
 |
by staff on (#213YM)
Researchers and staff from the U.S. Department of Energy’s national laboratories will showcase some of DOE’s best computing and networking innovations and techniques at SC16 in Salt Lake City. "Computational scientists working for various DOE laboratories have been in involved in the conference since its 1988 beginnings, and this year’s event is no different. Experts from 14 national laboratories will be sharing a booth featuring speakers, presentations, demonstrations, discussions and simulations."The post DOE to Showcase Leadership in HPC at SC16 appeared first on insideHPC.
|
| Link | http://insidehpc.com/ |
| Feed | http://insidehpc.com/feed/ |
| Updated | 2026-06-20 07:00 |
 |
by staff on (#213WJ)
Intel Omni-Path Architecture (Intel OPA) volume shipments started a mere nine months ago in February of this year, but Intel’s high-speed, low-latency fabric for HPC has covered significant ground around the globe, including integration in HPC deployments making the Top500 list for June 2016. Intel’s fabric makes up 48 percent of installations running 100 Gbps fabrics on the Top500 June list, and they expect a significant increase in Top500 deployments, including one that could end up in the stratosphere among the top ten machines on the list.The post Intel Omni-Path Architecture Fabric, the Choice of Leading HPC Institutions appeared first on insideHPC.
|
 |
by Rich Brueckner on (#213TH)
Over at the ARM Connected Community, Darren Cepulis, writes that the popular chip platform is now part of the OpenHPC community. As one of a series of strategic moves, the effort should help bolster ARM as a platform for high performance computing.The post OpenHPC now available on ARM at SC16 appeared first on insideHPC.
|
 |
by MichaelS on (#213PF)
To get maximum parallelization for an application, not only must the application be developed to take advantage of multiple cores, but should also have the code in place to keep a number of threads working on each core. A modern processor architecture, such as the Intel Xeon Phi processor, can accommodate at least 4 threads for each core. "On the Intel Xeon Phi processor, each of the threads per core is known as a hyper-thread. In this architecture, all of the threads on a core progress through the pipeline simultaneously, producing results much more quickly than if just one thread was used. The processor decides which thread should progress, based on a number of factors, such as waiting for data from memory, instruction availability, and stalls."The post Maximize Parallelization with Threading On A Core appeared first on insideHPC.
|
 |
by staff on (#213N7)
Today the Department of Energy’s Exascale Computing Project (ECP) today announced the selection of 35 software development proposals representing 25 research and academic organizations. “After a lengthy review, we are pleased to announce that we have selected 35 proposals for funding. The funding of these software development projects, following our recent announcement for application development awards, signals the momentum and direction of ECP as we bring together the necessary ecosystem and infrastructure to drive the nation’s exascale imperative.â€The post Exascale Computing Project Awards $34 Million for Software Development appeared first on insideHPC.
|
 |
by Rich Brueckner on (#213F3)
In this slidecast, Gilad Shainer from Mellanox announces the world’s first HDR 200Gb/s data center interconnect solutions. "These 200Gb/s HDR InfiniBand solutions maintain Mellanox’s generation-ahead leadership while enabling customers and users to leverage an open, standards-based technology that maximizes application performance and scalability while minimizing overall data center total cost of ownership. Mellanox 200Gb/s HDR solutions will become generally available in 2017."The post Slidecast: Mellanox Announces 200Gb/s HDR InfiniBand Solutions appeared first on insideHPC.
|
 |
by staff on (#211JM)
With the SC conference returning to Salt Lake City next week, we’d like to share some of the reasons why we think SLC is one of the most underrated American cities.The post Salt Lake City Guide – A Wonder of the West appeared first on insideHPC.
|
 |
by Rich Brueckner on (#210BC)
Today StartupHPC posted their final agenda for their Workshop at SC16 in Salt Lake City. StartupHPC is focused on fostering entrepreneurship in high performance computing,†said founding member Shahin Khan of OrionX. “The StartupHPC Summit has a stellar lineup of speakers and thought leaders from the supercomputing community, and now, thanks to a generous sponsorship […]The post Free to Attend: StartupHPC Summit Monday, Nov. 14 in Salt Lake City appeared first on insideHPC.
