
 |
by Rich Brueckner on (#2K6TY)
"The basic idea of deep learning is to automatically learn to represent data in multiple layers of increasing abstraction, thus helping to discover intricate structure in large datasets. NVIDIA has invested in SaturnV, a large GPU-accelerated cluster, (#28 on the November 2016 Top500 list) to support internal machine learning projects. After an introduction to deep learning on GPUs, we will address a selection of open questions programmers and users may face when using deep learning for their work on these clusters."The post Deep Learning on the SaturnV Cluster appeared first on insideHPC.
|
| Link | http://insidehpc.com/ |
| Feed | http://insidehpc.com/feed/ |
| Updated | 2026-06-20 01:45 |
 |
by Rich Brueckner on (#2K6RW)
The TERATEC Forum has posted their Agenda for their upcoming June meeting. With technical workshops, plenary sessions and a vendor exhibit, the event takes place June 27-28 at the Ecole Polytechnique campus in Palaiseau, France. "Our objective is to bring together all decision makers and experts in the field of digital simulation and Big Data, from the industrial and technological world and the world of research."The post Agenda Posted for June Teratec Forum in France appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2K3K9)
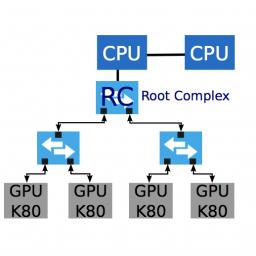
"MeteoSwiss, the Swiss national weather forecast institute, has selected densely populated accelerator servers as their primary system to compute weather forecast simulation. Servers with multiple accelerator devices that are primarily connected by a PCI-Express (PCIe) network achieve a significantly higher energy efficiency. Memory transfers between accelerators in such a system are subjected to PCIe arbitration policies. In this paper, we study the impact of PCIe topology and develop a congestion-aware performance model for PCIe communication. We present an algorithm for computing congestion factors of every communication in a congestion graph that characterizes the dynamic usage of network resources by an application."The post A PCIe Congestion-Aware Performance Model for Densely Populated Accelerator Servers appeared first on insideHPC.
|
 |
by staff on (#2K3EQ)
Today Engility that the company will bring its world-class high performance computing capabilities to bear as it competes to win NASA’s Advanced Computing Services contract. "HPC is a strategic, enabling capability for NASA,†said Lynn Dugle, CEO of Engility. “Engility’s cadre of renowned computational scientists and HPC experts, coupled with our proven high performance data analytics solutions, will help increase NASA’s science and engineering capabilities.â€The post Engility Pursues NASA Advanced Computing Services Contract appeared first on insideHPC.
|
 |
by staff on (#2K3BS)
In this special guest feature, James Reinders discusses the use of the Intel® Advanced Vector Instructions (Intel® AVX-512), covering a variety of vectorization techniques available for accessing the performance of Intel AVX-512.The post Intel Xeon Phi Processor Intel AVX-512 Programming in a Nutshell appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2K36C)
Registration is now open for the PASC17 conference, which takes place the week after ISC in Lugano, Switzerland. "The PASC17 Conference is pleased to announce that a preliminary program is available online and that registration is now open. The PASC Conference is an interdisciplinary ev"ent in high performance computing that brings together domain science, applied mathematics and computer science – where computer science is focused on enabling the realization of scientific computation.The post Registration Opens for PASC17 Conference in Lugano appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JZXK)
The OpenSFS Lustre community has posted the Agenda for their upcoming LUG 2017 conference. The event takes place May 30 – June 2 in Bloomington, Indiana. The Lustre User Group (LUG) conference is the industry’s primary venue for discussion and seminars on the Lustre parallel file system and other open source file system technologies.†LUG provides […]The post Agenda Posted for LUG 2017 in Bloomington appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JZT7)
In this video from Switzerland HPC Conference, Rich Brueckner from insideHPC moderates a panel discussion on Exascale Computing. "The Exascale Computing Project in the USA is tasked with developing a set of advanced supercomputers with 50x better performance than today's fastest machines on real applications. This panel discussion will look at the challenges, gaps, and probable pathways forward in this monumental endeavor."Panelists:Gilad Shainer, HPC Advisory Council
|
by Rich Brueckner on (#2JZ8S)
"High performance computing is rapidly finding new uses in many applications and businesses, enabling the creation of disruptive products and services. Huawei, a global leader in information and communication technologies, brings a broad spectrum of innovative solutions to HPC. This talk examines Huawei's world class HPC solutions and explores creative new ways to solve HPC problems."The post A Fresh Look at HPC from Huawei Enterprise appeared first on insideHPC.
