
 |
by staff on (#33368)
"Understanding and predicting material performance under extreme environments is a foundational capability at Los Alamos,†said David Teter, Materials Science and Technology division leader at Los Alamos. “We are well suited to apply our extensive materials capabilities and our high-performance computing resources to industrial challenges in extreme environment materials, as this program will better help U.S. industry compete in a global market.â€The post LANL Steps Up to HPC for Materials Program appeared first on insideHPC.
|
| Link | http://insidehpc.com/ |
| Feed | http://insidehpc.com/feed/ |
| Updated | 2026-06-19 20:30 |
 |
by Rich Brueckner on (#3336A)
Abhinav Vishnu from PNNL gave this talk at the MVAPICH User Group. "Deep Learning (DL) is ubiquitous. Yet leveraging distributed memory systems for DL algorithms is incredibly hard. In this talk, we will present approaches to bridge this critical gap. Our results will include validation on several US supercomputer sites such as Berkeley's NERSC, Oak Ridge Leadership Class Facility, and PNNL Institutional Computing."The post Scaling Deep Learning Algorithms on Extreme Scale Architectures appeared first on insideHPC.
|
 |
by staff on (#330S2)
Deep Learning was recently scaled to obtain 15PF performance on the Cori supercomputer at NERSC. Cori Phase II features over 9600 KNL processors. It can significantly impact how we do computing and what computing can do for us. In this talk, I will discuss some of the application-level opportunities and system-level challenges that lie at the heart of this intersection of traditional high performance computing with emerging data-intensive computing.The post SC17 Session Preview: Dr. Pradeep Dubey on AI & The Virtuous Cycle of Compute appeared first on insideHPC.
|
 |
by staff on (#330PT)
Researchers at the University of Minnesota are using Argonne supercomputers to to look for new ways to reduce the noise produced by jet engines. Among the loudest sources of human-made noise that exist, jet engines can produce sound in excess of 130 decibels. "The University of Minnesota team developed a new method based on input-output analysis that can predict both the downstream noise and the sideline noise. While it was thought that the sideline noise was random, the input-output modes show coherent structure in the jet that is connected to the sideline noise, such that it can be predicted and controlled."The post Supercomputing Jet Noise for a Quieter World appeared first on insideHPC.
|
 |
by staff on (#32XSV)
Gabriel Broner from Rescale gave this talk at the HPC User Forum. "HPC has transitioned from unique and proprietary designs, to clusters of many dual-CPU Intel nodes. Vendors’ products are now differentiated more by packaging, density, and cooling than the uniqueness of the architecture. In parallel, cloud computing has gained momentum in the larger IT industry. Intel is now selling more processors to run in the cloud than in company-owned facilities, and cloud is starting to drive innovation and efficiencies at a rate faster than on premises."The post Video: Will HPC Move to the Cloud? appeared first on insideHPC.
|
 |
by staff on (#32XP7)
Is your organization looking to hire HPC talent? Be sure to book a table at the SC17 Student/Post Doc Job Fair. "This face-to-face event will be held from 10 a.m. to 3 p.m. Wednesday, Nov. 15, in rooms 702-704-706 in the Colorado Convention Center. The Student/Postdoc Job Fair is open to all students and postdocs attending SC17, giving them an opportunity to meet with potential employers."The post Hiring? Sign up for the SC17 Student/Post Doc Job Fair appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32XKM)
PSSC Labs will work with BSI to create truly, turn-key HPC clusters, servers and storage solutions. PSSC Labs has already delivered several hundred computing platforms for worldwide genomics and bioinformatics research. Utilizing the PowerWulf HPC Cluster as a base solution platform, PSSC Labs and BSI can customize individual components for a specific end user’s research goals.The post PSSC Labs to Power Biosoft Devices for Genetics Research appeared first on insideHPC.
|
 |
by staff on (#32XKN)
The Paderborn Center for Parallel Computing (PC²) has been selected by Intel to host a computer cluster that uses Intel’s Xeon processor with its Arria 10 FPGA software development platform." The availability of these systems allows us to further expand our leadership in this area and – as a next step – bring Intel FPGA accelerators from the lab to HPC production systems,†says Prof. Dr. Christian Plessl, director of the Paderborn Center for Parallel Computing, who is been active in this research area for almost two decades."The post Intel awards Paderborn University a Hybrid Cluster with Arria 10 FPGAs appeared first on insideHPC.
