
 |
by Rich Brueckner on (#2J0X8)
Today Adaptive Computing announces the latest release of Moab HPC Suite and related add-ons. The new release extends ease-of-use submission and workload management to new platforms by delivering a release of Viewpoint that can now work directly with either Torque or Slurm. Because of this “Open Platform†extension, other related products now automatically work with either resource manager, including remote visualization, submissions of high throughput workloads (Nitro enables tens of thousands to millions of tasks), and use of Adaptive Computing’s new Reporting & Analytics solution.The post Adaptive Computing Releases Moab HPC Suite 9.1.1 appeared first on insideHPC.
|
| Link | http://insidehpc.com/ |
| Feed | http://insidehpc.com/feed/ |
| Updated | 2026-06-20 01:45 |
 |
by Rich Brueckner on (#2J0Q6)
Todd Rimmer from Intel presented this talk at the OpenFabrics Workshop. “Intel Omni-Path was first released in early 2016. Omni-Path host and management software is all open sourced. This session will provide an overview of Omni-Path including some of the technical capabilities and performance results as well as some recent industry results.â€The post Video: Omni-Path Status, Upstreaming, and Ongoing Work appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2J0J3)
In this podcast, the Radio Free HPC team looks at the week's top stories: Quantum Startup Rigetti Computing Raises $64 Million in Funding, Rex Computing has their low-power chip, and Intel is shipping their Optane SSDs.The post Radio Free HPC Looks at Quantum Startup Rigetti Computing appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2HXT0)
The International Conference on HPC & Simulation has issued its Call for Papers. Also known as HPBench, the event place in July 17-21 in Genoa, Italy. "Benchmarking is an essential aspect of modern computational science, and as such, it provides a means for quantifying and comparing the performance of different computer systems. With a large combination of aspects to benchmark, all the way from the capability of a single core, to cluster configuration, and to various software configurations, the benchmarking process is more of an art than science. However, the results of this process, drive modern science and are vital for the community to draw sensible conclusions on the performance of applications and systems."The post Call for Papers: International Conference on HPC & Simulation in Genoa appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2HXRV)
Yuval Degani from Mellanox presented this talk at the OpenFabrics Workshop. "In this talk, we present a Java-based, RDMA network layer for Apache Spark. The implementation optimized both the RPC and the Shuffle mechanisms for RDMA. Initial benchmarking shows up to 25% improvement for Spark Applications."The post Accelerating Apache Spark with RDMA appeared first on insideHPC.
|
 |
by staff on (#2HV2P)
Today Eurotech announced the Eurotech Aurora Tigon v4, the flagship product of the Eurotech hybrid HPC systems line that adds support for the second generation Intel Xeon Phi Processor. With up to 72 cores (288 threads) per CPU the Xeon Phi brings new levels of performance in the datacenter: the Tigon is one of the most powerful and power efficient supercomputers on the market, featuring up to 18.432 CPU cores and 256 Nvidia Kepler GPUs at less than 100KW per rack.The post Eurotech Unveils Aurora Tigon V4 System with Intel Xeon Phi appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2HV1D)
Today French Startup Calyos launched a kickstarter funding project for the NSG S0, "the World's First Fanless Chassis for High Performing PC." The secret behind the Calyos fanless gaming PC chassis is phase-change cooling through loop heat pipes. Used in Datacenter servers, they absorb the heat from the hot components and move it passively to the edges of the case, where heat can be easily removed with an air or liquid heat exchanger.The post Calyos Launches Kickstarter for Fanless Gaming PC appeared first on insideHPC.
|
 |
by staff on (#2HQN1)
"This year’s workshop continues SDSC’s strategy of bringing high-performance computing to what is known as the ‘long tail’ of science, i.e. providing resources to a larger and more diverse number of modest-sized computational research projects that represent, in aggregate, a tremendous amount of scientific research and discovery. SDSC has developed and hosted Summer Institute workshops for well over a decade."The post Register Now for the SDSC Summer Institute on HPC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2HQFZ)
In this video from the OpenFabrics Workshop, Susan Coulter from LANL presents: State of the OpenFabrics Alliance. "The OpenFabrics Alliance (OFA) is an open source-based organization that develops, tests, licenses, supports and distributes OpenFabrics Software (OFS). The Alliance’s mission is to develop and promote software that enables maximum application efficiency by delivering wire-speed messaging, ultra-low latencies and maximum bandwidth directly to applications with minimal CPU overhead."The post Video: State of the OpenFabrics Alliance appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2HQC4)
"The Cloud Lightning conference will feature academics and industry professionals from across Europe and the UK who will deliver presentations, talks, and research findings into High Performance Infrastructure for Public Sector Research, Heterogeneous Computing, HPC in the Cloud Use Cases, and Next Generation Resource Management for cloud/HPC."The post CloudLightning Conference Coming to Dublin April 11 appeared first on insideHPC.