|
 |
by Rich Brueckner on (#21002)
Today Atos announced Bull Director for HPSS, Data Management software dedicated to High Performance Computing. Bull Director for HPSS optimizes current large scale storage solutions and frees up compute time for users. "In a context of data explosion, storage is often a bottleneck and has a negative impact on application performance. Atos has a long experience of implementing HPSS in challenging environments where long-term data preservation and re-use of massive data sets are key. Our ultimate objective with Bull Director for HPSS and the other future components is to get rid of these bottlenecks and free up compute time for users." explains Eric Eppe, Head of Products and Solutions for extreme computing at Atos.The post Tackling HPC Storage Bottlenecks with Bull Director for HPSS appeared first on insideHPC.
|
 |
by Rich Brueckner on (#20ZMN)
Today ECI announced plans to demonstrate a 400G backbone at SCinet, the world's largest and fastest high-performance network at SC16 in Salt Lake City. "ECI was delighted to receive the invitation to participate in this exciting demonstration for the high performance computing sector. ECI is no stranger to this sector. We provide services to many research and education networks worldwide. Some of our wins include DFN (Germany), Switch (Sweden), GRNet (Greece), and most recently an exciting win at DeIC (Denmark), details of which will be disclosed in the near future," said Tony Gomez, VP of Business Development for ECI in N. America."The post ECI to Demo 400G Optical Backbone on SC16 SCinet appeared first on insideHPC.
|
 |
by staff on (#20ZD3)
"By joining iEnergy, Cray can offer Landmark processing customers access to its high-performance hardware platform to help software users maximize their benefits from the SeisSpace processing system,†said Steve Angelovich, SeisSpace product manager, at Halliburton Landmark. iEnergy members have this opportunity because this online technical community enables its members to work, learn, contribute, and collaborate together. Rekha Patel, ecosystem evangelist at Halliburton Landmark, said, “We welcome Cray as a new iEnergy member and look forward to the synergy between SeisSpace and Cray’s cluster systems.â€The post Cray Joins iEnergy Oil & Gas Community appeared first on insideHPC.
|
 |
by Rich Brueckner on (#20WTM)
In this slidecast, Tony DeVarco from SGI describes how the company delivers Production Supercomputing for SMEs. “As the trusted leader in high performance computing, SGI helps companies find answers to the world’s biggest challenges. Our commitment to innovation is unwavering and focused on delivering market leading solutions in Technical Computing, Big Data Analytics, and Petascale Storage. Our solutions provide unmatched performance, scalability and efficiency for a broad range of customers.â€The post Slidecast: How SGI is Meeting Manufacturing’s Need for Production Supercomputing appeared first on insideHPC.
|
 |
by Rich Brueckner on (#20WGW)
SC16 returns to Salt Lake City this year. And while SLC is known for its gorgeous views of the mountains, what our readers may not know is that Salt Lake City is full of Hip, yes hip restaurants, cafes, bars, and things to see and do. "In this feature from the Print 'n Fly Guide Guide to SC16 in Salt Lake City, we offer you some great restaurant recommendations from the locals. Plus, we'll tell you where to get great cigars, a day at the spa, and more."The post Local’s Guide to Food & Entertainment at SC16 in Salt Lake City appeared first on insideHPC.
|
 |
by staff on (#20WGY)
With SC16 coming to Salt Lake City, we asked the local's for their top pick for a great dinner place. The winner was Copper Onion. "The restaurant located on busy Broadway (and steps from the convention center) in downtown SLC, is a welcome respite from the city."The post Our Top Recommendation for a Great Dinner at SC16 in Salt Lake City appeared first on insideHPC.
|
 |
by staff on (#20W31)
In this special guest feature, Bill Mannel from Hewlett Packard Enterprise writes that upcoming Intel HPC Developer Conference in Salt Lake City is a great opportunity to learn about code modernization for the next generation of high performance computing applications. "As computing systems grow increasingly complex and new architecture designs become mainstream, training developers to write code which runs on future HPC systems will require a collaborative environment and the expertise of the best and brightest in the industry."The post Preparing Developers for Tomorrow’s Systems appeared first on insideHPC.
|
 |
by staff on (#20VGD)
Today FlyElephant announced a collaboration with HPC HUB, a developer of complex software and hardware solutions in high performance computing. Now entering its second year, FlyElephant is a platform for data scientists, engineers and researchers that accelerates their work and improves their business by automating data science and engineering simulation tasks.The post FlyElephant Collaborates with HPC-HUB for High Performance in the Cloud appeared first on insideHPC.
