
 |
by Rich Brueckner on (#201G9)
John Gustafson from A*Star will keynote the third annual StartupHPC Workshop on Nov 14 in Salt Lake City with a talk on Technology Disruption. Known to many in the HPC community as the father of Gustafson’s Law, John Gustafson was kind enough to sit down with us to share his perspectives on the current state of high performance computing. "The best way to spot a Startup opportunity is to notice an established vendor that has gotten too comfortable with its large market share, and thinks it can raise profit margins and resist the downward price pressure of Moore's law."The post Interview: John Gustafson on Technology Disruption and the StartupHPC Workshop appeared first on insideHPC.
|
| Link | http://insidehpc.com/ |
| Feed | http://insidehpc.com/feed/ |
| Updated | 2026-06-20 07:00 |
 |
by staff on (#201DB)
Today, SGI announced that the United States Department of Defense (DoD) has selected SGI ICE XA for two of its Army Research Laboratory Defense Supercomputing Resource Center systems. The upgrades are part of a technology insertion, known as TI-16, for their High Performance Computing Modernization Program (HPCMP). "We’re excited to partner with SGI for our TI-16 DoD program, and have full confidence in the system’s ability to provide excellent performance," said Dr. Raju Namburu, director of ARL DSRC. “Choosing the right HPC partners is crucial, as we rely on supercomputing and large-scale analytics and predictive sciences to provide the competitive edge we need to maintain our position as the nation’s premier laboratory for land forces.â€The post SGI Awarded $27M Systems Contract with ARL appeared first on insideHPC.
|
 |
by staff on (#201B5)
Today Cray announced that Baylor University has selected a Cray CS400 cluster supercomputer, further demonstrating its commitment to transformative research. The Cray system will serve as the primary high performance computing platform for Baylor researchers and will be supported by the Academic and Research Computing Services group (ARCS) of the Baylor University Libraries. The Cray CS400 cluster supercomputer will replace Baylor’s current HPC system, enhancing and expanding its capacity for computational research projectsThe post Cray CS400 Supercomputer Coming to Baylor University appeared first on insideHPC.
|
 |
by staff on (#20192)
Today DDN announced plans to showcase innovations in HPC leadership at SC16 in Salt Lake City. DDN will feature and demonstrate new advancements in flash for HPC, Lustre* parallel file system performance and security, and open and software-only object storage and burst buffer offerings.The post DDN to Demonstrate Latest HPC Technology at SC16 appeared first on insideHPC.
|
 |
by staff on (#20176)
Today Hewlett Packard Enterprise announced that it has completed its acquisition of SGI, a global leader in high performance solutions for compute, data analytics and data management, for $7.75 per share in cash. “This deal combines SGI’s computing strengths with HPE’s global reach,†said Antonio Neri, executive vice president and general manager, Enterprise Group, Hewlett Packard Enterprise. “SGI’s technologies and services will further our position in high-performance computing and give our customers the best of data management capabilities for real time analytics.â€The post Hewlett Packard Enterprise Completes Acquisition of SGI appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1ZY3F)
“When we started the marketplace 3 years ago the service we offered was all manual,†explained Wolfgang Gentzsch who founded UberCloud together with Burak Yenier in 2012. “But already then we were developing our HPC software container technology based on Docker which today provides a fully automated software packaging and porting environment and allows users to access their engineering workflow within seconds, at their fingertips, in any cloud. They don’t have to learn how to handle a new cloud user platform, because handling a software container provides the same look and feel identical to the engineer’s desktop.â€The post UberCloud Celebrates 3rd year of its HPC Cloud Marketplace Service appeared first on insideHPC.
|
 |
by staff on (#1ZXST)
"Engineers and scientists can now get access to HPC resources more easily because of the Fortissimo Marketplace, a new platform for brokering high-performance computing (HPC) services. The new cloud-based marketplace offers small manufacturing businesses fast and convenient access to supercomputing services.
|
 |
by Rich Brueckner on (#1ZXMP)
The Intel HPC Developer Conference at SC16 has announced its keynote speakers. Jonathan Cohen and Kai Li from Princeton will present, Going Where Neuroscience and Computer Science Have Not Gone Before. "Taking place Nov. 12-13 in Salt Lake City, the Intel HPC Developer Conference will bring together developers from around the world to discuss code modernization in high-performance computing."The post Keynotes Announced for Intel HPC Developer Conference at SC16 appeared first on insideHPC.
