acquired through the NSF-sponsored PR0bE project, which is run by the New Mexico Consortium.The post LANL Donates Supercomputer to University of New Mexico appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2G65H)
On Thursday, the U.S.-China Economic & Security Review Commission (USCC) held a hearing on the current and potential future state of supercomputing innovation worldwide, with an emphasis on China’s position on the global stage relative to the USA. Addison Snell from Intersect360 Research provided this testimony in answer to USCC’s questions for the hearing.The post Intersect360 Research Testimony on China’s Pursuit of HPC World Domination appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2G38F)
"The Project Olympus hyperscale GPU accelerator chassis for AI, also referred to as HGX-1, is designed to support eight of the latest “Pascal†generation NVIDIA GPUs and NVIDIA’s NVLink high speed multi-GPU interconnect technology, and provides high bandwidth interconnectivity for up to 32 GPUs by connecting four HGX-1 together. The HGX-1 AI accelerator provides extreme performance scalability to meet the demanding requirements of fast growing machine learning workloads, and its unique design allows it to be easily adopted into existing datacenters around the world."The post Overview of the HGX-1 AI Accelerator Chassis appeared first on insideHPC.
|
 |
by staff on (#2G2MZ)
Today D-Wave Systems announced that Google, NASA, and Universities Space Research Association (USRA) have elected to upgrade to the new D-Wave 2000Q system. The upgraded system will support research on how quantum computing can be applied to artificial intelligence, machine learning, and difficult optimization problems. The new system will be the third generation of D-Wave technology installed at Ames,†said D-Wave CEO Vern Brownell. “We are pleased that Google, NASA, and USRA value the increased performance embodied in our latest generation of technology, the D-Wave 2000Q system, for their critical applications.â€The post Quantum Artificial Intelligence Lab to Install D-Wave 2000Q System appeared first on insideHPC.
|
 |
by staff on (#2G2N0)
Today the Ethernet Alliance announced plans of details of its upcoming OFC 2017 interoperability demo featuring the full spectrum of Ethernet speeds from 1 Gigabit (1G) to 400 Gigabit (400G). "It’s an incredibly exciting time in the industry as investments in next-generation Ethernet standards are coming to fruition. Our members – including equipment manufacturers, system and component vendors, test and measurement, and everyone else in-between – are developing the solutions that will enable these standards,†said John D’Ambrosia, chairman, Ethernet Alliance; and senior principal engineer, Huawei.The post Ethernet Alliance to Demo 400G Networks at OFC 2017 appeared first on insideHPC.
|
 |
by staff on (#2G2KX)
Over at the SUSE Blog, Jay Kruemcke writes that the High-Performance Computing Module (HPC Module) for SUSE Linux Enterprise (SLES) is now available for 64-bit ARM (AArch64) systems. The HPC Module is delivered as an add-on product to SUSE Linux Enterprise Server. "In summary, the HPC module allows us to keep the content closer to what’s happening in the HPC community upstream, providing more leading-edge tools in a more manageable fashion, leveraging a different lifecycle than the base SUSE Linux Enterprise Server. The new HPC module contains packages to optimize and manage HPC systems, and build HPC applications – building a bridge between the base server and an HPC stack (such as the stack provided by OpenHPC). This journey has started – some packages have already been made public and we have much more in the works and in our release queue."The post SUSE Adds HPC Module for ARM-based Systems appeared first on insideHPC.
|
 |
by MichaelS on (#2G2H3)
"In order for developers to be able to focus on their application, a Vision Algorithm Designer application is included in the Intel Computer Vision SDK. This gives users a drag and drop interface that allows them to create new applications on the fly. Large and complex workflows can be modelled visually which takes the guesswork out of bringing together many different functions. In addition, customized code can be added to the workflows."The post Creating Applications with the Intel Computer Vision SDK appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2FZY9)
"In 2013, Western Digital acquired flash storage hardware and software supplier, Virident, for $685 million in cash. They followed that up in May 2016, with the acquisition of SanDisk Corporation. The addition of SanDisk makes Western Digital Corporation a comprehensive storage solutions provider with global reach, and an extensive product and technology platform that includes deep expertise in both rotating magnetic storage and non-volatile memory (NVM)."The post Video: SSD – The Transition from 2D to 3D NAND appeared first on insideHPC.
|
 |
by staff on (#2FZ12)
Altair will host the PBS Works User Group May 22-25 in Las Vegas. This four-day event (including 2 days of user presentations, round table discussions and surrounded by hands-on workshops) is the global user event of the year for PBS Professional and other PBS Works products. "This year we are excited to announce that we will be hosting a tour of the Switch data center facility on Tuesday afternoon."The post PBS Works User Group comes to Las Vegas May 22-25 appeared first on insideHPC.
|
 |
by staff on (#2FYWF)
Today ISC 2017 announced a day-long Deep Learning track on June 21 as part of its technical program. The full conference takes place June 18-21 in Frankfurt, Germany. "The overwhelming success of deep learning has triggered a race to build larger artificial neural networks, using growing amounts of training data in order to allow computers to take on more complex tasks. Such work will challenge the computational feasibility of deep learning of this magnitude, requiring massive data throughput and compute power. Hence, implementing deep learning at scale has become an emerging topic for the high performance computing community."The post Day-Long Deep Learning Track Comes to ISC 2017 appeared first on insideHPC.