|
 |
by staff on (#32V85)
Today Cray announced the Korea Institute of Science and Technology Information (KISTI) has awarded the Company a contract valued at more than $48 million for a Cray CS500 cluster supercomputer. The 128-rack system, which includes Intel Xeon Scalable processors and Intel Xeon Phi processors, will be the largest supercomputer in South Korea and will provide supercomputing services for universities, research institutes, and industries. "Our supercomputing division is focused on maximizing research performance while significantly reducing research duration and costs by building a top-notch supercomputing infrastructure,†said Pillwoo Lee, General Director, KISTI. “Cray’s proficiency in designing large and complex high-performance computing systems ensures our researchers can now apply highly-advanced HPC cluster technologies towards resolving scientific problems using the power of Cray supercomputers.â€The post KISTI in South Korea orders up a Cray CS500 Supercomputer appeared first on insideHPC.
|
 |
by staff on (#32TN9)
Today the good folks at the Google Compute Platform announced the availability of NVIDIA GPUs in the Cloud for multiple geographies. Cloud GPUs can accelerate workloads such as machine learning training and inference, geophysical data processing, simulation, seismic analysis, molecular modeling, genomics and many more high performance compute use cases. "Today, we're happy to make some massively parallel announcements for Cloud GPUs. First, Google Cloud Platform (GCP) gets another performance boost with the public launch of NVIDIA P100 GPUs in beta.The post NVIDIA P100 GPUs come to Google Cloud Platform appeared first on insideHPC.
|
 |
by staff on (#32THF)
"BigDL’s efficient large-scale distributed deep learning framework, built on Apache Spark, expands the accessibility of deep learning to a broader range of big data users and data scientists,†said Michael Greene, Vice President, Software and Services Group, General Manager, System Technologies and Optimization, Intel Corporation. “The integration with GigaSpaces’ in-memory insight platform, InsightEdge, unifies fast-data analytics, artificial intelligence, and real-time applications in one simplified, affordable, and efficient analytics stack.â€The post GigaSpaces Simplifies Artificial Intelligence Development with Intel BigDL appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32T7F)
In this RichReport slidecast, Dr. Nick New from Optalysys describes how the company's optical processing technology delivers accelerated performance for FFTs and Bioinformatics. "Our prototype is on track to achieve game-changing improvements to process times over current methods whilst providing high levels of accuracy that are associated with the best software processes.â€The post Slidecast: How Optalysys Accelerates FFTs with Optical Processing appeared first on insideHPC.
|
 |
by staff on (#32T3S)
Earlier this week, U.S. Secretary of Energy Rick Perry announced a new high-performance computing initiative that will help U.S. industry accelerate the development of new or improved materials for use in severe environments. "The High Performance Computing for Materials Program will provide opportunities for our industry partners to access the high-performance computing capabilities and expertise of DOE’s national labs as they work to create and improve technologies that combat extreme conditions,†said Secretary Perry.The post New HPC for Materials Program to Help American Industry appeared first on insideHPC.
|
 |
by MichaelS on (#32T0P)
"For those that develop HPC applications, there are usually two main areas that must be considered. The first is the translation of the algorithm, whether simulation based, physics based or pure research into the code that a modern computer system can run. A second challenge is how to move from the implementation of an algorithm to the performance that takes advantage of modern CPUs and accelerators."The post Intel Parallel Studio XE 2018 For Demanding HPC Applications appeared first on insideHPC.
|
 |
by staff on (#32QSY)
Today Cray announced that the Yokohama City University in Japan has put a Cray XC50-AC supercomputer into production. Located in the University’s Advanced Medical Research Center, the new Cray supercomputer will power computational drug-discovery research used in the design of new medicines. The University will also use its Cray system to conduct atomic-level molecular simulations of proteins, nucleic acids, and other complexes.The post Yokohama City University Installs Cray XC50-AC Supercomputer for Life Sciences appeared first on insideHPC.
