
 |
by staff on (#2ZHS1)
Oak Ridge National Laboratory is moving equipment into a new high-performance computing center this month which is anticipated to become one of the world’s premier resources for open science computing. "There were a lot considerations to be had when designing the facilities for Summit,†explained George Wellborn, Heery Project Architect. “We are essentially harnessing a small city’s worth of power into one room. We had to ensure the confined space was adaptable for the power and cooling that is needed to run this next generation supercomputer.â€The post ORNL Readies Facility for 200 Petaflop Summit Supercomputer appeared first on insideHPC.
|
| Link | http://insidehpc.com/ |
| Feed | http://insidehpc.com/feed/ |
| Updated | 2026-06-19 22:15 |
 |
by staff on (#2ZH8N)
Santiago Nuñez-Corrales, a graduate researcher at NCSA and Ph.D. student in Informatics at the University of Illinois at Urbana-Champaign was one of twelve recipients to be awarded the SIGHPC/Intel Computational and Data Science Fellowship for 2017. "The fellowship brings with it so many benefits," said Nuñez-Corrales. "Attending SC17 is important to keep up with development in the HPC community, and the financial support is critical to continuing my degree, as I have no funding from my home country."The post Nuñez-Corrales Awarded SIGHPC Computational Data and Science Fellowship appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2ZH5D)
In this video, researchers describe how the new HPC facility at Rockefeller University will power bioinformatics research and more. This is the first time that Rockefeller University has purpose-built a datacenter for high performance computing.The post Video: HPC Powers Bioinformatics Research at Rockefeller University appeared first on insideHPC.
|
 |
by staff on (#2ZGYQ)
Researchers at RENCI are using xDCI Data CyberInfrastructure to manage brain microscopy images that were overwhelming the storage capacity at individual workstations. “BRAIN-I is a computational infrastructure for handling these huge images combined with a discovery environment where scientists can run applications and do their analysis,†explained Mike Conway, a senior data science researcher at RENCI. “BRAIN-I deals with big data and computation in a user-friendly way so scientists can concentrate on their science.â€The post xDCI Infrastructure Manages 3D Brain Microscopy Images at RENCI appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2ZGVD)
Kathy Yelick from LBNL will give the HPC keynote on Exascale computing at the upcoming ACM Europe Conference. With main themes centering on Cybersecurity and High Performance Computing, the event takes place Sept. 7-8 in Barcelona.The post Kathy Yelick to Keynote ACM Europe Conference appeared first on insideHPC.
|
 |
by Richard Friedman on (#2ZGGZ)
Employing a hybrid of MPI across nodes in a cluster, multithreading with OpenMP* on each node, and vectorization of loops within each thread results in multiple performance gains. In fact, most application codes will run slower on the latest supercomputers if they run purely sequentially. This means that adding multithreading and vectorization to applications is now essential for running efficiently on the latest architectures.The post More Than Ever, Vectorization and Multithreading are Essential for Performance appeared first on insideHPC.
|
 |
by staff on (#2ZE6W)
A new computing resource is available for Purdue researchers running applications that can take advantage of GPU accelerators. The system, known as Halstead-GPU, is a newly GPU-equipped portion of Halstead, Purdue’s newest community cluster research supercomputer. Halstead-GPU nodes consist of two 10-core Intel Xeon E5 CPUs per node, 256 GB of RAM, EDR Infiniband interconnects and two NVIDIA Tesla P100 GPUs. The GPU nodes have the same high-speed scratch storage as the main Halstead cluster.The post Purdue Adds New Resource for GPU-accelerated Research Computing appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2ZE3B)
In this video, Scott Harrison from Rock Flow Dynamics and Bruno Franzini from NICE Software explain how they scale HPC workloads in the cloud. "You'll learn how they leverage Amazon EC2 Spot instances and Amazon S3 to create cost-effective, scalable clusters that power tNavigator, Rock Flow Dynamics' solution for running dynamic reservoir simulations. You'll also see how they use NICE Software's DCV to stream the OpenGL-based user interface to interact with 3D models."The post Video: HPC Reservoir Simulations on AWS with NICE appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2ZDZS)
Illinois Rocstar is seeking a Sr. Scientific Programmer in our Job of the Week. "Have you ever thought that you’d like to write code to model something awesome? Like rockets? Aircraft? Explosions? Advanced battery performance? That’s what we do at Illinois Rocstar! Producing tools, interfaces, and systems to run on machines ranging from high-end engineering workstations to the most advanced high performance computing platforms in the world, we are all about making High Performance Computational Science and Engineering better and easier to use."The post Job of the Week: Sr. Scientific Programmer at Illinois Rocstar appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2ZDS2)
Professor Philip Diamond, Director General of the international Square Kilometer Array (SKA) project, will be the keynote speaker at SC17. "Professor Diamond, accompanied by Dr. Rosie Bolton, SKA Regional Centre Project Scientist, will take SC17 attendees around the globe and out into the deepest reaches of the observable universe as they describe the SKA’s international partnership that will map and study the entire sky in greater detail than ever before."The post Philip Diamond from SKA Project to Keynote SC17 appeared first on insideHPC.