|
 |
by staff on (#2HQ8F)
"The SHAPE Program will help European SMEs overcome barriers to using HPC, such as cost of operation, lack of knowledge and lack of resources. It will facilitate the process of defining a workable solution based on HPC and defining an appropriate business model."The post SHAPE Program offers HPC to Small Businesses in Europe appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2HQ3W)
"This talk will present RDMA-based designs using OpenFabrics Verbs and heterogeneous storage architectures to accelerate multiple components of Hadoop (HDFS, MapReduce, RPC, and HBase), Spark and Memcached. An overview of the associated RDMA-enabled software libraries (being designed and publicly distributed as a part of the HiBD project for Apache Hadoop."The post Accelerating Hadoop, Spark, and Memcached with HPC Technologies appeared first on insideHPC.
|
 |
by staff on (#2HKND)
Today the GW4 Alliance in the UK unveiled Isambard, the world’s first ARM-based production supercomputer at today’s Engineering and Physical Sciences Research Council (EPSRC) launch at the Thinktank science museum in Birmingham. "Isambard is able to provide system comparison at high speed as it includes over 10,000, high-performance 64-bit ARM cores, making it one of the largest machines of its kind anywhere in the world. Such a machine could provide the template for a new generation of ARM-based services."The post GW4 Unveils ARM-Powered Isambard Supercomputer from Cray appeared first on insideHPC.
|
 |
by staff on (#2HKHD)
Today the Gauss Centre for Supercomputing (GCS) announced that Prof. Dr. Dieter Kranzlmüller is the new Chairman of the Board of Directors at GCS member Leibniz Supercomputing Centre (LRZ).The post Prof. Dieter Kranzlmüller Named Chairman of the Board at LRZ in Germany appeared first on insideHPC.
|
 |
by staff on (#2HKG3)
"Besides trying to identify likely drug targets for new HIV treatments, EAFIT’s first supercomputer, named Apolo, is being used for everything from earthquake science in a country regularly shaken by tremors, to a groundbreaking examination of the tropical disease leishmaniasis, to the most “green†way of processing cement. The machine speeds the time to science for Colombian researchers and lets them tackle bigger problems."The post Purdue Supercomputer Gets Second Life in Colombia appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2HK9A)
Today the Ohio Supercomputer Center dedicated its newest, most powerful supercomputer: the Owens Cluster. The Dell cluster, named for the iconic Olympic champion Jesse Owens, delivers 1.5 petaflops of total peak performance. "OSC’s Owens Cluster represents one of the most significant HPC systems Dell has built,†said Tony Parkinson, Vice President for NA Enterprise Solutions and Alliances at Dell.The post Dell Powers New Owens Cluster at Ohio State appeared first on insideHPC.
|
 |
by staff on (#2HK7A)
Registration is now open for PRACEdays17. The event May 16-18 in Barcelona, Spain. "The PRACEdays17 program will follow the tradition set by the first three editions and will include international keynote presentations from high-level scientists and researchers from academia and industry, including among others Telli van der Lei, Senior Scientist Supply Chain and Process Modeling at DSM; Nuria Lopez, Professor at the Institute of Chemical Research of Catalonia; and Xue-Feng Yuan, Director of the Institute for Systems Rheology (ISR), P. R. China."The post Register Now for PRACEdays17 in Barcelona appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2HK5N)
Bill Magro from IBTA gave this talk at the OpenFabrics Workshop. "This talk discusses some recent activities in the InfiniBand Trade Association including recent specification updates. It also provides a glimpse into the future for the IBTA." Bill Magro is an Intel Fellow and Intel’s Chief Technologist for HPC software. In this role, he serves as the technical lead and strategist for Intel's high-performance computing software and provides HPC software requirements for Intel product roadmaps."The post Recent Topics in the IBTA… and a Look Ahead appeared first on insideHPC.