|
 |
by staff on (#32PVD)
Optalysys, a start-up pioneering the development of light-speed optical coprocessors, today announced the company raised 3.95 million U.S. dollars from angel investors. Optalysys will use the funds to manufacture the first commercially available high-performance computing processor based on its patented optical processing technology.The post Freshly Funded Optalysys Optical Processing to Speed Genomics appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32PQT)
Today Altair announced a multi-year original equipment manufacturing (OEM) agreement with HPE. This agreement represents an expansion of the long-term partnership between HPE and SGI (whom HPE recently acquired). HPE will now be able to include Altair’s PBS Professional workload manager and job scheduler on all of HPE’s high performance computing (HPC) systems, ensuring scalability of price and performance as system sizes and CPU-core counts continue to increase.The post HPE to Bundle Altair PBS Pro Workload Manager appeared first on insideHPC.
|
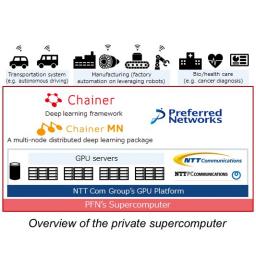 |
by staff on (#32PQW)
Today Preferred Networks announced the launch of a private supercomputer designed to facilitate research and development of deep learning, including autonomous driving and cancer diagnosis. The new 4.7 Petaflop machine is one of the most powerful to be developed by the private sector in Japan and is equipped with NTT Com and NTTPC’s GPU platform, and contains 1,024 NVIDIA Tesla P100 GPUs.The post Preferred Networks in Japan Deploys 4.7 Petaflop Supercomputer for Deep Learning appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32PMN)
Today Verne Global announced that DeepL has deployed its 5.1 petaFLOPS supercomputer in its campus in Iceland. Designed to support DeepL’s artificial intelligence driven, neural network translation service, this supercomputer is viewed by many as the world’s most accurate and natural-sounding machine translation service. “We are seeing growing interest from companies using AI tools, such as deep neural network (DNN) applications, to revolutionize how they move their businesses forward, create change, and elevate how we work, live and communicate.â€The post DeepL Deployes 5 Petaflop Supercomputer at Verne Global in Iceland appeared first on insideHPC.
|
 |
by staff on (#32PHM)
The Department of Energy’s Exascale Computing Project (ECP) has named Doug Kothe as its new director effective October 1. "Doug’s credentials in this area and familiarity with every aspect of the ECP make him the ideal person to build on the project’s strong momentum,†said Bill Goldstein, director of Lawrence Livermore National Laboratory and chairman of the ECP Board of Directors, which hired Kothe."The post Exascale Computing Project Names Doug Kothe as Director appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32KVG)
Today at the O’Reilly Artificial Intelligence Conference in San Francisco, Intel’s Lisa Spelman announced the Intel Nervana DevCloud, a cloud-hosted hardware and software platform for developers, data scientists, researchers, academics and startups to learn, sandbox and accelerate development of AI solutions with free compute cloud access powered by Intel Xeon Scalable processors. By providing compute resources for machine learning and deep learning training and inference compute needs, Intel is enabling users to start exploring AI innovation without making their own investments in compute resources up front. In addition to cloud compute resources, frameworks, tools and support are provided.The post Intel offers up AI Developer Resources in the Cloud appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32KHJ)
Researchers in China are busy upgrading the MilkyWay 2 (Tianhe-2) system to nearly 95 Petaflops (peak). This should nearly double the performance of the system, which is currently ranked at #2 on TOP500 with 33.86 Petaflops on the Linpack benchmark. The upgraded system, dubbed Tianhe -2A, should be completed in the coming months.The post China Upgrading Milky Way 2 Supercomputer to 95 Petaflops appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32KAH)
Nikunj Oza from NASA Ames gave this talk at the HPC User Forum. "This talk will give a broad overview of work at NASA in the space of data sciences, data mining, machine learning, and related areas at NASA. This will include work within the Data Sciences Group at NASA Ames, together with other groups at NASA and university and industry partners. We will delineate our thoughts on the roles of NASA, academia, and industry in advancing machine learning to help with NASA problems."The post NASA Perspectives on Deep Learning appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32K4Q)
Today Cray announced the Japan Advanced Institute for Science and Technology (JAIST) has put a Cray XC40 supercomputer into production. The Cray XC40 supercomputers incorporate the Aries high performance network interconnect for low latency and scalable global bandwidth, as well as the latest Intel Xeon processors, Intel Xeon Phi processors, and NVIDIA Tesla GPU accelerators. “Our new Cray XC40 supercomputer will support our mission of becoming a premier center of excellence in education and research.â€The post JAIST in Japan installs Cray XC40 Supercomputer appeared first on insideHPC.