|
 |
by staff on (#20VCA)
Today BIOS IT announced plans for their exhibit at SC16 in Salt Lake City. BIOS IT is will be showcasing the latest HPC solutions and services, including their converged cloud platform in partnership with vScaler Ltd. "vScaler gives our clients the ability to deploy and manage HPC environments with on demand parallel file system creation within their own datacenters and when demand dictates, off-premise as well,†Ian Mellett, General Manager at BIOS IT comments.The post BIOS IT Collaborates with vScaler for HPC in the Cloud appeared first on insideHPC.
|
 |
by staff on (#20VAC)
The ExaFLOW project has announced 3.3 Million Euros of funding for a group of eight organizations to take Europe’s CFD community one step closer to performing simulations in exascale environments.The post ExaFLOW Funds CFD Research for Exascale appeared first on insideHPC.
|
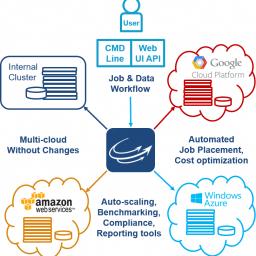 |
by Rich Brueckner on (#20V3H)
"CycleCloud has made an impact on a host of use cases - from our recently announced NASA Sub-Saharan carbon-emissions project to needs in the financial sector, manufacturing and life sciences. CycleCloud has saved countless hours overcoming the challenges typically associated with Cloud HPC and brought in real ROI,†said Jason Stowe, CEO, Cycle Computing. “Our CycleCloud V6 further optimizes what is already unique about its predecessor, bringing unmatched scalability, provisioning, and data management in a secure process. We are extremely pleased to bring V6 to market.â€The post CycleCloud V6 spins up HPC Clusters in the Cloud appeared first on insideHPC.
|
 |
by staff on (#20V08)
“We have taken a flexible and adaptive approach to multi-level security that combines recent community advances with DDN-developed Lustre features to deliver full Lustre isolation, while minimizing the performance impact of the system overhead associated with implementing security,†said Robert Triendl, senior vice president, global sales, marketing and field services, DDN. “This approach lets us customize configurations that meet our customers’ security requirements without them having to sacrifice workflow efficiency.â€The post DDN Announces Multi-Level Security Lustre Solution for HPC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#20TW4)
In this slidecast, Silicon Mechanics CTO Daniel Chow describes how the company brings value and performance to its HPC customers. "When looking for a leading solutions integrator to couple disparate hardware and software products into a “HPC Built For You†solution, that will keep up with the evolution and disruptive forces in technology – the Experts at Silicon Mechanics are here to help you."The post Slidecast: Silicon Mechanics – An Open-Technology Solutions Integrator appeared first on insideHPC.
|
 |
by staff on (#20Q19)
The OpenACC standards group today announced several major milestones including the addition of new member, the National Supercomputing Center in Wuxi, the adoption of OpenACC by several major HPC applications, the addition of support for new target platforms and expanded implementationThe post OpenACC Gains Momentum in 2016 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#20PZB)
Attendees of SC16 who are interested in open source data management will have plenty of opportunities to learn about the integrated Rule-Oriented Data System (iRODS) and the new iRODS 4.2, which will be released just in time for the conference.The post iRODS Consortium Plans Busy Week at SC16 appeared first on insideHPC.
|
 |
by staff on (#20PTV)
The Beowulf Bash returns to Salt Lake City on Monday, Nov 14. As the one party you don't want to miss, the Bash starts at 9pm, right after the SC16 opening gala. "Since its inception the Bash has been consistent about two things: 1) it is held on Monday night after the SC Opening Gala, and 2) most attendees have a darn good time. For almost a decade now the Beowulf Bash invites have come to us with a bit of an edge. We caught up with the two people who create the Beowulf Bash invitations, Lara Kisielewska of Xand McMahon and Doug Eadline of Cluster Monkey, to find out more about these unique invites."The post The 2016 Beowulf Bash Interview: The Story Behind “Beosnark†appeared first on insideHPC.