 |
by Richard Friedman on (#2JYVC)
Discovering where the performance bottlenecks are and knowing what to do about it can be a mysterious and complex art, needing some very sophisticated performance analysis tools for success. That’s where Intel® VTune™ Amplifier XE 2017, part of Intel Parallel Studio XE, comes in.The post Intel® VTune™ Amplifier Turns Raw Profiling Data Into Performance Insights appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JW0F)
"Over the last decade, CUDA and the underlying GPU hardware architecture have continuously gained popularity in various high-performance computing application domains such as climate modeling, computational chemistry, or machine learning. Despite this popularity, we lack a single coherent programming model for GPU clusters. We therefore introduce the dCUDA programming model, which implements device-side remote memory access."The post dCUDA: Distributed GPU Computing with Hardware Overlap appeared first on insideHPC.
|
 |
by staff on (#2JVQ1)
Today Spectra Logic announced that Globus has completed client certification for its Spectra BlackPearl Converged Storage System. BlackPearl allows customers in university, high performance computing (HPC) and research organizations to seamlessly store data to disk, tape and cloud storage using a unified interface provided by Globus. Globus software-as-a-service (SaaS) simplifies file transfer, sharing and data publication for geographically diverse research communities worldwide. Spectra’s BlackPearl Converged Storage System integrates efficiently with the Globus service and delivers a fully integrated storage solution built to transfer data between Globus users, reducing overall data management time, cost and complexities.The post Spectra BlackPearl Gets Globus Client Certification appeared first on insideHPC.
|
 |
by staff on (#2JVFG)
"One of the challenges we face in enabling big data science is providing safe and affordable storage at petabyte scale,†said Dr. Marek Michalewicz, deputy director of ICM. “When the Avere and Western Digital team arrived, we were able to count time-to-completion in hours. Together, Avere and Western Digital let us take advantage of object storage efficiencies to support demand, delivering the capacity, performance and manageability that the OCEAN data center environment requires.â€The post Avere Powers Active Archive Object Storage at University of Warsaw appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JVE3)
General Atomics in San Diego is seeking a Software Developer for Exascale Computing at General Atomics in our Job of the Week. "This position independently leads the design, development and verification of novel scientific software for high-fidelity physics simulations on unique high performance computational hardware including Exascale-class systems."The post Job of the Week: Software Developer for Exascale at General Atomics appeared first on insideHPC.
|
 |
by staff on (#2JV6S)
The LAD'17 Lustre Administrators and Developers Conference has issued their Call for Proposals. The event takes place Oct. 3-4 in Paris. "We are inviting community members to send proposals for presentations at this event. No proceeding is required, just an abstract of a 30-min (technical) presentation. Topics may include (but are not limited to): site updates or future projects, Lustre administration, monitoring and tools, Lustre feature overview, Lustre client performance, benefits of hardware evolution to Lustre, comparison between Lustre and other parallel file system, Lustre and Exascale I/O, etc."The post Call for Proposals: LAD’17 in Paris appeared first on insideHPC.