|
 |
by staff on (#2HG05)
"Since the NICE acquisition by Amazon Web Services (AWS), many customers asked us how to make the HPC experience in the Cloud as simple as the one they have on premises, while still leveraging the elasticity and flexibility that it provides. While we stay committed to delivering new and improved capabilities for on-premises deployments, like the new support for Citrix XenDesktop and the new HTML5 file transfer widgets, EnginFrame 2017 is our first step into making HPC easier to deploy and use in AWS, even without an in-depth knowledge of its APIs and rich service offering."The post NICE Software Releases EnginFrame 2017 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2HFRV)
Pavel Shamis from ARM Research presented this talk at the OpenFabrics Workshop. "With the emerging availability server platforms based on ARM CPU architecture, it is important to understand ARM integrates with RDMA hardware and software eco-system. In this talk, we will overview ARM architecture and system software stack. We will discuss how ARM CPU interacts with network devices and accelerators. In addition, we will share our experience in enabling RDMA software stack (OFED/MOFED Verbs) and one-sided communication libraries (Open UCX, OpenSHMEM/SHMEM) on ARM and share preliminary evaluation results."The post Video: RDMA on ARM appeared first on insideHPC.
|
 |
by staff on (#2HFK7)
Today Rigetti Computing, a leading quantum computing start-up, announced it has raised $64 million in Series A and B funding. "Quantum computing will enable people to tackle a whole new set of problems that were previously unsolvable," said Chad Rigetti, founder and chief executive officer of Rigetti Computing. "This is the next generation of advanced computing technology. The potential to make a positive impact on humanity is enormous."The post Quantum Startup Rigetti Computing Raises $64 Million in Funding appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2HFAV)
In previous articles (1 and 2) here on insideHPC, James Reinders described “Intel Xeon Phi processor Programming in a Nutshell†for Intel’s 72-core processor. In this special guest feature, he discusses cluster modes and the interaction of the memory modes with these cluster modes.The post Intel Xeon Phi Cluster Mode Programming (and interactions with memory modes) in a Nutshell appeared first on insideHPC.
|
 |
by staff on (#2HFAW)
"Grid Engine 8.5’s significant performance improvement for submitting jobs and reduced scheduling times will have a profound impact to our customers’ bottom line as they can now get more work done in the same amount of time. By reducing the wait time for end-users, our customers can save significant costs. Managing the purchase of more servers and getting higher throughput means deadlines can be met with confidence and on budget. Our goal was to increase the value Univa provides over previous versions of Grid Engine, including the popular open source version 6.2U5,†said Bill Bryce, Vice President of Products at Univa.The post New Univa Grid Engine Release Doubles Performance over Previous Versions appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2HBGD)
Users of the integrated iRODS Rule Oriented Data System from around the globe will gather at the iRODS User Group meeting to discuss iRODS-enabled applications, discoveries, and technologies. The event takes place June 13-15 in Utrecht, The Netherlands. "Thousands of businesses, research centers, and government agencies located in the U.S., Europe, Asia, Australia, South America, and Africa use iRODS for flexible, policy-based data management that provides long-term preservation and federation."The post Call for Papers: iRODS User Group in The Netherlands appeared first on insideHPC.
|
 |
by staff on (#2HBC6)
Today Argonne announced that computer scientist Valerie Taylor has been appointed as the next director of the Mathematics and Computer Science (MCS) division at Argonne National Laboratory, effective July 3, 2017. “Valerie brings with her a wealth of leadership experience, computer science knowledge and future vision,†said Rick Stevens, Argonne Associate Laboratory Director for Computing, Environment and Life Sciences. “We feel strongly that her enthusiasm and drive will serve her well in her new role, and are pleased to have her joining our staff.â€The post Valerie Taylor Named Director of Mathematics and Computer Science at Argonne appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2HBAA)
“Supermicro RSD makes it easy for companies of any size to build cloud infrastructure that until now are limited to leading large public and private cloud providers,†said Charles Liang, President and CEO of Supermicro. “The Supermicro RSD solution enables more customers to build large scale modern data centers leveraging Supermicro’s best-of-breed server, storage and networking product portfolio.â€The post Supermicro Unveils RSD Rack Scale Design appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2HB0R)
"In this keynote, Al Geist will discuss the need for future Department of Energy supercomputers to solve emerging data science and machine learning problems in addition to running traditional modeling and simulation applications. The ECP goals are intended to enable the delivery of capable exascale computers in 2022 and one early exascale system in 2021, which will foster a rich exascale ecosystem and work toward ensuring continued U.S. leadership in HPC. He will also share how the ECP plans to achieve these goals and the potential positive impacts for OFA."The post Exascale Computing Project – Driving a HUGE Change in a Changing World appeared first on insideHPC.