|
 |
by staff on (#32K1E)
With the Earth’s population at 7 billion and growing, understanding population distribution is essential to meeting societal needs for infrastructure, resources and vital services. This article highlights how NVIDIA GPU-powered AI is accelerating mapping and analysis of population distribution around the globe. “If there is a disaster anywhere in the world,†said Bhaduri, “as soon as we have imaging we can create very useful information for responders, empowering recovery in a matter of hours rather than days.â€The post GPUs Accelerate Population Distribution Mapping Around the Globe appeared first on insideHPC.
|
 |
by staff on (#32H0Y)
Today Northrop Grumman Corporation announced they have entered into a definitive agreement to acquire Orbital ATK for approximately $7.8 billion in cash, plus the assumption of $1.4 billion in net debt. "Through our combination, customers will benefit from expanded capabilities, accelerated innovation and greater competition in critical global security domains. Our complementary portfolios and technology-focused cultures will yield significant value creation through revenue synergies associated with new opportunities, cost savings, operational synergies, and enhanced growth."The post Northrop Grumman to Acquire Orbital ATK for $9.2 Billion appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32FXJ)
Bob Sorensen from Hyperion Research describes an ongoing study on the Development Trends of Next-Generation Supercomputers. The project will gather information on pre-exascale and exascale systems today and through 2028 and build a database of technical information on the research and development efforts on these next-generation machines.The post Development Trends of Next-Generation Supercomputers appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32FXM)
In this special guest feature from Scientific Computing World, Robert Roe looks at research from the University of Alaska that is using HPC to change the way we look at the movement of ice sheets. "The computational muscle behind this research project comes from the UAF’s Geophysical Institute which houses two HPC systems ‘Chinook’, an Intel based cluster from Penguin Computing and ‘Fish’ a Cray system installed in 2012 based on the Cray XK6m-200 that uses AMD processors."The post HPC Reveals Glacial Flow appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32FTD)
Graham Anthony from BioVista gave this talk at the HPC User Forum. "We apply our systematic discovery platform to develop our pipeline of repositioned drug candidates in neurodegenerative diseases, epilepsy, oncology and orphan diseases. We use this insight to find new uses for existing drugs or drug combinations, assess their risk profile and advance them to PoC and Clinical Phase IIa/b sooner, cheaper and with a higher probability of success than has been possible to date."The post Pursuit of Sustainable Healthcare through Personalized Medicine with HPC appeared first on insideHPC.
|
 |
by staff on (#32FM5)
For the AI revolution to move into the mainstream, cost and complexity must be reduced, so smaller organizations can afford to develop, train and deploy powerful deep learning applications. It's a tough challenge. The following guest article from Intel explores how businesses can optimize AI applications and integrate them with their traditional workloads.The post The AI Revolution: Unleashing Broad and Deep Innovation appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32D7T)
SC17 continues their series of Session Previews with discussion with Dr. Catherine Graves from HP Labs about her upcoming Invited Talk. "I will present our work implementing a prototype hardware accelerator dot product engine (DPE) for vector-matrix multiplication (VMM). VMM is a bottleneck for many applications, particularly in neural networks, and can be performed in the analog domain using Ohm’s law for multiplication and Kirchoff’s current law for summation."The post SC17 Invited Talk to Look at Computing with Physics appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32D4Z)
Ashrut Ambastha from Mellanox gave this talk at the HPC Advisory Council Australia conference. "Ashrut will review Co-Design collaborations with leaders in industry, academia, and manufacturing – and how they’re taking a holistic system-level approach to fundamental performance improvements expanding the capabilities of network as a new “co-processor†for handling and accelerating application workloads, dramatically improving application performance."The post Video: The Future of High Performance Interconnects appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32AYG)
In this video from the ARM Research Summit, industry thought leaders discuss the challenges, opportunities, and technical hurdles for the ARM architecture to thrive in the HPC market. "The panel will focus on Arm in HPC, Software & Hardware differentiation and direction for exascale and beyond, thoughts on accelerators, and more!"The post Panel Looks at ARM’s Advance towards HPC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32ATV)
The Pawsey Supercomputing Centre in Australia is seeking a Visualization Specialist in our Job of the Week. "As a member of the Data and Visualization team at the Pawsey Supercomputing Centre, the Visualization Specialist will support services related to visualization including providing guidance, expert advice and helping users in designing and implementing analysis and visualization workflows."The post Job of the Week: Visualization Specialist at Pawsey Centre in Australia appeared first on insideHPC.