|
 |
by staff on (#2JRK3)
During the first week of April, Eni fired up its new HPC cluster in the Green Data Center in Ferrera Erbognone, Italy. Known as HPC3, the new 5.8 Petaflop cluster will allow Eni to fully support all the activities in the Energy Exploration and Production sector. "The start-up of the new HPC3 supercomputer and its follow-on HPC4 will enable Eni to deploy the most advanced and sophisticated proprietary codes developed by our research for the E&P activities," said Eni CEO Claudio Descalzi. "These technologies will provide Eni with unprecedented accuracy and resolution in seismic imaging, geological modeling and reservoir dynamic simulation, allowing us to further accelerate overall cycle times in the upstream process and to sustain the E&P performances."The post Eni in Italy fires up 5.8 Petaflop HPC3 Cluster for Oil & Gas appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JRDK)
"This talk will focus on challenges in designing programming models and runtime environments for Exascale systems with millions of processors and accelerators to support various programming models. We will focus on MPI+X (PGAS - OpenSHMEM/UPC/CAF/UPC++, OpenMP, and CUDA) programming models by taking into account support for multi-core systems (KNL and OpenPower), high-performance networks, GPGPUs (including GPUDirect RDMA), and energy-awareness."The post High-Performance and Scalable Designs of Programming Models for Exascale Systems appeared first on insideHPC.
|
 |
by staff on (#2JR9M)
Today DDN announced new feature enhancements to its WOS object storage platform that include increased data protection and multi-site connectivity options. With its newest capabilities, DDN WOS provides the lowest data protection overhead available in the market. It also delivers control for local-only rebuilds for higher uptime and lower performance impact of hardware failures, along with multi-site collaboration, distribution and disaster recovery that is faster and more efficient than public cloud solutions.The post DDN Adds Cost-Effective Data Protection to WOS Object Storage appeared first on insideHPC.
|
 |
by staff on (#2JR0T)
Genomic sequencing has progressed so rapidly that researchers can now analyze the genetic profiles of healthy individuals to uncover mutations that will almost certainly lead to a genetic condition. These breakthroughs are demonstrating that the future of genomic medicine will focus not just on the ability to reactively treat diseases, but on predicting and preventing them before they occur.The post Next-Generation Sequencing Improving Precision Medicine appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JQKG)
"Nimbix has tremendous experience in GPU cloud computing, going all the way back to NVIDIA’s Fermi architecture,†said Steve Hebert, CEO of Nimbix. “We are looking forward to accelerating deep learning and analytics applications for customers seeking the latest generation GPU technology available in a public cloud.â€The post Tesla P100 GPUs Speed Cloud-Based Deep Learning on the Nimbix Cloud appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JMQV)
Sean Hefty from Intel presented this talk at the OpenFabrics Workshop. "With its initial release two years ago, libfabric advanced the state of fabric software interfaces. One of the promises of OFI was extensibility: adapting to increased demands of fabric services from applications. This session explores the first major enhancements to the libfabric API in response to user demands and learnings."The post Video: Advancing Open Fabrics Interfaces appeared first on insideHPC.
|
 |
by staff on (#2JMEG)
Today Asetek announced an order from one of its existing OEM partners for its RackCDU D2C (Direct-to-Chip) liquid cooling solution. The order is part of a new installation for an undisclosed HPC customer.The post Asetek Lands Another RackCDU D2C Order for New HPC Installation appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JMB8)
Costas Bekas from IBM Research Zurich presented this talk at the Switzerland HPC Conference. "IBM Research builds applications that enable humans to collaborate with powerful AI technologies to discover, analyze and tackle the world’s greatest challenges. Humans are on the cusp of augmenting their lives in extraordinary ways with AI. At IBM Research Labs around the globe, we envision and develop next-generation systems that work side-by side with humans, accelerating our ability to create, learn, make decisions and think."The post Visionary Perspective: Foundations of Cognitive Computing appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JKYJ)
In this podcast, the Radio Free HPC team discusses the upcoming MSST Mass Storage Conference with Program Chair Matthew O'Keefe from Oracle. "Since the conference was founded by the leading national laboratories, MSST has been a venue for massive-scale storage system designers and implementers, storage architects, researchers, and vendors to share best practices and discuss building and securing the world's largest storage systems for HPC, web-scale systems, and enterprises."The post Radio Free HPC Previews the MSST Mass Storage Conference appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JJ79)
In this video, Dana Brunson from Oklahoma State describes the mission of the Oklahoma High Performance Computing Center. Formed in 2007, the HPCC facilitates computational and data-intensive research across a wide variety of disciplines by providing students, faculty and staff with cyberinfrastructure resources, cloud services, education and training, bioinformatics assistance, proposal support and collaboration.The post Cowboy Supercomputer Powers Research at Oklahoma State appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JHYV)
Appentra and CESGA are organizing a GPU Hackathon in Spain. The event takes place May 29 - June 1 at the Galicia Supercomputing Center in Santiago de Compostela. The event is free, limited in capacity and in Spanish, with priority for national participants.The post GPU Hackathon Coming to Spain End of May appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JGDK)
Ira Weiny from Intel presented this talk at the OpenFabrics Workshop. "Individual node configuration when managing 1000s or 10s of thousands of nodes in a cluster can be a daunting challenge. Two key daemons are now part of the rdma-core package which aid the management of individual nodes in a large fabric: IBACM and rdma-ndd."The post Managing Node Configuration with 1000s of Nodes appeared first on insideHPC.
