
 |
by Rich Brueckner on (#2YH95)
In this video, Ray Leto from Total Sim LLC describes how his firm uses supercomputing resources at OSC to speed NASCAR simulations. "Designers and engineers utilizing common CAD or CAE software on desktop computers often encounter limitations in the modeling and simulation (M&S) they can efficiently perform. High Performance Computing provides an improvement in computational capacity compared to typical general-purpose computers. The increased power and speed that HPC provides allows more detailed models to be simulated faster."The post HPC Speeds NASCAR at OSC appeared first on insideHPC.
|
| Link | http://insidehpc.com/ |
| Feed | http://insidehpc.com/feed/ |
| Updated | 2026-06-19 22:15 |
 |
by Rich Brueckner on (#2YF6E)
A team from the NASA has developed a new visualization tool that is being used by researchers from the Estimating the Circulation and Climate of the Ocean (ECCO) project to study the behavior of ocean currents. The new visualization tool provides high-resolution views of the entire globe at once, allowing the scientists to see new details that they had missed in previous analyses of their simulation, which was run on NASA’s Pleiades supercomputer.The post Supercomputing Ocean Currents at NASA appeared first on insideHPC.
|
 |
by staff on (#2YF4M)
Today Rescale announced a channel partnership with HPC Systems Inc., a high-performance computing hardware integrator based in Japan, to deliver Rescale’s ScaleX big compute platform to the Japanese market beginning July 2017. "We are extremely pleased to be partnering with HPC Systems, whose diverse services and products have a proven track record in Japanese computational science," said Rescale’s CEO Joris Poort. "Our partnership will provide joint customers with new potential for innovation and will accelerate research in materials and drug development and discovery."The post Rescale Partners with HPC Systems in Japan appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2YCVA)
"Dr. Gustafson has recently finished writing a book, The End of Error: Unum Computing, that presents a new approach to computer arithmetic: the unum. The universal number, or unum format, encompasses all IEEE floating-point formats as well as fixed-point and exact integer arithmetic. This approach obtains more accurate answers than floating-point arithmetic yet uses fewer bits in many cases, saving memory, bandwidth, energy, and power."The post Beating Floating Point at its own game: Posit Arithmetic appeared first on insideHPC.
|
 |
by staff on (#2YCHK)
Over at HLRS, Christopher Williams writes that the Hazel Hen supercomputer recently completed its Millionth compute job. "Leading the research behind the millionth job was Professor Bernhard Weigand, Director of the Institute of Aerospace Thermodynamics at the University of Stuttgart. His laboratory studies multiphase flows, a common phenomenon across nature in which materials in different states or phases (gases, liquids, and solids) are simultaneously present and physically interact."The post Hazel Hen Supercomputer Reaches Computational Milestone appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2YCEA)
"In today’s data-driven economy, high performance computing plays a pivotal role in driving advances in space exploration, biology and artificial intelligence,†said Meg Whitman, President and Chief Executive Officer, Hewlett Packard Enterprise. “We expect this supercomputer to help BASF perform prodigious calculations at lightning fast speeds, resulting in a broad range of innovations to solve new problems and advance our world.â€The post Video: HPE Powers 1 Petaflop QURIOSITY Supercomputer at BASF appeared first on insideHPC.
|
 |
by staff on (#2YCBX)
Today CSRA announced that the company has installed a second increment to the Biowulf supercomputing cluster at the National Institutes of Health (NIH) Center for Information Technology. Biowulf is designed to process a large number of simultaneous computations that are typical in genomics, image processing, statistical analysis, and other biomedical research areas. "We are proud to report the next stage of supercomputing power for Biowulf at NIH," said Vice President Kamal Narang, head of CSRA's Federal Health Group. "CSRA's world-renowned HPC experts partnered with NIH to make this advancement possible. Entering this new stage, NIH researchers have expanded computing power to discover new cures and save lives."The post CSRA Upgrades Biowulf Supercomputer at NIH appeared first on insideHPC.