|
 |
by Dan Olds on (#1ZXJW)
In this research report, we reveal recent research showing that customers are feeling the need for speed—i.e. they’re looking for more processing cores. Not surprisingly, we found that they’re investing more money in accelerators like GPUs and moreover are seeing solid positive results from using GPUs. In the balance of this report, we take a look at these finding and and the newest GPU tech from NVIDIA and how it performs vs. traditional servers and earlier GPU products.The post insideHPC Research Report on GPUs appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1ZXHE)
"SC16 is really unique among conferences in the HPC community. There is simply no other conference where you can go to talk with every major participant in the HPC vendor community, see the latest research results, get HPC-specific training from the authorities in our field, mentor that next generation of leaders, and attend workshops that will shape tomorrow's technology agenda."The post Changing the Face of the SC Conference Series: An Interview with SC16 General Chair John West appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1ZTKN)
"Unchecked data growth and data sprawl are having a profound impact on life science workflows. As data volumes continue to grow, researchers and IT leaders face increasingly difficult decisions about how to manage this data yet keep the storage budget in check. Learn how these challenges can be overcome through active data management and leveraging cloud technology. The concepts will be applied to an example architecture that supports both genomic and bioimaging workflows."The post Data Storage Best Practices for Life Science Workflows appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1ZTHN)
Xilinx has announced that Baidu, a Chinese language Internet search provider, is utilizing Xilinx FPGAs to accelerate machine learning applications in its datacenters in China. "Acceleration is essential to keep up with the rapidly increasing data centre workloads that support our growth," said Yang Liu, executive director at Baidu.The post FPGAs Accelerate Machine Learning at Baidu appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1ZQWR)
Today the Gauss Centre for Supercomputing (GCS) in Germany announced it is co-sponsoring undergraduate students participating in the SC16 Student Cluster Competition (SCC). This year, GCS provides financial support for two German teams which were accepted for the multi-disciplinary HPC challenge integrated within the Supercomputing Conference 2016 (SC16) in Salt Lake City (Utah, USA): team […]The post GCS Supports Two German Teams for the SC16 Student Cluster Competition appeared first on insideHPC.
|
 |
by staff on (#1ZQTK)
Today ThinkParQ in Germany announced that RAID Inc has been selected as a North American Gold Partner for distributing the BeeGFS parallel file system. This strategic partnership will help bring BeeGFS infrastructure solutions across diverse markets as Genomics, Drug Discovery, Research, Semiconductors, and Financial Services. "BeeGFS is a file system dedicated to delivering maximum I/O performance to customers,†said Sven Breuner, CEO of ThinkParQ. “Leveraging their twenty plus years of technical computing experience in solution design, RAID Inc. is positioned to impact the HPC market by deploying all-flash systems with BeeGFS.â€The post RAID Inc. to Distribute BeeGFS in the U.S. appeared first on insideHPC.
|
 |
by staff on (#1ZMNN)
"With this award, Engility expands on our long-standing partnership with the FDA to further develop their high performance computing and complex data analysis capabilities,†said Engility CEO Lynn Dugle. “We look forward to supporting the FDA’s mission to make groundbreaking treatments, such as genetics-based medicine, available to all Americans.â€The post Engility to Build Up HPC at FDA appeared first on insideHPC.
|
 |
by staff on (#1ZMHT)
Today Ace Computers from Illinois announced that the company is integrating the new Nvidia Tesla P100 accelerators into select HPC clusters. "Nvidia has been a trusted partner for many years," said Ace Computers CEO John Samborski. "We are especially enthusiastic about this P100 accelerator and the transformative effect it promises to have on the clusters we are building for enterprises, academic institutions and research facilities.â€The post Ace Computers Adds NVIDIA Tesla P100 to HPC Clusters appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1ZMC2)
The Women in HPC network is hosting a meetup celebration at SC16. The event will take place at Nov. 15 at 7:30pm - 9:00pm at Caffé Molise in Salt Lake City. "Join us to celebrate the growing community of women in the supercomputing community and the work of WHPC. This special networking evening will include drinks and an appetizer buffet. Hosted by EPCC in collaboration with Intel, Compute Canada and McMahon Consulting, the event is a great opportunity to celebrate the work done by WHPC and meet members, founders, advocates and supporters."The post Women in HPC Celebration comes to Salt Lake City on Nov. 15 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1ZMAF)
Gary Grider from LANL presented this talk at the Storage Developer Conference. "MarFS is a Near-POSIX File System using cloud storage for data and many POSIX file systems for metadata. Extreme HPC environments require that MarFS scale a POSIX namespace metadata to trillions of files and billions of files in a single directory while storing the data in efficient massively parallel ways in industry standard erasure protected cloud style object stores."The post MarFS – A Scalable Near-POSIX File System over Cloud Objects appeared first on insideHPC.