|
 |
by staff on (#2ZB8F)
Today Dell EMC announced it will build a supercomputer to power Swinburne University of Technology’s groundbreaking research into astrophysics and gravitational waves. "We will be looking for gravitational waves that help us learn more about supernovas, the formation of stars, intergalactic gases and more,†said Professor Bailes. “It’s exciting to think that we as OzGRav could make the next landmark discovery in gravitational wave astrophysics – and the Dell EMC supercomputer will allow us to capture, visualise and process the data to make those discoveries.â€The post Dell EMC Supercomputer to Power OzGRav Studies of Black Holes appeared first on insideHPC.
|
 |
by staff on (#2ZB58)
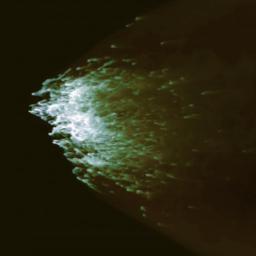
In this video from Evan Schneider at Princeton University, hot galactic winds destroy a cool cloud of interstellar gas. “The process of generating galactic winds is something that requires exquisite resolution over a large volume to understand—much better resolution than other cosmological simulations that model populations of galaxies,†Robertson said. “This is something you really need a machine like Titan to do.â€The post Video: Gas Clouds Wither in Galactic Winds appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2ZAYX)
Researchers are using XSEDE supercomputers to better understand the forces at work at the center of the Milky Way galaxy. The work could reveal how instabilities develop in extreme energy releases from black holes. "While nothing – not even light – can escape a black hole’s interior, the jets somehow manage to draw their energy from the black hole."The post How Extreme Energy Jets Escape a Black Hole appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2ZART)
Today Microsoft announced it has acquired Cycle Computing, a software company focused on making cloud computing resources more readily available for HPC workloads. "Now supporting InfiniBand and accelerated GPU computing, Microsoft Azure looks to be a perfect home for Cycle Computing, which started its journey with software for aggregating compute resources at AWS. The company later added similar capabilities for Azure and Google Cloud."The post Microsoft Acquires Cycle Computing appeared first on insideHPC.
|
 |
by staff on (#2ZAKJ)
In order to better keep a finger on the pulse of the Earth’s health, NASA developed DeepSat, a deep learning AI framework for satellite image classification and segmentation. DeepSat provides vital signs of changing landscapes at the highest possible resolution, enabling scientists to use the data for independent modeling efforts.The post DeepSat: Monitoring the Earth’s Vitals with AI appeared first on insideHPC.
|
 |
by Beth Harlen on (#2ZAGQ)
Frameworks, applications, libraries and toolkits—journeying through the world of deep learning can be daunting. If you’re trying to decide whether or not to begin a machine or deep learning project, there are several points that should first be considered. This is the first article in a five-part series that covers the steps to take before launching a machine learning startup.The post What Developers Need to Consider When Exploring Machine Learning appeared first on insideHPC.
|
 |
by staff on (#2Z7VM)
Today Insilico Medicine announced a research collaboration with The Bitfury Group, the world’s leading full-service blockchain technology conglomerate, to develop novel solutions for healthcare applications. The companies signed a memorandum of understanding (MOU) to collaborate in the academic and commercial settings to develop AI on Blockchain solutions for the healthcare industry.Blockchain can secure and streamline our medical systems, while AI has the potential to revitalize data management and machine learning to help identify trends and diseases,†said Valery Vavilov, founder, and CEO of The Bitfury Group. “By partnering with Insilico, we will be able to combine their expertise in deep learning and bioinformatics with our Blockchain proficiency and real-time solutions to create bespoke and innovative new products for the healthcare sector.â€The post AI and Blockchain Companies Partner to Advance Healthcare Research appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2Z7VP)
In this Texas Standard podcast, Dan Stanzione from TACC describes Stampede2, the most powerful university supercomputer in the United States. "Phase 1 of the Stampede2 rollout, now complete, features 4,200 Knights Landing (KNL) nodes, the second generation of processors based on Intel's Many Integrated Core (MIC) architecture. Later this summer Phase 2 will add 1,736 Intel Xeon Skylake nodes."The post Podcast: 18 Petaflop Stampede 2 Supercomputer Powers Research at TACC appeared first on insideHPC.