|
 |
by staff on (#2YC5N)
Recent advancements in Artificial Intelligence, especially deep learning, are set to make an impact in the field of astronomy and astrophysics. In fact, the benefits of using AI to control space-exploring robots are already being realized by missions that are currently underway.The post Artificial Intelligence: A Journey to Deep Space appeared first on insideHPC.
|
 |
by staff on (#2Y9D8)
The National Supercomputing Center Singapore and Global Gene Corp have exchanged a Memorandum of Understanding to benefit the future of Singapore’s Precision Medicine Initiative. The collaboration allows GGC to leverage NSCC's High-Performance Computing platform for genomics applications and for NSCC to tap on GGC’s expertise to create the next generation supercomputing infrastructure which will benefit genomics and the precision medicine initiative in Singapore.The post National Supercomputing Centre Singapore and Global Gene Corp to Collaborate on Precision Medicine appeared first on insideHPC.
|
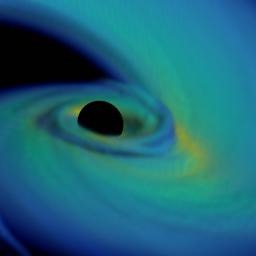 |
by staff on (#2Y99D)
Working with an international team, scientists at Berkeley Lab have developed new computer models to explore what happens when a black hole joins with a neutron star – the superdense remnant of an exploded star. "If we can follow up LIGO detections with telescopes and catch a radioactive glow, we may finally witness the birthplace of the heaviest elements in the universe,†he said. “That would answer one of the longest-standing questions in astrophysics.â€The post When Neutron Stars and Black Holes Collide appeared first on insideHPC.
|
 |
by staff on (#2Y95Z)
Where do old supercomputers go after the new machines are installed? At Durham University in the UK, they move on to a whole new mission in computational discovery. "COSMA6 enables researchers to extend large-scale structure simulations of the evolution of the universe, analyze data from gravitational wave detectors, and simulate the Sun and planets in the solar system. COSMA6 is live and operational from April 2017."The post Upcycled COSMA6 Supercomputer Finds New Life at Durham University appeared first on insideHPC.
|
 |
by Richard Friedman on (#2Y92Z)
On today’s processors, it is crucial to both vectorize (using AVX* or SIMD* instructions) and parallelize software to realize the full performance potential of the processor. By optimizing their MHD astrophysics applications with tools from Intel Parallel Studio XE, and running on the latest Intel hardware, the NSU team achieved a performance speed-up of 3X, cutting the standard time for calculating one problem from one week to just two days.The post 3X Performance Boost Using Intel Advisor and Intel Trace Analyzer in Astrophysics Simulations appeared first on insideHPC.
|
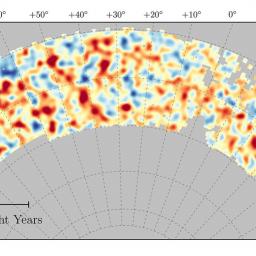 |
by staff on (#2Y930)
Researchers are using NCSA supercomputers to explore the mysteries of Dark Matter. "NCSA recognized many years ago the key role that advanced computing and data management would have in astronomy and is thrilled with the results of this collaboration with campus and our partners at Fermilab and the National Optical Astronomy Observatory,†said NCSA Director, Bill Gropp.The post Supercomputing the Dark Energy Survey at NCSA appeared first on insideHPC.
|
 |
by staff on (#2Y5X4)
Today SIGHPC announced the 12 recipients of the ACM SIGHPC/Intel Computational and Data Science Fellowships for 2017. The fellowship is funded by Intel, and is presented each year at the annual SC conference. It was established to increase the diversity of students pursuing graduate degrees in data science and computational science, including women as well as students from racial/ethnic backgrounds that have been historically underrepresented in the computing field. The fellowship provides $15,000 annually for study anywhere in the world.The post Announcing the SIGHPC/Intel Computational and Data Science Fellowship Winners appeared first on insideHPC.