|
 |
by staff on (#2JGCV)
The latest industrial vehicles – as with other areas of automotive design – often involve high-tech components composite components to assisted driving or vehicle automation systems which require significantly more complex simulation. Automotive design tasks frequently deal with contradictory requirements of this kind: "make something stronger while making it lighter," explained Sjodin. "Simulations here can be invaluable since modern tools can be setup to sweep over a large range of cases, or to automatically optimize for a certain objective."The post Driving Change with Multiphysics appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JE4J)
In this video from KAUST Live, Dr. Robert Voigt discusses his recent keynote at the HPC Saudi Conference on the topic of Educating Computational Scientists. "This talk will provide a historical perspective on the challenges of educating computational scientists based on my personal involvement over a number of years. Three decidedly different activities will be drawn on to indicate how one can successfully approach the challenge."The post Dr. Robert Voigt on Educating Computational Scientists appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JE1Q)
Hyperion Research has posted the final agenda for the HPC User Forum April 17-19 in Santa Fe. Note that Hyperion Research is the new name for the former IDC HPC group.The post Agenda Posted for HPC User Forum in Santa Fe appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JDZ1)
"Infiniband Virtualization allows a single Channel Adapter to present multiple transport endpoints that share the same physical port. To software, these endpoints are exposed as independent Virtual HCAs (VHCAs), and thus may be assigned to different software entities, such as VMs. VHCAs are visible to Subnet Management, and are managed just like physical HCAs. We will cover the Virtualization model, management, addressing modes, and discuss deployment considerations."The post Video: InfiniBand Virtualization appeared first on insideHPC.
|
 |
by staff on (#2JDW1)
"Iceotope's novel approach to liquid cooling allows us to deliver compute capability for customers with environments outside the traditional air cooled datacentre – for example a factory shop floor or an office environment where standard servers are too noisy," said Steve Reynolds, sales director at OCF. "Our partnership with Iceotope enables us to provide an alternative and innovative solution for our customers.â€The post OCF in the UK Adopts Iceotope Liquid Cooling Technology appeared first on insideHPC.
|
 |
by staff on (#2JBD2)
E8 Storage has selected NVMe solid-state drives from HGST as the next-generation storage vendor pushes the boundaries of performance for the enterprise and software-defined cloud. According to Western Digital, Embedding HGST Ultrastar SN200 family PCIe SSDs into E8 Storage’s NVMe enclosure can deliver a 10x increase in performance, 50% lower total cost of ownership, and up to 153 terabytes in 2U.The post E8 Storage Integrates HGST Ultrastar NVMe SSDs appeared first on insideHPC.