|
 |
by staff on (#2Z7N0)
A broad array of system administrators, developers, researchers and students who share an interest in the MVAPICH open-source library for high performance computing will gather this week for the fifth meeting of the MVAPICH Users Group (MUG). "Dr. Panda’s library is a cornerstone for HPC machines around the world, including OSC’s systems and many of the Top 500,†said Dave Hudak, Ph.D., interim executive director of OSC. “We’ve gained a lot of insight and expertise from partnering with DK and his research group throughout the years.â€The post OSC Hosts fifth MVAPICH Users Group appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2Z7JM)
In this podcast, the Radio Free HPC team looks alarming new hacks of health care data. With news that Biohackers have successfully inserted malware into DNA, security is becoming a matter of concern for everything from scanners to gene sequencers. After that, we do our Catch of the Week.The post Radio Free HPC Looks at Biohacking appeared first on insideHPC.
|
 |
by staff on (#2Z5N5)
"The Intel HPC Developer Conference 2017 has become the place for developers to learn about the latest trends, developments, and the future of HPC. By submitting an abstract and speaking at the conference you will be able to reach top-level decision makers within the HPC industry."The post Call for Abstracts: Intel HPC Developer Conference at SC17 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2Z5K8)
In this video from the Heroes of Deep Learning series, Andrew Ng interviews Head of Baidu Research, Yuanqing Lin. "Baidu Research brings together global research talent to work on AI technologies in areas such as image recognition, speech recognition, high performance computing, natural language processing and deep learning. Baidu Research comprises four labs: the Silicon Valley AI Lab, the Institute of Deep Learning, the Big Data Lab and the Augmented Reality Lab."The post Heroes of Deep Learning: Yuanqing Lin appeared first on insideHPC.
|
 |
by staff on (#2Z3GV)
"Traveling to Mars and further destinations will require more sophisticated computing capabilities to cut down on communication latencies and ensure astronauts’ survival, but existing computing resources are limited and incapable of extended periods of uptime. Settled aboard the SpaceX Dragon Spacecraft, the Spaceborne Computer is a year-long experiment from HPE and NASA—roughly the amount of time it will take to get to Mars—which will test a supercomputer’s ability to function in the harsh conditions of space."The post Video: HPE goes for Mission to Mars with Supercomputer Launch appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2Z3EF)
This week Slovenia became the ninth member state to sign the European Declaration on High Performance Computing. Designed to coordinate HPC efforts throughout Europe, the EuroHPC declaration was originally launched during Digital Day in March 2017 by France, Germany, Italy, Luxembourg, the Netherlands, Portugal and Spain. Belgium signed the declaration in June. "Providing only 5% of global HPC resources, but consuming about 30% of them, EU needs to to step up cooperation in HPC to boost Europe's scientific capabilities and industrial competitiveness. The EuroHPC goal is to to develop a high-performance computing ecosystem based on European technology, including low power chips and to have exascale supercomputers based on European technology in the global top 3 by 2022."The post Slovenia signs European Declaration on HPC appeared first on insideHPC.
|
 |
by staff on (#2Z0QE)
Today Mellanox announced the availability of storage reference platforms based on its revolutionary BlueField System-on-Chip (SoC), combining a programmable multicore CPU, networking, storage, security, and virtualization acceleration engines into a single, highly integrated device. "BlueField is the most highly integrated NVMe over Fabrics solution,†said Michael Kagan, CTO of Mellanox. “By tightly integrating high-speed networking, programmable ARM cores, PCIe switching, cache, memory management, and smart offload technology all in one chip; the result is improved performance, power consumption, and affordability for flash storage arrays. BlueField is a key part of our Ethernet Storage Fabric solution, which is the most efficient way to network and share high-performance storage.â€The post Mellanox BlueField Accelerates NVMe over Fabrics appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2Z0QG)
In this video, David Henty from EPCC conducts a video-based quiz on MPI. "The multiple-choice questions are partly designed for fun to test attendees' knowledge, but are mainly aimed at promoting discussion about MPI and its usage in real applications. All that is assumed is a working knowledge of basic MPI functionality: send, receive, collectives, derived datatypes and non-blocking communications."The post Test Your Knowledge with the MPI Quiz appeared first on insideHPC.