|
 |
by staff on (#2Y5X6)
The UK government has contracted project management firm, Amec Foster Wheeler, to lead a £2.9 million nuclear research program. The £2.9 million contract from the Department for Business, Energy and Industrial Strategy (BEIS) will focus on the set up of a UK digital Reactor Design Partnership that will focus on the use of virtual engineering and high-performance computing (HPC) to enhance the techniques used to design reactors and optimize their performance."The post UK Funds Digital Reactor Design appeared first on insideHPC.
|
 |
by staff on (#2Y5S1)
Today Dutch cleantech company Asperitas and French green HPC service provider Qarnot announced a partnership centered around liquid cooling for datacenters. Qarnot will act as a value added reseller and operator of the Immersed Computing solution AIC24 developed by Asperitas. The AIC24 is a stand-alone plug and play solution to facilitate IT in a very energy efficient and reliable way making use of total liquid cooling. Qarnot and Asperitas are planning to deploy a showcase at the HQ of Qarnot in Paris.The post Asperitas and Qarnot Collaborate in Liquid Cooling appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2Y5S3)
"Blue Brain Project simulations use mathematical models of individual neurons and synapses to compute the electrical activity of the network as it evolves over time. This requires a huge computational effort, only possible with large supercomputers. Simulations of larger volumes of tissue, at ever higher levels of detail, will need ever more powerful computing capabilities."The post Video: I/O Challenges in Brain Tissue Simulation appeared first on insideHPC.
|
 |
by staff on (#2Y23Q)
HPE and NVIDIA are delivering IT solutions with superhuman intelligence to harness the full power of AI and pioneer the next generation of HPC systems. In this special guest feature, HPE's Vineeth Ram explores the possibilities of advancing AI capabilities with next-generation HPC solutions. "HPE is excited to complement our purpose-built systems innovation for Deep Learning and AI with the unique, industry leading strengths of the NVIDIA V100 technology architecture to accelerate insights and intelligence for our customers."The post Advancing AI Capabilities with Next-Generation HPC Solutions appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2Y2DJ)
In this video from ISC 2017, Fabrizio Magugliani from E4 Computer Engineering describes the company's innovative OP205 OpenPOWER server for HPC applications. "Our newest system, OP205 is our most advanced POWER8-based server designed for high performance computing and big data. It includes coherent accelerator processor interface (CAPI) enabled PCIe slots, and can host two NVIDIA GPUs."The post E4 Computer Engineering Demonstrates OpenPOWER Servers at ISC 2017 appeared first on insideHPC.
|
 |
by staff on (#2Y2AB)
In this special guest feature, Toni Collis from EPCC discusses her new role as SC17 Inclusivity Chair and a member of the Executive Committee. " As the leading HPC conference in the world, SC can lead the way in reducing any challenges to participation in the HPC community, thereby supporting the rapidly growing sector worldwide."The post Interview: Toni Collis on Improving Diversity at SC17 appeared first on insideHPC.
|
 |
by staff on (#2Y272)
Today Asetek announced two incremental orders from Penguin Computing, an established data center OEM. The orders are for Asetek’s RackCDU D2C™ (Direct-to-Chip) liquid cooling solution and will enable increased computing power for two currently undisclosed HPC sites at U.S. Department of Energy (DOE) National Laboratories.The post DOE Labs Adopt Asetek Liquid Cooling appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2XZ42)
SC17 has chosen six women from IT departments around the United States to participate in the Women in IT Networking at SC (WINS) program, helping to build and operate SCinet, the very high capacity SC conference network. "Now in its third year, WINS is a collaboration between UCAR, ESnet, and KINBER. Although small numbers of women have been members of SCinet since its earliest days, WINS was launched to increase the diversity of the SCinet volunteer staff and provide professional development opportunities to highly qualified women in the field of networking and computing."The post WINS Program Sponsors Six Women to Help Build SCinet at SC17 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2XZ0Q)
In this Chip Chat podcast, Lisa Spelman, Manager of Intel Xeon Products and Data Center Marketing, discusses the launch of two pivotal advances for the data center. "Intel Select Solutions are workload-optimized data center solutions that simplify and accelerate the process of selecting and deploying the hardware and software needed for today’s broad, complex array of workloads and applications."The post Podcast: Introducing Intel Xeon Scalable Processors and Intel Select Solutions appeared first on insideHPC.