|
 |
by staff on (#1ZM70)
Since 2008, the Intel and Cray have rapidly increased their collaboration to the benefit of the supercomputing market and customers. "Most recently, Cray has announced win after win for its Cray XC series systems that feature the Intel Xeon Phi processor, code-named Knights Landing and Knights Hill, which offers peak performance of over half-a-petaflop per cabinet—a 2X performance boost over previous generations. Cray is leading the charge toward many-core-CPU systems that boost application performance without the aid of GPUs."The post Cray and Intel Double Down on Next-gen HPC Systems appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1ZGAD)
At insideHPC, are very pleased to publish the Print ‘n Fly Guide to SC16 in Salt Lake City. We designed this Guide to be an in-flight magazine custom tailored for your journey to SC16 — the world’s largest gathering of high performance computing professionals. "Inside this guide you will find technical features on supercomputing, HPC interconnects, and the latest developments on the road to exascale. It also has great recommendations on food, entertainment, and transportation in SLC."The post It’s Here: The Print ‘n Fly Guide to SC16 in Salt Lake City appeared first on insideHPC.
|
 |
by staff on (#1ZGY3)
The National Institute of Aerospace Research in Romania will power its scientific and aeronautical research program with a new SGI UV system. "This is the second SGI system we have installed at INCAS,†said Costea Emil, head of Department Technical Services at INCAS. “SGI solutions have allowed us to rapidly develop and test our software prototypes and solutions. With our newest installation, we can reduce the time required to program algorithms, allowing us to focus on the key scientific problems we’re chartered to solve.â€The post SGI UV Powers Romanian Aerospace Agency appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1ZGTG)
Are supercomputers practical for Deep Learning applications? Over at the Allinea Blog, Mark O'Connor writes that a recent experiment with machine learning optimization on the Archer supercomputer shows that relatively simple models run at sufficiently large scale can readily outperform more complex but less scalable models. "In the open science world, anyone running a HPC cluster can expect to see a surge in the number of people wanting to run deep learning workloads over the coming months."The post Will Deep Learning Scale to Supercomputers? appeared first on insideHPC.
|
 |
by MichaelS on (#1ZGKH)
While there have been previous generations of AVX instructions, the AVX-512 instructions can significantly assist the performance of HPC applications. "The new AVX-512 instructions have been designed with developers in mind. High level languages that are used for HPC applications, such as FORTRAN and C/C++, through a compiler will be able to use the new instructions. This can be accomplished through the use of pragmas to direct the compilers to generate the new instructions, or users can use libraries which are tuned to the new technology."The post New AVX-512 Instructions Boost Performance on Intel Xeon Phi appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1ZGG2)
Growing momentum was the watchword at the inaugural OpenPOWER European Summit this week, where the OpenPOWER Foundation made a series of announcements today detailing the rapid growth, adoption and support of OpenPOWER across the continent. " With today’s announcements by our European members, the OpenPOWER Foundation expands its reach, bringing open source, high performing, flexible and scalable solutions to organizations worldwide.â€The post OpenPOWER Gains Momentum in Europe appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1ZD35)
The Networking at SC (WINS) program officially launched today. Funded through a grant from the NSF and ESnet, the program sponsors eight career women in the research and education network community to participate in the build out and live operation of SCinet. "Not only is WINS providing hands-on engineering training to the participants but also the opportunity to present their experiences with the broader networking community throughout the year."The post NSF Sponsors Women Engineers for SCinet Buildout at SC16 appeared first on insideHPC.