|
 |
by staff on (#20PM0)
Today Cray announced the Department of Defense High Performance Computing Modernization Program (HPCMP) has awarded the Company with a $26 million supercomputer contract for a Cray XC40 supercomputer and three Cray Sonexion storage systems.The post DoD Modernization Program to Acquire Cray XC40 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#20PM1)
In this podcast, the Radio Free HPC team previews the ancillary events around SC16 in Salt Lake City. With a full week in store, this could be the best conference yet. After our event roundup, they share their predictions for SC16 total attendance numbers.The post Radio Free HPC Does the Day-by-Day SC16 Preview Show appeared first on insideHPC.
|
 |
by Dan Olds on (#20PEF)
NVIDIA is a leading provider of GPU accelerators that are used in many High Performance Computing environments. This research paper from Gabriel Consulting Group explains the need for this new generation of hardware in today's data center and looks at what new technologies actual users are looking for.The post GPU Accelerators in Today’s Data Center: Performance & Efficiency appeared first on insideHPC.
|
 |
by staff on (#20K75)
Researchers at the Department of Energy’s SLAC National Accelerator Laboratory are playing key roles in two recently funded computing projects with the goal of developing cutting-edge scientific applications for future exascale supercomputers that can perform at least a billion billion computing operations per second – 50 to 100 times more than the most powerful supercomputers in the world today.The post SLAC & Berkeley Researchers Prepare for Exascale appeared first on insideHPC.
|
 |
by staff on (#20K38)
Today Atos in Europe announced “Atos Quantum,†an ambitious program to develop quantum computing solutions that offer unprecedented computing power, while enhancing cyber security products to face these new technologies. "Today, taking advantage of our expertise in supercomputers and cyber security, we are fully committed to the second quantum revolution that will disrupt all of our clients' business activities in the coming decades, from medicine to agriculture through finance and industries. It’s a real collective, human and technological adventure that opens up to us. For the one who liked the digital evolution they will love the quantum revolution.â€The post “Atos Quantum†Program Launches in Europe appeared first on insideHPC.
|
 |
by Rich Brueckner on (#20G5S)
NERSC is working with Cray to explore new ways to more efficiently move data in and out of Cori, a powerful supercomputer being constructed in California. "We need to take advantage of a network guru’s design for moving data for a specific experiment but have SDN do all of the bookkeeping for which compute nodes need to be connected to what networks,†said Brent Draney, group lead for the Networking, Servers and Security Group at NERSC. “I would rather see our network engineers analyze the data flow and how to meet the need instead of having to manually reconfigure the network for the demands of each job.â€The post Software Defined Networking to Speed Data for Cori Supercomputer appeared first on insideHPC.
|
 |
by staff on (#20G4M)
A panel of some of the world’s leading experts will come together to discuss this next frontier of healthcare at SC16, the premier international conference showcasing HPC on Nov. 14 in Salt Lake City. “Truly transformative discoveries are happening, and those discoveries are driving powerful shifts in how we combat disease and make people’s lives better.â€The post Precision Medicine is Next Frontier in HPC at SC16 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#20D52)
The Extreme Science and Engineering Discovery Environment (XSEDE) annual conference is transforming into an independent entity designed to unite the high-performance computing and advanced digital research community. The new Practice & Experience in Advanced Research Computing conference (PEARC) will welcome all who care about using advanced digital services for research. The PEARC17 Conference will take place in New Orleans, Louisiana, July 9-13, 2017.The post XSEDE Conference Morphs into PEARC17 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#20D1Z)
Workshop Papers from ISC 2016 are now available as a free download. "The 21 workshops were held on June 26, 2016 at the Frankfurt Marriott Hotel with over 600 registered attendees, about 170 presentations, and over a dozen panel discussions. These workshops provided a focused, in-depth platform with presentations, discussions, and interaction on topics related to all aspects of research, development, and application of large-scale, high-performance experimental and commercial systems."The post ISC 2016 Workshop Papers Available as Free Download appeared first on insideHPC.
|
 |
by staff on (#20CXD)
Today LiquidCool Solutions (LCS) announced plans to unveil two new liquid submerged servers at SC16 in Salt Lake City. Based on a clamshell design, the SCS Submerged Cloud Server is a 2U 4-node server designed for Cloud-computing applications. The SGS, Submerged GPU Server, is a 2U dual node server designed for HPC applications that can be equipped with four GPU cards or four Xeon Phi boards. Both servers are completely fanless and require no mechanical refrigeration for cooling.The post LCS to Unveil Immersive-cooled Servers at SC16 appeared first on insideHPC.