|
 |
by staff on (#2H8KA)
Today Asetek announced a new order from one of its existing OEM partners for its RackCDU D2C (Direct-to-Chip) liquid cooling solution. The order is part of a new installation for an undisclosed HPC customer. "I am very pleased with the progress we are making in our emerging data center business segment," said André Sloth Eriksen, CEO and founder of Asetek. "This repeat order, from one of our OEM partners, to a new end customer confirms the trust in our unique liquid cooling solutions and that adoption is growing.â€The post Asetek Liquid Cooling Solution Coming to HPC Center appeared first on insideHPC.
|
 |
by staff on (#2H8CF)
The UK is launching six HPC centers this month. Funded by £20 million from the Engineering and Physical Sciences Research Council (EPSRC) the centres are located around the UK, at the universities of Cambridge, Edinburgh, Exeter, and Oxford, Loughborough University, and UCL. "These centres will enable new discoveries, drive innovation and allow new insights into today's scientific challenges. They are important because they address an existing gulf in capability between local university systems and the UK National Supercomputing Service ARCHER," said Professor Philip Nelson, EPSRC's Chief Executive.The post UK to Launch Six HPC Centers appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2H7NG)
In this video, Ruben Cruz Garcia from the Earth Sciences department at BSC, describes how supercomputing is key to his research. He also explains what he would do if he had unlimited access to a fully operational exascale computer.The post Video: Why Supercomputing is Important for Science appeared first on insideHPC.
|
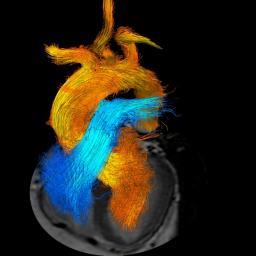 |
by Rich Brueckner on (#2H7HV)
"The current versions of the codes use MPI and depend on finer and finer meshes for higher accuracy which are computationally demanding. To overcome the demands, the team has gained access to their state-of-the-art cluster equipped with POWER CPUs and Tesla P100 GPUs — and turning to OpenACC and machine learning to accelerate their science. This has allowed them to spend the least resources on programming, and effectively utilize available compute resources."The post Video: Computational Fluid Dynamics for Surgical Planning appeared first on insideHPC.
|
 |
by staff on (#2H7EH)
A team of researchers at Berkeley Lab, PNNL, and Intel are working hard to make sure that computational chemists are prepared to compute efficiently on next-generation exascale machines. Recently, they achieved a milestone, successfully adding thread-level parallelism on top of MPI-level parallelism in the planewave density functional theory method within the popular software suite NWChem. "Planewave codes are useful for solution chemistry and materials science; they allow us to look at the structure, coordination, reactions and thermodynamics of complex dynamical chemical processes in solutions and on surfaces."The post Berkeley Lab Tunes NWChem for Intel Xeon Phi Processor appeared first on insideHPC.
|
|
by Rich Brueckner on (#2H701)
In this podcast, the Radio Free HPC team looks at some the top High Performance Computing stories from this week. First up, we look at Europe's effort to lead HPC in the next decade. After that, we look at why small companies like Scalable Informatics have such a hard time surviving in the HPC marketplace.The post Radio Free HPC Looks at Europe’s Push for Leadership in Global HPC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2H4Q8)
Registration is open for the 33rd International Conference on Massive Storage Systems and Technology (MSST 2017.) The event takes place May 15-19 in Santa Clara, California. "Since the conference was founded by the leading national laboratories, MSST has been a venue for massive-scale storage system designers and implementers, storage architects, researchers, and vendors to share best practices and discuss building and securing the world's largest storage systems for high-performance computing, web-scale systems, and enterprises."The post Register now for the International Conference on Massive Storage Systems and Technology (MSST 2017) appeared first on insideHPC.