|
 |
by staff on (#1ZCX5)
"Pairing Tundra Relion X1904GT with our Tundra Relion 1930g, we now have a complete deep learning solution in Open Compute form factor that covers both training and inference requirements,†said William Wu, Director of Product Management at Penguin Computing. “With the ever evolving deep learning market, the X1904GT with its flexible PCI-E topologies eclipses the cookie cutter approach, providing a solution optimized for customers’ respective applications. Our collaboration with NVIDIA is combating the perennial need to overcome scaling challenges for deep learning and HPC.â€The post Penguin Computing Adds Pascal GPUs to Open Compute Tundra Systems appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1ZCW0)
"HPC is 'mainstreaming' into many industry verticals and converging with Big Data and Cloud. By 2019, HPC will account for nearly 1 in 4 of all servers sold. Our scalable, flexible market-ready solutions — with the latest Intel processors — readily handle compute and data-intensive workloads to drive breakthroughs faster. Dell supports industry, research, government and education with market-ready HPC solutions that enable more innovation and discovery. Our scalable, flexible solutions readily handle compute and data-intensive research workloads, helping drive faster breakthroughs."The post Video: Jim Ganthier on how Dell EMC Powers HPC & Big Data appeared first on insideHPC.
|
 |
by staff on (#1ZCQ4)
"We are pleased to start shipping the ConnectX-5, the industry’s most advanced network adapter, to our key partners and customers, allowing them to leverage our smart network architecture to overcome performance limitations and to gain a competitive advantage,†said Eyal Waldman, Mellanox president and CEO. “ConnectX-5 enables our customers and partners to achieve higher performance, scalability and efficiency of their InfiniBand or Ethernet server and storage platforms. Our interconnect solutions, when combined with Intel, IBM, NVIDIA or ARM CPUs, allow users across the world to achieve significant better return on investment from their IT infrastructure.â€The post Mellanox Shipping ConnectX-5 Adapter appeared first on insideHPC.
|
 |
by staff on (#1ZCJZ)
"To reinforce and continue with our pioneering work on fog computing that started in 2008, we pursue synergies between leading technology companies and academic and scientific community," said Mario Nemirovsky, Network Processors Manager at BSC. "By collaborating with the OpenFog Consortium, we will be able to contribute to the consolidation of an IoT platform for the interoperability for consumers, business, industry and research. We are looking forward to a constructive and fruitful collaborations with all OpenFog members.â€The post BSC Collaborates with OpenFog Consortium appeared first on insideHPC.
|
 |
by staff on (#1Z938)
Tomorrow's top supercomputers will require chips built using advanced lithography far beyond today's capabilities. Towards this end, Lawrence Livermore National Lab today announced a collaboration with ASML, a leading builder of chip-making machinery, to advance extreme ultraviolet (EUV) light sources toward the manufacturing of next-generation semiconductors.The post ASML taps Livermore for Extreme UV Chip Manufacturing appeared first on insideHPC.
|
 |
by staff on (#1Z91B)
Today Microsoft released an updated version of Microsoft Cognitive Toolkit, a system for deep learning that is used to speed advances in areas such as speech and image recognition and search relevance on CPUs and Nvidia GPUs. "We’ve taken it from a research tool to something that works in a production setting,†said Frank Seide, a principal researcher at Microsoft Artificial Intelligence and Research and a key architect of Microsoft Cognitive Toolkit.The post Microsoft Cognitive Toolkit Updates for Deep Learning Advances appeared first on insideHPC.
|
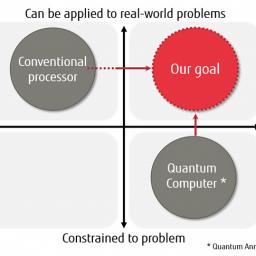 |
by Rich Brueckner on (#1Z8ZD)
Today Fujitsu Laboratories announced a collaboration with the University of Toronto to develop a new computing architecture to tackle a range of real-world issues by solving combinatorial optimization problems that involve finding the best combination of elements out of an enormous set of element combinations. "This architecture employs conventional semiconductor technology with flexible circuit configurations to allow it to handle a broader range of problems than current quantum computing can manage. In addition, multiple computation circuits can be run in parallel to perform the optimization computations, enabling scalability in terms of problem size and processing speed."The post Fujitsu Develops New Architecture for Combinatorial Optimization appeared first on insideHPC.