|
 |
by staff on (#2XYWQ)
"Project 47 boasts 1 PetaFLOPS of compute power at full 32-bit precision delivering a stunning 30 GigaFLOPS/W, demonstrating dramatic compute efficiency. It boasts more cores, threads, compute units, IO lanes and memory channels in use at one time than in any other similarly configured system ever before. The incredible performance-per-dollar and performance-per-watt of Project 47 makes supercomputing a more affordable reality than ever before, whether for machine learning, virtualization or rendering."The post AMD Showcases 1 Petaflop “Project 47†Rack at SIGGRAPH appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2XYWS)
Blair Bethwaite and Lance Wilson from Monash University gave this talk at OpenStack Australia. "M3 is the latest generation system of the MASSIVE project, an HPC facility specializing in characterization science (imaging and visualization). Using OpenStack as the compute provisioning layer, M3 is a hybrid HPC/cloud system, custom-integrated by Monash's Research Cloud team. Built to support Monash University's high-throughput instrument processing requirements, M3 is half-half GPU-accelerated and CPU-only. We'll discuss the design and tech used to build this innovative platform as well as detailing approaches and challenges to building GPU-enabled and HPC clouds."The post Video: Building a GPU-enabled OpenStack Cloud for HPC appeared first on insideHPC.
|
 |
by staff on (#2XWHZ)
Not all HPC vendors are experiencing a slump. In fact, One Stop Systems was recently named one of San Diego’s 100 fastest growing privately-held companies by the San Diego Business Journal. "One Stop Systems continues to provide leading edge technology products to the high performance computing (HPC) market, propelling its growth,†says Steve Cooper, CEO of OSS. “Along with quality systems and responsive sales, OSS has consistently placed among the nations’ leading growth companies. In the past few years, OSS has introduced several new products that bring unparalleled performance and density to the market. We’ve also expanded into the cloud computing business by allowing customers to lease time on our HPC appliances.â€The post One Stop Systems Named One of San Diego’s Fastest Growing Companies appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2XWJ0)
"Microsoft AI researchers are striving to create intelligent machines that complement human reasoning and enrich human experiences and capabilities. At the core, is the ability to harness the explosion of digital data and computational power with advanced algorithms that extend the ability for machines to learn, reason, sense and understand—enabling collaborative and natural interactions between machines and humans."The post Video: Scalable Deep Learning with Microsoft Cognitive Toolkit (CNTK) appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2XTBP)
Lawrence Livermore National Laboratory is seeking a Research Scientist in our Job of the Week. "For more than 60 years, the Lawrence Livermore National Laboratory (LLNL) has applied science and technology to make the world a safer place. We have an opening for a research scientist with expertise in numerical or computational physics, astrophysics, or astronomy. The research will span topics in astronomical survey analysis, cosmology, optics modeling, and national security applications. This position is in the Physics Division/Applied Physics Section in the Optical Sciences group."The post Job of the Week: Research Scientist at LLNL appeared first on insideHPC.
|
 |
by staff on (#2XRFE)
DataDirect Networks has announced a trade-up program designed to offer Seagate customers a smooth transition to industry-leading DDN solutions. “It is a sad day when an industry built on long-term commitments is left in disarray, but DDN is stepping up to manage a smooth transition into the safe, stable, high-performance and industry-winning storage solutions to which every HPC customer is entitled,†said Alex Bouzari, DDN co-founder and CEO.The post DDN Announces Trade-Up Program for Seagate Customers appeared first on insideHPC.