|
 |
by staff on (#2JB94)
The European PRACE initiative has issued its 15th Call for Proposals for Project Access, the second Call under the PRACE 2 program. "Applications for Project Access must use codes that have been previously tested and that demonstrate high scalability and optimization to multi-core architectures or that demonstrate a requirement for ensemble simulations that need a very large amount of CPU/GPU overall."The post Call for Proposals: PRACE 2 Project Access appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JAZJ)
Xiaoyi Lu from Ohio State University presented this talk at the Open Fabrics Workshop. "Single Root I/O Virtualization (SR-IOV) technology has been steadily gaining momentum for high performance interconnects such as InfiniBand. SR-IOV can deliver near native performance but lacks locality-aware communication support. This talk presents an efficient approach to building HPC clouds based on MVAPICH2 and RDMA-Hadoop with SR-IOV."The post Building Efficient HPC Clouds with MCAPICH2 and RDMA-Hadoop over SR-IOV IB Clusters appeared first on insideHPC.
|
 |
by staff on (#2JAV8)
DDN is helping the University of Edinburgh accelerate its genomics and other industry research. According to professor Mark Parsons, director of the Edinburgh Parallel Computing Center, DDN’s high-performance storage supports fast-growing genomics research while enabling multinational companies and smaller businesses to benefit from access to advanced technologies. “We’re entering a period of huge innovation both in HPC and storage,†he said.The post DDN Lustre Powers Genomics Research at University of Edinburgh appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2JAFP)
Today ISC 2017 announced the finalists for the Hans Meuer Award. Introduced in memory of the late Dr. Hans Meuer of TOP500 fame, the award recognizes the most outstanding research paper submitted to the conference’s Research Papers Committee.The post ISC 2017 Announces Finalists for Hans Meuer Award appeared first on insideHPC.
|
 |
by staff on (#2J8RV)
Today Hyperion Research reports that Worldwide factory revenue for the high-performance computing technical server market grew 4.4% in full-year 2016 to a record $11.2 billion, up from $10.7 billion in 2015 and from the previous record of $11.1 billion in exceptionally strong 2012. Hyperion Research is the new name for the former IDC HPC group.The post Report: Supercomputer Growth Drives Record HPC Revenue in 2016 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2J89X)
Los Alamos National Lab is seeking a Research Technologist in our Job of the Week. "This position will focus on research and development of novel DNA and RNA isolation and library preparation methods to accommodate library preparation requirements for a variety of NGS platforms. This includes shotgun, amplicon or other enrichment methods targeting single cell, small volume or small nucleic acid concentration samples as well as traditional samples for sequencing on Illumina, Pacbio, and MinION."The post Job of the Week: Research Technologist at LANL appeared first on insideHPC.
|
 |
by staff on (#2J84Y)
"The rapid growth of these systems has been driven by the value that they deliver, but the market for all-flash systems under the $100,000 price point has been slow to take off. Systems like the Seagate RealStor 5005 array, however, set a new bar for value in these price ranges by delivering up to 300,000 IOPS at sub 300 microsecond latencies and 20 terabytes of raw flash capacity in just 2U of rack space, all starting at under $50,000."The post Seagate Unveils All-Flash and Hybrid Storage Arrays appeared first on insideHPC.
|
 |
by staff on (#2J835)
The Michigan Institute for Computational Discovery and Engineering has awarded its first round of Catalyst Grants, providing $75,000 each to four innovative projects in computational science. The proposals were judged on novelty, likelihood of success, potential for external funding, and potential to leverage U-M’s existing computing resources.The post Catalyst Grants Foster Innovative Projects in Computational Science appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2J80H)
Greg Casey from Dell EMC presented this talk at the OpenFabrics Workshop. "This session will focus on the new Gen-Z memory-semantic fabric. The speaker will show the audience why Gen-Z is needed, how Gen-Z operates, what is expected in first products that employ Gen-Z, and encourage participation in finalizing the Gen-Z specifications. Gen-Z will be connecting components inside of servers as well as connecting servers with pools of memory, storage, and acceleration devices through a switch environment."The post GEN-Z: An Overview and Use Cases appeared first on insideHPC.
|
 |
by staff on (#2J7ZB)
Today IBM announced that it is the first major cloud provider to make the Nvidia Tesla P100 GPU accelerator available globally on the cloud. "As the AI era takes hold, demand continues to surge for our GPU-accelerated computing platform in the cloud,†said Ian Buck, general manager, Accelerated Computing, NVIDIA. "These new IBM Cloud offerings will provide users with near-instant access to the most powerful GPU technologies to date – enabling them to create applications to address complex problems that were once unsolvable."The post NVIDIA Tesla P100 GPU Speed AI Workloads in the IBM Cloud appeared first on insideHPC.