|
 |
by Rich Brueckner on (#32852)
In this podcast, Berkeley Lab’s Eva Nogales describes how her team is using a new imaging technology that is yielding remarkably detailed 3-D models of complex biomolecules critical to DNA function. Using cryo-electron microscopy (cryo-EM), Nogales and her colleagues have resolved the structure at near-atomic resolutions of a human transcription factor used in gene expression and DNA repair.The post Podcast: Mapping DNA at Near-Atomic Resolution with Cryo-EM appeared first on insideHPC.
|
 |
by staff on (#327YF)
Today the Krell Institute announced that new class of 20 future HPC leaders enrolled at U.S. universities this fall with support from the Department of Energy Computational Science Graduate Fellowship (DOE CSGF). "Established in 1991, the Department of Energy Computational Science Graduate Fellowship provides outstanding benefits and opportunities to students pursuing doctoral degrees in fields that use high-performance computing to solve complex science and engineering problems."The post 20 Future HPC Leaders Receive DOE Computational Science Graduate Fellowship appeared first on insideHPC.
|
 |
by Rich Brueckner on (#327YH)
SC17 continues their series of session previews with a look at an invited talk entitled “The TOP500 List – Past, Present and Future.†Published twice a year, the TOP500 list is a compilation of the world’s 500 largest installations and some of their main characteristics. Systems are ranked according to their performance on the Linpack […]The post SC17 Invited Talk to Explore the History of the TOP500 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#327RQ)
Arno Kolster from Providentia Worldwide gave this talk at the HPC User Forum in Milwaukee. "Providentia Worldwide is a new venture in technology and solutions consulting which bridges the gap between High Performance Computing and Enterprise Hyperscale computing. We take the best practices from the most demanding compute environments in the world and apply those techniques and design patterns to your business."The post Machine & Deep Learning: Practical Deployments and Best Practices for the Next Two Years appeared first on insideHPC.
|
 |
by staff on (#325FT)
Researchers are using the Theta supercomputer at Argonne to map the intricate layout of brain neurons. "The basic goal is simple — would like to be able to image all of the neurons in the brain — but the datasets from X-rays and electron microscopes are extremely large," said Doga Gursoy, assistant computational scientist in the X-Ray Science Division of Argonne’s Advanced Photon Source. They are at the tera- and petabyte scales. So we would like to use Theta to build the software and codebase infrastructure in order to analyze that data.â€The post Mapping the Brain with the Theta Supercomputer appeared first on insideHPC.
|
 |
by staff on (#324PT)
"While the notion of packaging a workload into a Docker container, publishing it to a registry, and submitting a YAML description of the workload is second nature to users of Kubernetes, this is foreign to most HPC users. An analyst running models in R, MATLAB or Stata simply wants to submit their simulation quickly, monitor their execution, and get a result as quickly as possible."The post Kubernetes Meets HPC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#324JS)
Nick Nystrom and Paola Buitrago from PSC gave this talk at the HPC User Forum in Milwaukee. "The Bridges supercomputer at PSC offers the possibility for experts in fields that never before used supercomputers to tackle problems in Big Data and answer questions based on information that no human would live long enough to study by reading it directly."The post AI Breakthroughs and Initiatives at the Pittsburgh Supercomputing Center appeared first on insideHPC.
|
 |
by staff on (#324BS)
Today NVIDIA released Version 17.7 of PGI 2017 Compilers and Tools, delivering improved performance and programming simplicity to HPC developers who target multicore CPUs and heterogeneous GPU-accelerated systems.The post New PGI 17.7 Release Supports NVIDIA Volta GPUs appeared first on insideHPC.