|
 |
by staff on (#2XQCR)
Stampede2 is the newest strategic supercomputing resource for the nation's research and education community, enabling scientists and engineers across the U.S., from multiple disciplines, to answer questions at the forefront of science and engineering. "Building on the success of the initial Stampede system, the Stampede team has partnered with other institutions as well as industry to bring the latest in forward-looking computing technologies combined with deep computational and data science expertise to take on some of the most challenging science and engineering frontiers," said Irene Qualters, director of NSF's Office of Advanced Cyberinfrastructure.The post 18 Petaflop Stampede2 Supercomputer Dedicated at TACC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2XQCT)
In this video from the 2017 DDN User Group meeting at ISC, Dean Flanders, Head of Informatics/CIO at Friedrich Miescher Institute presents: Technical Challenges in Complex Bioinformatics Environments. "Dean Flanders has been Head of Informatics at the Friedrich Miescher Institute since 2000. He has been involved in many activities to enable researchers by improving IT at the national and international levels."The post Video: Technical Challenges in Complex Bioinformatics Environments appeared first on insideHPC.
|
 |
by staff on (#2XQ8T)
In this RCE Podcast, Brock Palen and Jeff Squyres speak with the authors of NetCDF. NetCDF is a set of software libraries and self-describing, machine-independent data formats that support the creation, access, and sharing of array-oriented scientific data. "Unidata’s Network Common Data Form (netCDF) is a set of software libraries and machine-independent data formats that support the creation, access, and sharing of array-oriented scientific data. It is also a community standard for sharing scientific data."The post RCE Podcast Looks at NetCDF Network Common Data Format appeared first on insideHPC.
|
 |
by staff on (#2XQ50)
Today Velocity Micro rolled out a suite of new workstation offerings designed for CAD design, 3D rendering, multimedia creation, and scientific calculation. Headlining the refreshed category are an AMD Epyc workstation with up to 64 physical cores, new Intel Xeon Scalable Processor offerings, and Threadripper, AMD’s newest Ryzen processor now available for pre-order. "Our heritage is deeply rooted in building ultra-performance workstation PCs, extending back to when I founded the company twenty years ago,†said Randy Copeland, President and CEO of Velocity Micro. “By refreshing these offerings and making AMD’s Threadripper processors available for preorder, we’re reasserting our commitment to this category and this customer with the most complete line of custom workstation solutions available anywhere.â€The post Velocity Micro Accelerates HPC Desktops appeared first on insideHPC.
|
 |
by staff on (#2XM4N)
Nick Nystrom has been appointed Interim Director of the Pittsburgh Supercomputing Center. Nystrom succeeds Michael Levine and Ralph Roskies, who have been co-directors of PSC since its founding in 1985. "During the interim period, Nystrom will oversee PSC’s state-of-the-art research into high-performance computing, data analytics, science and communications, working closely with Levine and Roskies to ensure a smooth and seamless transition."The post Nick Nystrom Named Interim Director of PSC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2XM29)
The Hot Interconnects Conference is coming up Aug. 28-30 in Santa Clara. To learn more, we caught up with Program Chairs Ryan Grant and Jitu (Jitendra) Padhye. "Hot Interconnects brings together members of the industrial, academic and broader research community to unveil the very latest advances in network technologies as well as to discuss ideas for future generation interconnects. Unlike other conferences, Hot Interconnects is focused on only the latest most topical subjects and concentrates on technologies that will be available for deployment in the near future."The post Interview: Hot Interconnects Conference to Focus on Next-Generation Networks appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2XM2B)
In this AI Podcast, Andrew NG from Deeplearning.AI describes why he thinks Artificial Intelligence is the new electricity. "Just as today I see a lot of S&P 500 CEOs that wish they had started thinking about their Internet strategy or their mobile strategy five years earlier, I think that in the future we’ll see a lot of leaders that will wish they had started to think about their AI strategy earlier,†said Ng.The post Podcast: Andrew Ng on why AI is the New Electricity appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2XKZP)
Seagate is getting out of the HPC business. Today Cray announced that it has entered into partnership agreement with Seagate centered around ClusterStor high-performance storage. "In 2012 Cray became our first OEM and has continued over the years to be our largest and most strategic ClusterStor partner," said Ken Claffey, vice president and general manager, Storage Systems Group at Seagate. "As the leader in the supercomputing market, Cray will be a great home for the ClusterStor, employees, customers and partners.â€The post Update: Approximately 100 Seagate ClusterStor Employees to Move to Cray in Strategic Transaction appeared first on insideHPC.