|
 |
by staff on (#2J5C0)
Today Raid Inc. announced the ARI-500 High Performance Low Cost All Flash Array. "The ASIC-based architecture of the ARI-500 Series has an enormous cost advantage over other all flash array solutions, that's a differentiator in a competitive market place," said Robert Picardi, CEO of RAID Inc. "Users are able to benefit from ultra-high performance at a uniquely low cost point."The post Raid Inc. Launches ARI-500 Flash Array appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2J4YB)
"Using RDMA, NVMe over Fabrics (NVMe-oF) provides the high BW and low-latency characteristics of NVMe to remote devices. Moreover, these performance traits are delivered with negligible CPU overhead as the bulk of the data transfer is conducted by RDMA. In this session, we present an overview of NVMe-oF and its implementation in Linux. We point out the main design choices and evaluate NVMe-oF performance for both Infiniband and RoCE fabrics."The post Experiences with NVMe over Fabrics appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2J4QA)
The New York University Center for Urban Science and Progress will host the Advanced Computing for Competitiveness Forum on April 13. Sponsored by the U.S. Council on Competitiveness, the day-long event will look at why "To out-compete is to out-compute." The Council's landmark Advanced Computing Roundtable (ACR) - formerly the High Performance Computing (HPC) Initiative - is the preeminent forum for experts in advanced computing to set a national agenda on how such technologies should be leveraged for U.S. comptitiveness. Advanced computing includes technologies such as high performance computing, artificial intelligence (AI), and the Internet of Things (IoT). ACR members represent industrial and commercial advanced computing users, hardware and software vendors and directors of academic and national laboratory advanced computing centers."The post NYU Hosts Advanced Computing for Competitiveness Forum on April 13 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2J4GH)
In this video from the HPC Saudi Conference, Dr. Thomas Schulthess from the Swiss National Supercomputing Center discusses how CSCS approaches High Performance Computing. According to Schulthess, supporting legacy software is the biggest challenge for moving HPC forward. "Earlier this month, the European PRACE initiative went into Phase 2, with Switzerland becoming a new Hosting Member. As a Hosting Member, Switzerland is now making its Piz Daint supercomputer at CSCS available for cutting-edge PRACE research. The other Hosting Members are Spain, Italy, Germany and France."The post Video: Thomas Schulthess on how HPC Propels the Global Enterprise of Science appeared first on insideHPC.
|
 |
by staff on (#2J4F0)
Today STEM-Trek announced that Google, Inc. is a STEM-Trek Platinum supporter of the PEARC17 Student Program. The donation will increase the number of students who can participate in the Practice & Experience in Advanced Research Computing conference which will be held July 9-13 in New Orleans.The post Google becomes STEM-Trek Supporter for PEARC17 Student Program appeared first on insideHPC.
|
 |
by staff on (#2J1QM)
Today Silicon Mechanics announced that California Polytechnic State University is the recipient of its sixth annual Research Cluster Grant. As a result of its successful application, Cal Poly will receive a High-Performance Computing cluster with the latest high-performance processing, networking, storage and GPU technologies, valued at over $130,000 for use in demonstrated research and educational purposes going forward.The post Cal Poly Wins Silicon Mechanics Research Cluster Grant appeared first on insideHPC.
|
 |
by staff on (#2J10A)
"We selected vSMP Foundation from ScaleMP as the sole available solution turning cluster hardware into an SMP; as a single machine, it allows us to distribute the jobs without using any batch/queuing system, and we only need to manage one logical entity rather than a collection of nodes," said Dr. Dirk Bockelmann of the department NMR-based Structural Biology at the Max Planck Institute for Biophysical Chemistry. "We are looking forward to putting vSMP Foundation to work for our Scientists.â€The post Max Planck Institute Adopts ScaleMP Cluster Virtualization Software appeared first on insideHPC.
|