|
 |
by staff on (#20CT6)
"Our new SGI UV 300 capabilities will help us achieve major milestones sooner than predicted,†said Albert Park, senior director, Bioinformatics, AbbVie Stemcentrx. “The new SGI system is able to process larger quantities of data faster than ever and provides us with ease of management. We see significant advantages of having a single OS control our systems, including ease of use, lower power consumption and increased compute power. There’s no price tag for technology that can help discover a drug that will save millions of lives.â€The post SGI Powers Cancer Research at AbbVie Stemcentrx appeared first on insideHPC.
|
 |
by Rich Brueckner on (#20CRK)
'Trading firms in the STAC Benchmark Council designed the STAC-M3 suite to represent a range of performance challenges that are common in financial time-series analysis," said Peter Lankford, Director of STAC. "As data volumes grow and as the query demands from quants, machines, and regulators increase, it is more important than ever for tick database solutions to perform well at scale. Kx's kdb+, running on Dell EMC DSSD D5 and PowerEdge servers, has established performance records while testing on the largest STAC-M3 data scale so far."The post Kx Breaks STAC Benchmark Record with Dell EMC DSSD D5 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#20CMX)
Are you coming to SC16 in Salt Lake City? As far as transportation goes, SLC has gone through remarkable changes since we last visited at SC12. As you’ll learn in the Print ‘n Fly Guide to SC16 in Salt Lake City, a new light rail system will get you from the airport and all about town. At the same time, we’ll give you great tips to get around the new, unregulated taxi fares that could leave you feeling frustrated.The post Transportation Guide to SC16 in Salt Lake City appeared first on insideHPC.
|
|
by staff on (#208XW)
SC16 returns to Salt Lake City on Nov. 13-18. The Six-day supercomputing event features internationally-known expert speakers, cutting-edge workshops and sessions, a non-stop student competition, the world’s largest supercomputing exhibition,panel discussions and much more. "No other annual event showcases the revolutionary advances and possibilities of high performance computing than the annual ACM/IEEE International Conference for High Performance Computing, Networking, Data Storage Analysis. From the impact of HPC on the future of medicine, to its transformative power in developing countries and “smart cities.†SC is the premiere venue for presenting leading-edge HPC research."The post SC16 to Showcase Latest Advances in HPC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#208XX)
In this special guest feature, Cydney Ewald Stevens writes that Salt Lake City will soon host the return of the SC conference along with the third annual StartupHPC Workshop. "People come together at StartupHPC to learn from each other,†said founder Shahin Khan. “These are all leaders in their own right. From successful CxO’ and serial entrepreneurs to industry influencers these leaders come together each year to impart their wisdoms and experiences, share their own ‘journeys’ and help others prosper as a result.â€The post Seeking Innovators for the StartupHPC Workshop at SC16 appeared first on insideHPC.
|
|
by Rich Brueckner on (#208VX)
Today the Department of Defense High Performance Computing Modernization Program announced details of its fiscal year 2016 investment in supercomputing capability supporting the DOD science, engineering, test and acquisition engineering communities. The total life-cycle investment is valued at $63.7 million, including acquisition of three supercomputing systems with corresponding hardware and software maintenance services. With the addition of 10 petaFLOPS of computing capability, this procurement will increase the DOD HPCMP’s aggregate supercomputing capability to 31.1 petaFLOPS.The post HPC Modernization Program Boosts Supercomputing at DoD appeared first on insideHPC.
|
|
by MichaelS on (#208T0)
"Designing a new generation of hardware with such high performance needs to make sure that developers understand the basics, and are familiar with the architecture of a new system. Single thread performance with the Intel Xeon Phi processor is significantly better than previous designs. In addition, in order to speed up performance even more, vector processing, where applicable is critical in application performance. With two vector processing units (VPUs) per core, applications can execute two 512-bit vector multiply-add instructions per cycle. Each of these cores can deliver 32 double precision operations per clock cycle. The VPU executes all of the floating point operations as well as legacy instructions from SSE to AVX to the new AVX-512 instructions."The post Intel Xeon Phi Processor: A Look at the Basic Architecture appeared first on insideHPC.