|
 |
by MichaelS on (#2XKWC)
"New algorithms that can query massive amounts of data an draw conclusions have been developed, but these algorithms need to be optimized on the underlying hardware. This is where the expertise of vendors who develop the hardware can add tremendous value. Optimizing the underlying libraries that can execute with a high degree of parallelism will definitely lead to improved performance for the software and productivity gains for the organization."The post Speeding Up Big Data Analysis With Intel MKL and Intel DAAL appeared first on insideHPC.
|
 |
by staff on (#2XH1N)
James Reinders writes that a new Intel Modern Code Developer Challenge has teamed up with CERN openlab. "It is always an exciting time when I get to announce a Modern Code Developer Challenge from my friends at Intel, but it is even more special when I get to announce a collaboration with the brilliant minds at CERN. Beginning this month (July 2017), and running for nine weeks, five exceptional students participating in the CERN openlab Summer Student Programme are working to research and develop solutions for five modern-code-centered challenges."The post CERN openlab Joins Intel Modern Code Developer Challenge appeared first on insideHPC.
|
 |
by staff on (#2XGV6)
"For the last two decades Herbert, working with a range of collaborators, has made a sustained series of key contributions that have helped shape the current networked infrastructure to support scholarship,†noted CNI executive director Clifford Lynch. “While many people accomplish one really important thing in their careers, I am struck by the breadth and scope of his contributions.†Lynch added, “I’ve had the privilege of working with Herbert on several of these initiatives over the years, and I was honored in 2000 to be invited to serve as a special external member of the PhD committee at the University of Ghent, where he received his doctorate.â€The post LANL’s Herbert Van de Sompel to Receive Paul Evan Peters Award appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2XGPV)
Six proposals have been selected to participate in a new partnership between two U.S. Department of Energy (DOE) user facilities through the “Facilities Integrating Collaborations for User Science†(FICUS) initiative. The expertise and capabilities available at the DOE Joint Genome Institute (JGI) and the National Energy Research Scientific Computing Center (NERSC) – both at the Lawrence Berkeley National Laboratory (Berkeley Lab) - will help researchers explore the wealth of genomic and metagenomic data generated worldwide through access to supercomputing resources and computational science experts to accelerate discoveries.The post DOE Helps Tackle Biology’s Big Data appeared first on insideHPC.
|
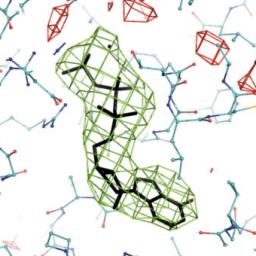 |
by staff on (#2XGPX)
The National Institutes of Health (NIH) has awarded $9.3 million to the Department of Energy’s Lawrence Berkeley National Laboratory (Berkeley Lab) to support ongoing development of PHENIX, a software suite for solving three-dimensional macromolecular structures. "The impetus behind PHENIX is a desire to make the computational aspects of crystallography more automated, reducing human error and speeding solutions,†said PHENIX principal investigator Paul Adams, director of Berkeley Lab’s Molecular Biophysics and Integrated Bioimaging Division."The post Cryo-EM Moves Forward with $9.3M NIH Award appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2XGJQ)
In this video from OpenStack Australia, David Perry from the University of Melbourne presents: Supercomputing by API - Connecting Modern Web Apps to HPC. "OpenStack is a free and open-source set of software tools for building and managing cloud computing platforms for public and private clouds. OpenStack Australia Day is the region’s largest, and Australia’s best, conference focusing on Open Source cloud technology. Gathering users, vendors and solution providers, OpenStack Australia Day is an industry event to showcase the latest technologies and share real-world experiences of the next wave of IT virtualization."The post Supercomputing by API: Connecting Modern Web Apps to HPC appeared first on insideHPC.