|
 |
by staff on (#2H4N0)
"deal.II — a name that originally meant to indicate that it is the successor to the Differential Equations Analysis Library — is a C++ program library targeted at the computational solution of partial differential equations using adaptive finite elements. It uses state-of-the-art programming techniques to offer you a modern interface to the complex data structures and algorithms required."The post RCE Podcast Looks at Deal.II Finite Element Library appeared first on insideHPC.
|
 |
by staff on (#2H21A)
ARM has taken a step into the artificial intelligence market with the announcement of a new micro-architecture - DynamIQ - specifically designed for artificial intelligence (AI). "DynamIQ technology is a monumental shift in multi-core microarchitecture for the industry and the foundation for future ARM Cortex-A processors. The flexibility and versatility of DynamIQ will redefine the multi-core experience across a greater range of devices from edge to cloud across a secure, common platform."The post New ARM Architecture Targets AI appeared first on insideHPC.
|
 |
by staff on (#2H209)
Today Huawei an agreement with the Institute of Technology and Renewable Energy (ITER) to provide HPC services on Tenerife, one of the Spanish-controlled Canary Islands off the west coast of Africa. "The agreement established the collaboration between ITER and Huawei to jointly develop the capacity in super-computation, smart technology, big data applications and analysis applications, in which we have made important progress," said Carlos Antonio Rodriguez, president of the local Administrative Council that runs ITER.The post Huawei to Provide HPC Services to Tenerife in Canary Islands appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2GYX5)
"The SCC reproducibility program is part of a wider effort to encourage authors submitting papers to the conference to voluntarily complete an appendix to their paper that described the details of their software environment and computational experiments to the extent that an independent person could replicate their results."The post SC17 Student Cluster Competition Continues Push for Reproducibility appeared first on insideHPC.
|
 |
by staff on (#2GYVQ)
"The Huawei-Altair cooperation will be dedicated to building highly efficient, high-performance industrial simulation cloud solutions leveraging Altair’s PBS Works software suite," said Yu Dong, President of Industry Marketing & Solution Dept of Enterprise BG, Huawei, "Committed to a vision of openness, cooperation, and win-win, Huawei cooperates with global partners to provide customers with innovative solutions for industrial manufacturing and help them achieve business success."The post Huawei and Altair to Build Industrial Simulation Cloud Solutions appeared first on insideHPC.
|
 |
by staff on (#2GYFH)
“As a team, we are laying the foundation to identify challenges and recommendations on possible solutions to the industry’s current limitations defined by Moore’s Law. With the launch of the nine white papers on our new website, the IRDS roadmap sets the path for the industry benefiting from all fresh levels of processing power, energy efficiency, and technologies yet to be discovered.â€The post IEEE Looks Beyond Moore’s Law with IRDS Technology Roadmap appeared first on insideHPC.
|
 |
by staff on (#2GYDV)
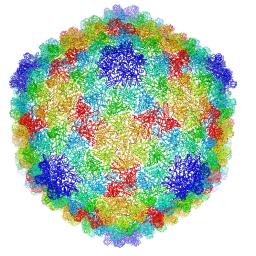
Berkeley Lab researchers have developed the first 3-D atomic-scale model of P22 virus that identifies the protein interactions crucial for its stability. "This is a great example of how to exploit electron microscopy technology and combine it with new computational methods to determine a bacteriophage’s structure,†said Paul Adams, Berkeley Lab’s Molecular Biophysics & Integrated Bioimaging division director and a co-author of the paper. “We developed the algorithms—the computational code—to optimize the atomic model so that it best fit the experimental data.â€The post Berkeley Lab Algorithm Boosts Resolution on Cryo–EM appeared first on insideHPC.