|
 |
by staff on (#20862)
"OpenStack promises to be a standard platform for creating a private cloud but it can be very difficult to configure,†said Dan Kuczkowski, Senior Vice President of Worldwide Sales at Bright Computing. “We are very pleased that Stony Brook, a longtime Bright customer, trusted in the Bright platform for HPC cluster management and decided to adopt Bright OpenStack as their private cloud standard.â€The post Bright OpenStack Powers HPC at Stony Brook University appeared first on insideHPC.
|
 |
by staff on (#200Z9)
SC16 is just around the corner and there so much to explore. On suggestion is to visit with Intel learn how you can power your breakthrough innovations and discoveries with Intel Scalable System Framework. Read on for a list of SC16 events where you can experience how Intel is transforming HPC from traditional modeling and simulation to artificial intelligence, analytics, and visualization.The post Fuel Your Insight with Intel Multiple SC16 Engagement Opportunities appeared first on insideHPC.
|
 |
by staff on (#205BE)
"The market for networking devices is undergoing a major paradigm shift, moving away from closed proprietary OEM network equipment and migrating towards open platforms that are both flexible and configurable,†said Dror Goldenberg, vice president software architecture, Mellanox Technologies. “We are in full support of this movement as evidenced by our initiative to open source the entire suite of Mellanox software for our NPS family of network processors.â€The post Mellanox Launches OpenNPU for Routers, Load Balancers, and Firewalls appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2059Q)
Today the Ethernet Alliance previewed their upcoming SC16 multi-vendor interoperability demo. A premier international conference for high-performance computing, networking, storage, and analysis, SC16 is an ideal backdrop for emphasizing Ethernet’s vital role in enabling supercomputing’s continued advancement and successful future.The post Ethernet Alliance Maps Out Ethernet’s Future In HPC at SC16 appeared first on insideHPC.
|
 |
by staff on (#2057C)
"The results of DDN’s annual HPC Trends Survey reflect very accurately what HPC end users tell us and what we are seeing in their data center infrastructures. The use of private and hybrid clouds continues to grow although most HPC organizations are not storing as large a percentage of their data in public clouds as they anticipated even a year ago. Performance remains the top challenge, especially when handling mixed I/O workloads and resolving I/O bottlenecks."The post HPC Trends Survey from DDN Reveals Rising Deployment of Flash Tiers & Private/Hybrid Clouds appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2051Z)
Scot Schultz from Mellanox writes that the company is moving the industry forward to a world-class off-load network architecture that will pave the way to Exascale. "Mellanox, alongside many industry thought-leaders, is a leader in advancing the Co-Design approach. The key value and core goal is to strive for more CPU offload capabilities and acceleration techniques while maintaining forward and backward compatibility of new and existing infrastructures; and the result is nothing less than the world’s most advanced interconnect, which continues to yield the most powerful and efficient supercomputers ever deployed."The post InfiniBand: When State-of-the-Art becomes State-of-the-Smart appeared first on insideHPC.
|
 |
by staff on (#204JE)
Today IBM announced new hybrid cloud all-flash storage solutions developed to modernize and transform storage deployments, providing a strong bridge to the development of cognitive applications. These new solutions and software allow clients to store their valuable data where it makes the best business sense.The post IBM Adds New All-Flash, Software-Defined Cloud Storage Solutions appeared first on insideHPC.
|
 |
by staff on (#202PB)
In this special guest feature, Kim McMahon writes that SC16 will reflect a concerted effort to improve diversity and inclusivity at the conference. "If you want to get the best ideas, you need to ask all of the smart people what they think. HPC is really hard and have big problems to solve that solutions will impact humanity. If we are only talking to one-third of the workforce, are we finding the best ideas and solutions? By tapping into the other two thirds, we get more people and ideas to solve the big HPC problems."The post A New Focus on Diversity and Inclusivity at SC16 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#201N2)
Klaus Schulten, professor of physics and Beckman Institute faculty member for nearly 25 years, has died after an illness. Klaus Schulten was a frequent speaker at the SC conference series as well GTC and many others. "I enjoyed his talks very much and he was truly one of the great ones at conveying why HPC matters."The post Computational Biologist Klaus Schulten passes away appeared first on insideHPC.
|