|
 |
by staff on (#1Z8S1)
"Performance demands on enterprise datacenters today are increasing as customers consider agile storage solutions to handle diverse workloads. The key to success is to apply the right technologies to the right workloads, and we are seeing increased adoption of hybrid arrays of HDDs and SSDs enhanced by software-based caching,†said Brian Payne, executive director, server solutions, Dell EMC. “By delivering higher performance and capacity, Seagate’s latest Enterprise Performance 15K HDD will be a sound investment for dynamic server-storage environments.â€The post Seagate Launches World’s Fastest Hard Drive appeared first on insideHPC.
|
 |
by veronicahpc1 on (#1Z8KX)
"Over the past six weeks, we took NVIDIA’s developer conference on a world tour. The GPU Technology Conference (GTC) was started in 2009 to foster a new approach to high performance computing using massively parallel processing GPUs. GTC has become the epicenter of GPU deep learning — the new computing model that sparked the big bang of modern AI. It’s no secret that AI is spreading like wildfire. The number of GPU deep learning developers has leapt 25 times in just two years."The post The Intelligent Industrial Revolution appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1Z5CE)
Next month at SC16, Dr. Thomas Schulthess from CSCS in Switzerland will present a talk entitled “Reflecting on the Goal and Baseline for Exascale Computing.†The presentation will take place on Wednesday, Nov. 15 at 11:15 am in Salt Palace Ballroom-EFGHIJ.The post Thomas Schulthess to Present Goals and Baselines for Exascale at SC16 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1Z593)
The DOD High Performance Computing Program and the U.S. Army Research Laboratory (ARL) hosted the Supercomputing Summer Institute July 18-29, 2016, at Aberdeen Proving Ground, Maryland. The program introduced students to high-tech learning opportunities.The post Students Learn HPC at ARL Supercomputing Summer Institute appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1Z55Z)
Oak Ridge National Lab is celebrating the fourth birthday of Titan, the fastest supercomputer in the U.S. that is currently ranked at #3 on the TOP500. "To celebrate Titan’s 4th “birthday†properly, the OLCF needs your help! We’re asking friends of Titan to post birthday messages, pictures, and short videos (30 seconds or less) on Twitter and Facebook using the hashtag #TitanWeek."The post ORNL Celebrates 4 Years of the Titan Supercomputer appeared first on insideHPC.
|
 |
by staff on (#1Z51A)
The Barcelona Supercomputing Center (BSC) has joined the OpenPOWER Foundation. The news will be part of a keynote address by BSC Director, Mateo Valero at the OpenPOWER Summit Europe, which takes place this week in Barcelona.The post BSC Joins OpenPOWER Foundation appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1Z4EB)
In this podcast, the Radio Free HPC team previews the SC16 Student Cluster Competition. To get us primed up, Dan gives us his impressions of the 14 teams competing this year. That's a record number! "The Student Cluster Competition was developed in 2007 to immerse undergraduate and high school students in HPC. Student teams design and build small clusters, with hardware and software vendor partners, learn designated scientific applications, apply optimization techniques for their chosen architectures, and compete in a non-stop, 48-hour challenge."The post Radio Free HPC Previews the SC16 Student Cluster Competition appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1Z219)
The Dell HPC Community at SC16 has posted their Meeting Agenda. "Blair Bethwaite from Monash University will present OpenStack for HPC at Monash. After that, Josh Simons from VMWare will describe the latest technologies in HPC virtualization." The event takes place Saturday, Nov. 12 at the Radisson Hotel in Salt Lake City.The post Speakers Announced for Dell HPC Community Meeting at SC16 appeared first on insideHPC.