|
 |
by staff on (#2XGA5)
Mellanox Technologies' Vice President of Marketing, Gilad Shainer, discusses the University of Alaska Fairbanks and Mellanox’s high performance computing work that is tracking the Earth's most massive ice shelves. Essentially, the simulations needed to track the massive ice sheet’s progress require extremely large resolutions, large outputs and high computational demands – all of which requires massive computational power.The post Using HPC to Track Massive Ice Shelves appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2XDFJ)
Today HPC Cloud provider Rescale announced that Gabriel Broner has joined the company as Vice President and General Manager of High Performance Computing. "Rescale offers HPC users the possibility to instantly run simulations on large systems with the architecture of their choice, which enables companies to accelerate the pace of innovation,†said Broner. “I am very excited to join this talented group of people at Rescale who are driving the next big disruption in HPC.â€The post Gabriel Broner Joins Rescale as VP & GM of HPC appeared first on insideHPC.
|
 |
by staff on (#2XDFM)
Today Oak Ridge National Laboratory (ORNL) announced they’re bringing on D-Wave to use quantum computing as an accelerator for the Exascale Computing Project. "Advancing the problem-solving capabilities of quantum computing takes dedicated collaboration with leading scientists and industry experts,†said Robert “Bo†Ewald, president of D-Wave International. “Our work with ORNL’s exceptional community of researchers and scientists will help us understand the potential of new hybrid computing architectures, and hopefully lead to faster and better solutions for critical and complex problems.â€The post ORNL Taps D-Wave for Exascale Computing Project appeared first on insideHPC.
|
 |
by staff on (#2XD7J)
TACC will soon deploy Phase 2 of the Stampede II supercomputer. In this podcast, they celebrate by looking back on some of the great science computed on the original Stampede machine. "In 2017, the Stampede supercomputer, funded by the NSF, completed its five-year mission to provide world-class computational resources and support staff to more than 11,000 U.S. users on over 3,000 projects in the open science community. But what made it special? Stampede was like a bridge that moved thousands of researchers off of soon-to-be decommissioned supercomputers, while at the same time building a framework that anticipated the eminent trends that came to dominate advanced computing."The post Podcast: A Retrospective on Great Science and the Stampede Supercomputer appeared first on insideHPC.
|
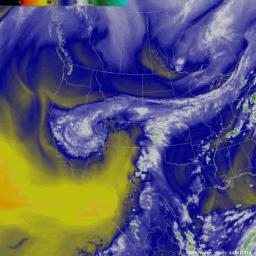 |
by staff on (#2XD3Y)
Researchers are using supercomputers at LBNL to determine how global climate change has affected the severity of storms and resultant flooding. "The group used the publicly available model, which can be used to forecast future weather, to “hindcast†the conditions that led to the Sept. 9-16, 2013 flooding around Boulder, Colorado."The post Supercomputers turn the clock back on Storms with “Hindcasting†appeared first on insideHPC.
|
 |
by staff on (#2XCXA)
Unless you reduce node and rack density, the wattages of today's high-poweredCPUs and GPUs are simply no longer addressable with air cooling alone. Asetek explores how new processors, such as Intel's Xeon Scalable processors, often call for more than just air cooling. "The largest Xeon Phi direct-to-chip cooled system today is Oakforest-PACS system in Japan. The system is made up of 8,208 computational nodes using Asetek Direct-to-Chip liquid cooled Intel Xeon Phi high performance processors with Knights Landing architecture. It is the highest performing system in Japan and #7 on the Top500."The post Intel’s Xeon Scalable Processors Provide Cooling Challenges for HPC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2XA84)
In this video, the U.S. Department of Energy gives a quick tour of all 17 National Labs. Each one comes with a surprising story on what these labs do for us as a Nation. "And they all do really different stuff. Think of a big scientific question or challenge, and one or more of the labs is probably working on it."The post Surprising Stories from 17 National Labs in 17 Minutes appeared first on insideHPC.
|