|
 |
by staff on (#2Z0KN)
The DOE has awarded 1 Billion CPU hours of compute time on Oak Ridge supercomputers to a set important research projects vital to our nation's future. ALCC allocations for 2017 continue in the tradition of innovation and discovery with projects awards ranging from 2 million to 300 million processor hours.The post DOE Awards 1 Billion Hours of Supercomputer Time for Research appeared first on insideHPC.
|
 |
by staff on (#2Z0KQ)
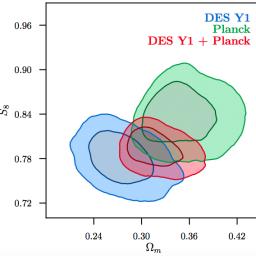
The Ohio Supercomputer Center played a critical role in helping researchers reach a milestone mapping the growth of the universe from its infancy to present day. "The new results released Aug. 3 confirm the surprisingly simple but puzzling theory that the present universe is composed of only 4 percent ordinary matter, 26 percent mysterious dark matter, and the remaining 70 percent in the form of mysterious dark energy, which causes the accelerating expansion of the universe."The post OSC Helps Map the Invisible Universe appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2YXNY)
Rutgers University is seeking an IT Manager (HPC Systems Specialist) in our Job of the Week. "This position will work closely with our dedicated and experienced staff in the setup, operation and maintenance of a rapidly growing Advanced Computational and data Infrastructure (ACI) ecosystem that includes facilities for high-performance computing and communications, data management, computational services, and advanced analytics, and supporting a diverse user community at RDI2, across Rutgers, and beyond."The post Job of the Week: IT Manager (HPC Systems Specialist) at Rutgers appeared first on insideHPC.
|
 |
by staff on (#2YXP0)
“The Value Expansion System is ideal for customers on a tight budget who need high-density PCIe expansion. Customers can utilize the 4UV for GPUs, flash or a combination of both, providing performance gains in many applications like deep learning, oil and gas exploration, financial calculations, and video rendering.â€The post One Stop Systems Rolls Out 4U Value Expansion System appeared first on insideHPC.
|
 |
by staff on (#2YXG0)
Today Intel announced its latest memory technologies to advance datacenter storage. "These new “ruler†form factor SSDs and dual port SSDs are the latest in a long line of innovations we’ve brought to market to make storing and accessing data easier and faster, while delivering more value to customers,†said Bill Leszinske, Intel vice president, Non-Volatile Memory Solutions Group (NSG), and director, strategic planning, marketing and business development. “Data drives everything we do – from financial decisions to virtual reality gaming, and from autonomous driving to machine learning – and Intel storage innovations like these ensure incredibly quick, reliable access to that data.â€The post Intel’s New “Ruler†SSD Form Factor – Up to 1 Petabyte in 1U appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2YXDH)
In this video from ISC 2017, Addison Snell from Intersect360 Research fires back at industry leaders with hard-hitting questions about the state of the HPC industry. "Listen in as visionary leaders from the supercomputing community comment on forward-looking trends that will shape the industry this year and beyond."The post HPC Analyst Crossfire at ISC 2017 appeared first on insideHPC.
|
|
by MichaelS on (#2YX71)
"Memory bandwidth to the CPUs has always been important. There were typically CPU cores that would wait for the data (if not in cache) from main memory. However, with the advanced capabilities of the Intel Xeon Phi processor, there are new concepts to understand and take advantage of."The post Feed The Cores – Memory Bandwidth Usage appeared first on insideHPC.