|
 |
by Richard Friedman on (#323WG)
Intel has announced the release of Intel® Parallel Studio XE 2018, with updated compilers and developer tools. It is now available for downloading on a 30-day trial basis. " This week’s formal release of the fully supported product is notable with new features that further enhance the toolset for accelerating HPC applications."The post Intel® Parallel Studio XE 2018 Released appeared first on insideHPC.
|
 |
by staff on (#321WA)
IBM scientists have developed a new approach to simulate molecules on a quantum computer that may one day help revolutionize chemistry and materials science. “Over the next few years, we anticipate IBM Q systems’ capabilities to surpass what today’s conventional computers can do, and start becoming a tool for experts in areas such as chemistry, biology, healthcare and materials science.â€The post IBM Simulates Chemistry with Quantum Computing appeared first on insideHPC.
|
 |
by staff on (#321FP)
As liquid cooling becomes more and more pervasive in HPC datacenters, the mitigation of leaks and spills is a growing concern. Enter CPC, a maker of quick disconnects (QDs) designed specifically for liquid cooling use. Today CPC announced its LQ Series of connectors with more robust non-spill connectors for high-performance computing and data center applications.The post CPC Enhances Non-spill Quick Disconnects for Liquid Cooled HPC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#321FR)
Craig Tierney from NVIDIA gave this talk at the MVAPICH User Group meeting. "As high performance computing moves toward GPU-accelerated architectures, single node application performance can be between 3x and 75x faster than the CPUs alone. Performance increases of this size will require increases in network bandwidth and message rate to prevent the network from becoming the bottleneck in scalability. In this talk, we will present results from NVLink enabled systems connected via quad-rail EDR Infiniband."The post Benefits of Multi-rail Cluster Architectures for GPU-based Nodes appeared first on insideHPC.
|
 |
by staff on (#321BZ)
In this special guest feature, Robert Roe from Scientific Computing World reports from the European Altair Technology Conference and finds that simulation-driven design is taking center stage for the CAE industry. "Jim Scapa from Altair noted that Scapa noted that big data and the cloud will continue to play a significant role in the development and consumption of software and that manufacturing methods and materials science would continue to drive innovations – particularly in areas such as additive manufacturing and the design of composites."The post Entering the Era of Simulation Driven Design appeared first on insideHPC.
|
 |
by Rich Brueckner on (#3219A)
Bill Kramer from NCSA gave this talk at the HPC User Forum in Milwaukee. "NCSA and Hyperion Research released a new study that examines HPC and Industry partnerships. Aimed at identifying and understanding best practices in partnerships between public high performance computing centers and private industry, the study aims to promote the vital transfer of scientific knowledge to industry and the important transfer of industrial experience to the scientific community."The post Video: Best Practices between HPC centers and Industrial Users appeared first on insideHPC.
|
 |
by staff on (#31Y7D)
Today the OpenMP ARB organization announced that Cavium has joined as a new member. "Cavium’s membership in the OpenMP ARB further highlights our strong belief in industry’s demand for parallel computing and the significance of the ARM Architecture,†said Avinash Sodani, Distinguished Engineer at Cavium. “Cavium’s strong product portfolio includes ThunderX2, a compelling server-class, multi-core ARMv8 CPU suited for the most demanding compute workloads. We look forward to working with other OpenMP members in furthering OpenMP standards to meet the challenges of the Exascale era.â€The post Cavium Joins the OpenMP Effort for ThunderX2 Processor appeared first on insideHPC.
|
 |
by staff on (#31Y0G)
Today ARM, Xilinx, Cadence, and Taiwan Semiconductor announced plans to produce the first test chip for the Cache Coherent Interconnect for Accelerators (CCIX) project. CCIX (pronounced "C6") aims to prove that many-core ARM processors linked to FPGAs have a home in HPC. "The test chip will not only demonstrate how the latest Arm technology with coherent multichip accelerators can scale across the data center, but reinforces our commitment to solving the challenge of accessing data quickly and easily."The post CCIX Project to link ARM Processors and FPGAs for HPC appeared first on insideHPC.
|