|
 |
by staff on (#2FYTC)
The majority of SDSC’s data-intensive Gordon supercomputer will be used by Simons for ongoing research following completion of the system’s tenure as an NSF resource on March 31."We are delighted that the Simons Foundation has given Gordon a new lease on life after five years of service as a highly sought after XSEDE resource,†said SDSC Director Michael Norman, who also served as the principal investigator for Gordon. “We welcome the Foundation as a new partner and consider this to be a solid testimony regarding Gordon’s data-intensive capabilities and its myriad contributions to advancing scientific discovery.â€The post Flatiron Institute to Repurpose Gordon Supercomputer appeared first on insideHPC.
|
 |
by staff on (#2FYPX)
James Reinders discusses one of the “mode†options that Intel Xeon Phi processors have to offer: memory modes. "For programmers, this is the key option to really study because it may inspire programming changes."The post Intel Xeon Phi Memory Mode Programming (MCDRAM) in a Nutshell appeared first on insideHPC.
|
 |
by staff on (#2FVE7)
Today vScaler announced plans to showcase their HPC cloud platform March 15-16 at the upcoming Cloud Expo Europe Conference in London. Supported by two of its strategic technology partners - Aegis Data and Global Cloud Xchange, vScaler will showcase its application specific cloud platform, with experts on hand to discuss use cases such as HPC, Broadcast & Media, Big Data, Finance and Storage, as well as data centre innovation and co-location. "We provide full application stacks for a range of verticals as well as on-demand consultancy from our expert team," said David Power, vScaler CTO. “Our tailor-made, software-defined infrastructure cuts away time wasted on the distractions of setup and enables our users to concentrate on the task at hand.â€The post vScaler to Showcase OpenHPC & Deep Learning at Cloud Expo Europe 2017 appeared first on insideHPC.
|
 |
by staff on (#2FV6X)
Today D-Wave Systems and Virginia Tech announced a joint effort to provide greater access to quantum computers for researchers from the Intelligence Community and Department of Defense. D-Wave and Virginia Tech will work towards the creation of a permanent quantum computing center to house a D-Wave system at the Hume Center for National Security and Technology. "Both D-Wave and Virginia Tech recognize how vital it is that quantum computing be accessible to a broad community of experts focused on solving real-world problems," said Bo Ewald, president of D-Wave International. "One of the many reasons we chose to work with Virginia Tech is their strong relationships with the intelligence and defense communities. A key area of focus will be to work with federal agencies towards the creation of a quantum computing center at the Hume Center."The post D-Wave Collaborates with Virginia Tech on Quantum Computing appeared first on insideHPC.
|
 |
by staff on (#2FV37)
"DDN’s unique ability to handle tough application I/O profiles at speed and scale gives weather and climate organizations the infrastructure they need for rapid, high-fidelity modeling,†said Laura Shepard, senior director of product marketing, DDN. “These capabilities are essential to DDN’s growing base of weather and climate organizations, which are at the forefront of scientific research and advancements – from whole climate atmospheric and oceanic modeling to hurricane and severe weather emergency preparedness to the use of revolutionary, new, high-resolution satellite imagery in weather forecasting.â€The post Top Weather and Climate Sites run on DDN Storage appeared first on insideHPC.
|
 |
by staff on (#2FTVK)
Next-generation sequencing (NGS) tools produce vast quantities of genetic data which poses a growing number of challenges to life sciences organizations. Accelerating analytics, providing adequate storage and memory capacity, speeding time-to-solution, and reducing costs are major concerns for IT department operating on traditional computing systems. In this week’s Sponsored Post, Bill Mannel, Vice President & General Manager of HPC Segment Solutions and Apollo Servers, Data Center Infrastructure Group at Hewlett Packard Enterprise, explains how next-generation sequencing is altering the patient care landscape.The post Next-Generation Sequencing Altering the Patient Care Landscape appeared first on insideHPC.
|
 |
by staff on (#2FTR6)
Altair just released HyperWorks 2017, the "most comprehensive, open architecture CAE simulation platform in the industry, offering the best technologies to design and optimize high performance, weight efficient and innovative products. "HyperWorks 2017 adds key enhancements to the modeling and assembly capabilities of the software,†said James P. Dagg, Chief Technical Officer, User Experience at Altair. “Users can now communicate directly with their enterprise PLM system, storing libraries of parts and configurations of their models. Tasks like setting up a model with multiple configurations for different disciplines can now be done in minutes.â€The post Altair Releases HyperWorks 2017 Comprehensive Simulation Platform appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2FRDS)
Applications are now being accepted for the Women in IT Networking at SC (WINS) program at SC17. The conference takes place Nov. 12-17 in Denver. "The WINS program seeks qualified female U.S. candidates in their early to mid-career to join the SCinet volunteer team to help build and operate SCinet for SC17. Selected candidates will receive full travel support and mentoring by well-known engineering experts in the research and education community."The post Women in IT: Apply for WINS Program at SC17 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2FR80)
Accelerated computing continues to gain momentum. This year the GPU Technology Conference will feature 90 sessions on HPC and Supercomputing. "Sessions will focus on how computational and data science are used to solve traditional HPC problems in healthcare, weather, astronomy, and other domains. GPU developers can also connect with innovators and researchers as they share their groundbreaking work using GPU computing."The post GTC to Feature 90 Sessions on HPC and Supercomputing appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2FQYT)
Today Fujitsu announced plans to establish a coordination center within the RIKEN Center for Advanced Intelligence Project (AIP). Scheduled to open April 1, the RIKEN AIP-Fujitsu Collaboration Center will combine RIKEN AIP’s knowledge of cutting-edge technology in the artificial intelligence field with Fujitsu’s experience developing AI-related technologies based on its customer platforms. The aim is […]The post RIKEN AIP-Fujitsu Collaboration Center to Focus on Next-Gen AI appeared first on insideHPC.