|
 |
by staff on (#2YTF9)
"The Micron 9200 Series of NVMe SSDs are specially designed to deliver the blazing fast speeds, low-latency, and high-capacity needed to handle massive files, images and multimedia assets created by today’s complex application workloads,†said Eric Endebrock, vice president SSD and Systems, Storage Business Unit, Micron Technology, Inc. “With the Micron 9200 SSDs added to our SSD playbook, we are providing customers a rich portfolio of storage solutions to manage their changing business needs.â€The post Micron Unveils Flagship NVMe SSD Family appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2YTBJ)
"With an interface and form factor identical to HDDs, but with vastly more capacity, ExaDrive will accelerate flash adoption in the data center. Viking Technology and SMART Modular Technologies recently began shipping 50 TB and 25 TB ExaDrive-powered SSDs for cloud infrastructure, technical computing, and digital content storage."The post Wow! Nimbus Data Unveils 50 Terabyte ExaDrive SSDs appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2YT8G)
Today the Gen-Z Consortium announced the world’s first Gen-Z multi-vendor technology demonstration, connecting compute, memory, and I/O devices at Flash Memory Summit in Santa Clara. "The demonstration utilizes FPGA-based Gen-Z adapters connecting compute nodes to memory pools through a Gen-Z switch, creating a fabric connecting multiple server vendors and a variety of memory vendors. The multi-vendor participation reflects strong industry support for Gen-Z and showcases how future data centers can leverage this technology to attain a unified, high-performance and scalable fabric/interconnect. Additionally, a separate demonstration will show the scalable prototype connector defined by the Gen-Z Consortium, running at 112 giga-transfers/sec."The post Gen-Z Multi-Vendor Technology Demo Speeds Memory-Centric Computing appeared first on insideHPC.
|
 |
by staff on (#2YT4R)
"Although many enterprises have already made the move to cloud for certain data services, many are reluctant to make the move for one of their largest investments: on-premise, high-performance computing,†said Tyler Smith, Head of Partnerships at Rescale. “Rescale helps ease the migration process with a hybrid and burst solution, making best use of existing and cloud resources in tandem, and the partnership with Equinix adds a compelling layer of ultra high-speed data transfer and best-in-class security, while allowing the enterprise to keep their preferred private/public cloud model.â€The post Rescale to Enable Fast and Secure Data Transfer to the Cloud with Equinix appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2YT2G)
In this video, Joshua Mora demonstrates how the new AMD EPYC processor delivers excellent performance for memory-bound HPC workloads including ANSYS and FLUENT. "EPYC strikes the perfect balance of cores/threads, memory, I/O bandwidth and security to deliver excellent performance for many High Performance Computing (HPC) workloads. AMD’s state-of-the-art GPUs combined with EPYC provide excellent solutions for your most demanding HPC applications."The post Video: Benchmarking AMD EPYC on Memory-Bound HPC Applications appeared first on insideHPC.
|
 |
by Sarah Rubenoff on (#2YSRH)
Businesses with I/O-intensive computing environments run into new software challenges almost daily – and many of these concerns today revolve around storage as data continues to grow. DDN is working to help solve one of the challenges to avoid storage bottlenecks. Download this paper to learn about a new software solution that manages at-scale flash to eliminate file system bottlenecks and voids old rules for I/O application optimization.The post How to Avoid Storage Bottlenecks in the Flash Era appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2YQ26)
Over at IBM, Sumit Gupta writes that the company has enabled record-breaking image recognition capabilities that make Deep Learning much more practical at scale. "The bottom line is that the record IBM broke slashes Deep Learning training time from days to hours, which will enable customers to more easily address larger technical challenges significantly faster."The post IBM Scales TensorFlow and Caffe to 256 GPUs appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2YPW7)
In this video from PRACEdays17, Thomas Skordas describes the future challenges of HPC in Europe and the key role of PRACE in the European HPC ecosystem. "PRACEdays17 included keynotes about European and international HPC strategy, scientific achievements, and industrial applications of HPC. The Barcelona Supercomputing Center hosted an enjoyable environment and an excellent organization."The post Future HPC Challenges for Europe appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2YPS1)
In this special guest feature, Dr Rosemary Francis from Ellexus describes why the HPC Community has little to fear from the rise of Cloud Computing. "AWS alone has eight different types of storage that vary hugely in terms of storage size, bandwidth, peak performance and other more complex metrics. It’s not a ‘one set-up’ solution. If you’ve spent time optimizing your on-prem cluster for each different run or set of user expectations, you’re just going to have to do the same in the cloud."The post Will the Cloud steal my job? appeared first on insideHPC.
|
 |
by staff on (#2YPJK)
Many of the biggest challenges in current data center deployments involve moving and protecting the massive amount of data that is used by today’s leading companies. In this sponsored post from One Stop Systems, Inc., Tom Matson, Director of Software Solutions Sales at SanDisk, explains how a successful data solution is built. "With flash migrating from PCIe to NVMe, OSS continues to offer a “one-stop†hardware and software solution for high-performance AFA storage that combines their industry-leading systems with the latest version of high-performance ION software."The post Building a True Data Solution appeared first on insideHPC.