|
 |
by staff on (#1Z1ZE)
Today's operating systems were not developed with the immense complexity of Exascale in mind. Now, researchers at Argonne National Lab are preparing for HPC's next wave, where the operating system will have to assume new roles in synchronizing and coordinating tasks. "The Argo team is making several of its experimental OS modifications available. Beckman expects to test them on large machines at Argonne and elsewhere in the next year."The post Argo Project Developing OS Technology for Exascale appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1YZ6W)
Intel has announced the availability of Intel Enterprise Edition for Lustre* software V3.0.1.3. This maintenance release has the latest CVE updates from RHEL 7.2. Intel also announced a pair of Lustre events coming to SC16 in Salt Lake City.The post Intel Enterprise Edition for Lustre Updates in time for SC16 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1YZ10)
In this video, Dr. Dimitri Kusnezov from the U.S. Department of Energy National Nuclear Security Administration presents: Supercomputing the Cancer Moonshot and Beyond. "How can the next generation of supercomputers unlock biomedical mysteries that will shape the future practice of medicine? Scientists behind the National Strategic Computing Initiative, a federal strategy for investing in high-performance computing, are exploring this question."The post Supercomputing the Cancer Moonshot and Beyond appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1YW3T)
IDC will hold its annual Analyst Briefing and Breakfast at SC16. Free for attendees, the event takes place 7:15 a.m. to 8:30 a.m. on Tuesday, Nov. 15 at the Hilton Salt Lake City Center. "Join IDC industry analysts as they present their expert opinions and analysis on the technical computing market and the future of high-performance computing."The post IDC Breakfast Briefing Returns to SC16 on Nov. 15 appeared first on insideHPC.
|
 |
by staff on (#1YW22)
Today Emu Technology announced that it has delivered an Emu Chick Memory Server to Oak Ridge National Laboratory. "ORNL intends to study the system for streaming graph analysis applications, sparse multilinear computations, and other memory-intensive problems, as we continue to test the potential of emerging computing technologies to further our mission within the DOE," said Jeffrey S. Vetter, Director of the Future Technologies Group at ORNL’s Computer Science and Mathematics Division.The post ORNL Testing Compact “Emu Chick†Memory Server for Big Data appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1YVY3)
Today Allinea Software announced that the compay will hold series of New Software Performance Briefings at SC16. The briefings will be held at the Allinea booth #1508 in Salt Lake City. This year at SC, we’re giving booth visitors the opportunity to find out more about what they don’t know about their software performance,†said […]The post Allinea to Offer New Software Performance Briefings at SC16 appeared first on insideHPC.
|
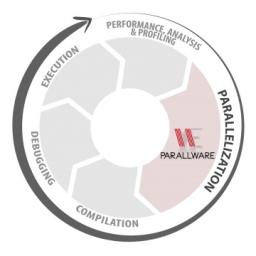 |
by Rich Brueckner on (#1YVTP)
Today European software startup Appentra announced that its Parallware technology for guided parallelization has been selected to be part of the SC16 Emerging Technologies Showcase. "As a technology with the potential to influence computing and society as a whole, Parallware is novel LLVM-Based Software Technology for Classification of Scientific Codes to Assist in Parallelization with OpenMP and OpenACC."The post Parallware Selected for SC16 Emerging Technologies Showcase appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1YVNH)
"This talk will provide empirical evidence from our Deep Speech work that application level performance (e.g. recognition accuracy) scales with data and compute, transforming some hard AI problems into problems of computational scale. It will describe the performance characteristics of Baidu's deep learning workloads in detail, focusing on the recurrent neural networks used in Deep Speech as a case study. It will cover challenges to further improving performance, describe techniques that have allowed us to sustain 250 TFLOP/s when training a single model on a cluster of 128 GPUs, and discuss straightforward improvements that are likely to deliver even better performance."The post Video: HPC Opportunities in Deep Learning appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1YR3J)
Martina Naughton presented this talk at the HPC Advisory Council Spain Conference. "IBM has a strong tradition of research collaboration with academia. We go beyond the boundaries of our IBM labs to work with colleagues in universities around the world to address global grand challenge problems. We also foster collaborative research related to transformation and innovation of businesses and governments, relationships through fellowships, grants, and funding for programs of shared interest."The post Driving Collaborative Research Partnerships at IBM appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1YR1Z)
"The work we do involves capturing and analyzing huge environmental data sets so that the government can make informed policy decisions that protect humans and the environment,†said Ron Hines, Associate Director for Health at the EPA’s National Health and Environmental Effects Research Laboratory in Research Triangle Park, N.C. “We have collaborated with the NCDS on some of its initiatives in the past and having a seat at its leadership table will help us connect with leading data researchers, access data resources and infrastructure, and contribute to the development of future NCDS strategies.â€The post EPA Joins National Consortium for Data Science appeared first on insideHPC.
|