|
 |
by staff on (#2GY8Q)
According to Asperitas, Immersed Computing is a concept driven by sustainability, efficiency and flexibility and goes far beyond just technology. In many situations, Immersed Computing can save more than 50% of the total energy footprint. By using immersion, 10-45% of IT energy is reduced due to the lack of fans, while other energy consumers like cooling installations can achieve up to 95% energy reduction. It allows for warm water cooling which provides even more energy savings on cooling installations. One more benefit, Immersed Computing enables high temperature heat reuse.The post Asperitas Unveils Liquid-cooled Modular Datacenter Solution appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2GV5R)
Embry-Riddle Aeronautical University in Daytona Beach is seeking a High Performance Computing System Administrator in our Job of the Week. "The HPC Specialist is responsible for technical systems management, administration, and support for the high-performance computing (HPC) cluster environments. This includes all configuration, authentication, networking, storage, interconnect, and software usage & installation of HPC Clusters. The position is highly technical and directly impacts the daily operational functions of the above environments."The post Job of the Week: HPC System Administrator at Embry-Riddle Aeronautical University appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2GTZW)
"Intel sees the huge potential in AI and are moving mountains to take full advantage of it," said Patrick Moorhead from Moor Insights & Strategy. "They have acquired Altera, Nervana Systems and other IP, need to connect to their home-grown IP and now it's time to accelerate the delivery of it. That's where today's organization comes in play, a centralized organization, reporting directly to CEO Brian Krzanich, to make that happen. This is classic organizational strategy, accelerating delivery by organizing a cross-product group directly reporting to the CEO.â€The post Intel Aligns its AI Efforts into a Single Organization appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2GTWJ)
"HPC is moving towards its next frontier - more than 100 times faster than the fastest machines currently available in Europe," said Andrus Ansip, European Commission Vice-President for the Digital Single Market. "But not all EU countries have the capacity to build and maintain such infrastructure, or to develop such technologies on their own. If we stay dependent on others for this critical resource, then we risk getting technologically 'locked', delayed or deprived of strategic know-how. Europe needs integrated world-class capability in supercomputing to be ahead in the global race."The post Panel Discussion on How Europe Can Attain World Leadership in HPC appeared first on insideHPC.
|
 |
by staff on (#2GTNR)
"The new CooLMUC 3 system outperforms its predecessors in a number of respects, including its key feature of cooling in thermally insulated racks all compute and login nodes, power supply units, and Omni-Path switches directly with hot water, a combination the likes of which has never been seen before," said Axel Auweter, Head of HPC Development at MEGWARE. "Even at a cooling water temperature of 40 degrees Celsius and a room temperature of 25 degrees Celsius, a maximum of just 3% waste heat is produced in the ambient air."The post Megware to Install CooLMUC 3 Supercomputer at LRZ in Germany appeared first on insideHPC.
|
 |
by Richard Friedman on (#2GTFP)
When used in a TBB environment, Intel has demonstrated a many-fold performance improvement over the same parallelized code using Intel MKL in an OpenMP environment. Intel TBB-enabled Intel MKL is ideal when there is heavy threading in the Intel TBB application. Intel TBB-enabled Intel MKL shows solid performance improvements through better interoperability with other parts of the workload.The post Intel MKL and Intel TBB Working Together for Performance appeared first on insideHPC.
|
 |
by staff on (#2GSJD)
Today ISC 2017 announced the inclusion of the STEM Student Day & Gala at this year’s conference. Taking place June 21 in Frankfurt, the new program aims to connect the next generation of regional and international STEM practitioners with the high performance computing industry and its key players. "There is currently a shortage of a skilled STEM workforce in Europe and it is projected that the gap between available jobs and suitable candidates will grow very wide beyond 2020 if nothing is done about it,†said Martin Meuer, the general co-chair of ISC High Performance. “This gave us the idea to organize the STEM Day, as many organizations that exhibit at ISC could profit from meeting the future workforce directly.â€The post ISC 2017 Adds STEM Student Day appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2GQ24)
"As the founding lead of the Google Brain project, and more recently through my role at Baidu, I have played a role in the transformation of two leading technology companies into “AI companies.†But AI’s potential is far bigger than its impact on technology companies. I will continue my work to shepherd in this important societal change. In addition to transforming large companies to use AI, there are also rich opportunities for entrepreneurship as well as further AI research."The post Andrew Ng Leaving Baidu for Next Chapter in AI appeared first on insideHPC.
|
 |
by staff on (#2GQ0J)
Today the Indian Institute of Technology Kharagpur announced that it will be the first academic institution to open a supercomputing facility under India's National Supercomputing Mission (NSM). This will provide large computational support to users to carry out both research and teaching activities that involve state-of-the-art HPC and usher in a new age in research and innovation in the country, an IIT-Kharagpur spokesperson said. "The Petaflop new system with both CPU and CPU-GPU based servers along with the already existing HPC equipment will provide about 1.5 Peta-Flop capacity support to several areas where the researchers of IIT-KGP are actively involved," said IIT-KGP Director Prof P P Chakrabarti.The post 1.5 Petaflop Supercomputer coming to IIT-Kharagpur in India appeared first on insideHPC.
|