|
 |
by staff on (#2YPC9)
Today Seagate announced enhanced versions of two flash technologies to boost performance and capacity for mixed data center workloads. The updated solid-state drives — including the Nytro 5000 M.2 non-volatile memory express (NVMe) SSD and the Nytro 3000 Serial Attached SCSI (SAS) SSD — address different segments of the cloud and data center markets and help organizations maximize the value of their data. Anticipating the needs of a range of hyperscale data centers and cloud providers in the future, Seagate also will highlight a 64-terabyte (TB) NVMe add-in card (AIC) reading 13 gigabytes per second (GB/s) — the fastest and highest-capacity SSD ever demonstrated. "Seagate is investing heavily in their already broad range of NVMe and SAS enterprise-class products aimed directly at the data center, cloud, and hyperscale storage markets,†said George Crump, lead analyst of Storage Switzerland. “With some product specifications increasing by as much as five times over the last generation, these products are ideally aligned to meet the ever expanding requirements of this market.â€The post Seagate Updates Nytro Flash Storage appeared first on insideHPC.
|
 |
by staff on (#2YM68)
Today DDN announced a strategic partnership with Gatan to deliver groundbreaking solutions for microscopy research environments and workflows. With innovative solutions that combine DDN’s high-performance data storage platform and Gatan’s high-performance cameras, the DDN and Gatan partnership offers a wide variety of end-user applications a powerful, end-to-end solution to accelerate research, to speed time to results, and to fully leverage the power of the latest technologies in electron microscopy. "Massive increases in instrument data are revolutionizing life science and materials research and, at the same time, are placing unprecedented demands on storage,†said Robert Triendl, senior vice president of global sales, marketing, and field services at DDN.The post DDN Drives Microscopy Workflows with Gatan appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2YKWM)
"One of today’s great challenges in physics is to observe individual dark matter particles coming in from the galaxy and striking particles on Earth. This talk presents the evidence for dark matter and introduces one of the most ambitious efforts to discover interactions of dark matter particles, using tons of cryogenic liquid in a deep underground laboratory."The post Video: Dark Matter – Detecting Gravity’s Hidden Hand appeared first on insideHPC.
|
 |
by staff on (#2YKSK)
Today XSEDE announced a pilot-phase program meant to give users ready access to HPC expertise. Called ECSS (Extended Collaborative Support Services), ECSS service allows researchers with XSEDE supercomputer allocations to collaborate with HPC experts to enhance their project workflow and hopefully get better results more efficiently. “The Affiliates program will provide a vehicle for including qualified contributors on projects, expanding the impact of ECSS and also bringing us expertise in new areas,†said ECSS Affiliates program lead and XSEDE co-PI Nancy Wilkins-Diehr. “The program provides opportunities for Affiliates to get involved in cutting edge projects that they may not see at their own institutions, and it gives ECSS a way to bring in additional expertise."The post New XSEDE program makes HPC expertise more accessible appeared first on insideHPC.
|
|
by Rich Brueckner on (#2YKK7)
In this podcast, the Radio Free HPC team looks at the problems with IEEE Floating Point. “As described in a recent presentation by John Gustafson, the flaws and idiosyncrasies of floating-point arithmetic 'constitute a sizable portion of any curriculum on Numerical Analysis.' The whole thing has Dan pretty worked up, so we hope that the news of Posit Computing coming to the new processors from Rex Computing will help.â€The post Radio Free HPC Looks at Posit Computing appeared first on insideHPC.
|
 |
by staff on (#2YKFV)
Described by Intel as the biggest platform advancement in a decade, the new Intel Xeon Scalable Platform accelerates high-performance computing workloads and provides new capabilities to advance emerging fields like artificial intelligence and self-driving vehicles.The post Intel Xeon Scalable Platform Enables Major Advancements for HPC appeared first on insideHPC.
|
 |
by staff on (#2YHCW)
In this podcast, University of Oregon Associate Professor Eugene Zhang and Assistant Professor Yue Zhang describe their research to help medical doctors better target cancerous tumors by using 3D modeling and simulation. "What we are hoping to achieve is we will get adaptive treatment plan and individualized for each patient. What we are trying to do here that is novel is we want to include bio mechanical modeling the simulations we want to include the tensor visualization on the material stress tensors."The post Podcast: Targeting Cancer with 3D Modeling and Simulation appeared first on insideHPC.
|