|
 |
by staff on (#2FQTZ)
The 2017 FLOW-3D Americas Users Conference has issued its Call for Abstracts. The event takes place Sept. 20-21 in Santa Fe, NM. "The call for abstracts for is now open. Share your experiences, present your success stories and obtain valuable feedback from your fellow CFD practitioners and Flow Science staff. The deadline to submit an abstract is Friday, August 4. The conference proceedings will be made available to attendees as well as through the Flow Science website."The post Call for Abstracts: FLOW-3D Americas Users Conference appeared first on insideHPC.
|
 |
by staff on (#2FQSD)
"2017 will see the introduction of many technologies that will help shape the future of HPC systems. Production-scale ARM supercomputers, advancements in memory and storage technology such as DDN’s Infinite Memory Engine (IME), and much wider adoption of accelerator technologies and from Nvidia, Intel and FPGA manufacturers such as Xilinx and Altera, are all helping to define the supercomputers of tomorrow."The post Future Technologies on the Rise for HPC appeared first on insideHPC.
|
|
by Rich Brueckner on (#2FQE6)
In this podcast, the Radio Free HPC team looks at a set of IT and Science stories. Microsoft Azure is making a big move to GPUs and the OCP Platform as part of their Project Olympus. Meanwhile, Huawei is gaining market share in the server market and IBM is bringing storage to the atomic level.The post Radio Free HPC Looks at Azure’s Move to GPUs and OCP for Deep Learning appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2FMTF)
"Cybersecurity is a cat-and-mouse game where the mouse always has long had the upper hand because it’s so easy for new malware to go undetected. Dr. Eli David, an expert in computational intelligence and CTO of Deep Instinct, wants to use AI to change that, bringing the GPU-powered deep learning techniques underpinning modern speech and image recognition to the vexing world of cybersecurity."The post Podcast: Using GPUs and AI to Fight Cybercrime appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2FMQT)
Scott Callaghan from the Southern California Earthquake Center presented this talk as part of the Blue Waters Webinar Series. "I will present an overview of scientific workflows. I'll discuss what the community means by "workflows" and what elements make up a workflow. We'll talk about common problems that users might be facing, such as automation, job management, data staging, resource provisioning, and provenance tracking, and explain how workflow tools can help address these challenges. I'll present a brief example from my own work with a series of seismic codes showing how using workflow tools can improve scientific applications."The post Video: Overview of Scientific Workflows appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2FHWY)
The Data Science with Spark Workshop addresses high-level parallelization for data analytics workloads using the Apache Spark framework. Participants will learn how to prototype with Spark and how to exploit large HPC machines like the Piz Daint CSCS flagship system.The post Introduction to Data Science with Spark appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2FHV7)
The Alibaba Cloud has announced a pilot program with Intel for a cloud-based FPGA acceleration service with the goal of enabling customers to have virtual access to powerful compute resources in the cloud to help them manage business, scientific and enterprise data application workloads more effectively. “This service greatly adds to our value as a leading provider of highly scalable cloud computing and data management services that provide businesses with flexible, reliable connectivity.â€The post Accelerating the Alibaba Cloud with Intel Arria 10 FPGAs appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2FEV5)
In this video, Ricard Borrell from the Barcelona Supercomputing Center describes how the Mont Blanc Project Industrial End User Group on TermoFluids is advancing HPC on ARM-based platforms.The post Video: Mont-Blanc Project Advances HPC for TermoFluids appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2FEQM)
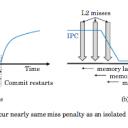
A new paper from IIT Hyderabad in India surveys cache partitioning techniques for multicore processors. Now accepted in ACM Computing Surveys 2017, the survey by Sparsh Mittal reviews 90 papers. "As the number of on-chip cores and memory demands of applications increase, judicious management of cache resources has become imperative. Cache partitioning is a promising approach to provide capacity benefits of shared cache with performance isolation of private caches. This paper reviews various cache partitioning techniques, e.g., strict/psuedo, static/dynamic, hardware/software-based, block/set/way-based, for improving performance/fairness/load-balancing/QoS, etc."The post New Paper Surveys Cache Partitioning Techniques appeared first on insideHPC.
|