
 |
by Rich Brueckner on (#2MNM4)
The National Security Agency in Maryland is seeking an HPC Software Engineer in our Job of the Week. "NSA's High Performance Computing team develops and integrates advanced architectures and unique technologies to sustain its world-class HPC inventory. Applicants have the opportunity to research, design, develop, program, integrate, and test HPCs and all related components. NSA stays abreast of, and utilizes, new and emerging HPC technologies to address NSA's unique and critical mission."The post Job of the Week: HPC Software Engineer at the NSA appeared first on insideHPC.
|
| Link | http://insidehpc.com/ |
| Feed | http://insidehpc.com/feed/ |
| Updated | 2026-06-20 01:45 |
 |
by staff on (#2MNG5)
Today Intel and the Jülich Supercomputing Centre together with ParTec and Dell today announced plans to develop and deploy a next-generation modular supercomputing system. Leveraging the experience and results gained in the EU-funded DEEP and DEEP-ER projects, in which three of the partners have been strongly engaged, the group will develop the necessary mechanisms required to augment JSC’s JURECA cluster with a highly-scalable component named “Booster†and being based on Intel’s Scalable Systems Framework (Intel SSF).The post Jülich to Build 5 Petaflop Supercomputing Booster with Dell appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2MNE0)
Rich Brueckner from insideHPC presented this talk at the Switzerland HPC Conference. "While High Performance Computing has gone through dramatic changes since Seymour Cray created the supercomputer industry in the 1970's, misnomers, myths, and Alternative Facts have established themselves in the hive mind of the HPC community. In this session, Rich will turn the industry on its ear and reveal the whole truth in the service of outright parody."The post 10 Things You’re Wrong About in HPC appeared first on insideHPC.
|
 |
by staff on (#2MHG0)
In this special guest feature, Kim McMahon writes that helping get young people interested in STEM is the job of every HPC professional. "The ISC High Performance Conference is taking charge and educating with the establishment of a STEM Student Day at the ISC High Performance conference in Frankfurt in June. The program is new this year, and aims to bring together STEM students and HPC Community, show students the technical skills that will help them in their careers, and introduce students to the various jobs in the STEM field."The post STEM: Keeping the Interest appeared first on insideHPC.
|
 |
by staff on (#2MHCH)
More than 200 New Mexico students and teachers from 55 different teams came together in Albuquerque the week to showcase their computing research projects at the 27th annual New Mexico Supercomputing Challenge expo and awards ceremony. "It is encouraging to see the excitement generated by the participants and the great support provided by all the volunteers involved in the Supercomputing Challenge,†said David Kratzer of the Laboratory’s High Performance Computing Division, the Los Alamos coordinator of the Supercomputing Challenge.The post LANL Prepares Next Generation of HPC Professionals at New Mexico High School Supercomputing Challenge appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2MH74)
"The project, called ExaNeSt, is based on ARM processors, originally developed for mobile and embedded applications. Where ExaNeSt differs from Mont Blanc, however, is a focus on networking and on the design of applications. ExaNeSt is co-designing the hardware and software, enabling the prototype to run real-life evaluations – facilitating a stable, scalable platform that will be used to encourage the development of HPC applications for use on this ARM based supercomputing architecture."The post European Exascale System Interconnect & Storage appeared first on insideHPC.
|
 |
by Beth Harlen on (#2MH4P)
Recipient of a Gordon Bell Award in 2002, James Phillips has been a full-time research programmer for almost 20 years. Since 1998, he has been the lead developer of NAMD, a parallel molecular dynamics code designed for high-performance simulation of large biomolecular systems that scales beyond 200,000 cores, and is undoubtedly a Rock Star of HPC.The post Rock Stars of HPC: James Phillips appeared first on insideHPC.
|
 |
by Richard Friedman on (#2MH4R)
Intel Advisor, an integral part of Intel Parallel Studio XE 2017, can help identify portions of code that could be good candidates for parallelization (both vectorization and threading). It can also help determine when it might not be appropriate to parallelize a section of code, depending on the platform, processor, and configuration it’s running on. Intel Advisor Roofline Analysis reveals the gap between an application’s performance and its expected performance.The post Intel Advisor Roofline Analysis Finds New Opportunities for Optimizing Application Performance appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2MDHW)
"Inside a jet engine, air flowing faster than a hurricane is combined with fuel to generate heat that powers the plane. Designers are turning to supercomputers to model these complex processes to make new engines that are cleaner, quieter and cheaper. Our ï¬rst aircraft engine transformed the aviation industry. It was the 410-horsepower, airÂcooled Wasp, which delivered unprecedented performance and reliability for the time. We have been leading change ever since."The post The Past and Future of Aircraft Engine Development appeared first on insideHPC.
|
 |
by staff on (#2MDDE)
Today CoolIT Systems announced that Peter Calverley, CFO of Tela Innovations, has been elected to CoolIT’s Board of Directors. Doug Reid has retired from the Board after 5 years of service. "I am excited to join the Board of Directors at CoolIT Systems – a company leading the industry with its innovative, energy efficient direct contact liquid cooling solutions,†said Peter Calverley. “I believe CoolIT’s unmatched technology presents an enormous opportunity to facilitate a step-change in data center computational capabilities.â€The post Peter Calverley Joins CoolIT Systems’ Board of Directors appeared first on insideHPC.
|
 |
by staff on (#2MDC0)
Today Cray announced it has signed a solutions provider agreement with Mark III Systems to develop, market and sell solutions that leverage Cray’s portfolio of supercomputing and big data analytics systems. "We’re very excited to be partnering with Cray to deliver unique platforms and data-driven solutions to our joint clients, especially around the key opportunities of data analytics, artificial intelligence, cognitive compute, and deep learning,†said Chris Bogan, Mark III’s director of business development and alliances. “Combined with Mark III’s full stack approach of helping clients capitalize on the big data and digital transformation opportunities, we think that this partnership offers enterprises and organizations the ability to differentiate and win in the marketplace in the digital era.â€The post Mark III Systems Becomes Cray Solutions Provider appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2MD9V)
In this video from Switzerland HPC Conference, Michael Feldman from TOP500.org presents an annual deep dive into the trends, technologies and usage models that will be propelling the HPC community through 2017 and beyond. "Emerging areas of focus and opportunities to expand will be explored along with insightful observations needed to support measurably positive decision making within your operations."The post Video: HPC Trends for 2017 appeared first on insideHPC.
|
 |
by Beth Harlen on (#2MD63)
"Like OpenHPC on which it is based, Intel HPC Orchestrator is a middleware stack for HPC environments that sits on top of the base operating system and provides everything needed to run a variety of HPC applications from independent software vendors together on the same HPC system. The product includes tools for administration, provisioning, resource and workload management, HPC runtimes, I/O services, scientific libraries, MPI libraries, compilers and other development tools."The post Intel® HPC Orchestrator – Simplifying HPC appeared first on insideHPC.
|
 |
by staff on (#2M9HG)
Today the PEARC17 conference announced their lineup of keynote speakers. The conference takes place in July 9–13 in New Orleans.The post Paula Stephan and Paul Morin to Keynote PEARC17 in New Orleans appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2M9BM)
In this video from the HPC User Forum, Bob Sorensen from Hyperion Research moderates a panel discussion on Disruptive Technologies for HPC. "A disruptive innovation is an innovation that creates a new market and value network and eventually disrupts an existing market and value network, displacing established market leading firms, products and alliances. The term was defined and phenomenon analyzed by Clayton M. Christensen beginning in 1995."The post Panel Discussion on Disruptive Technologies for HPC appeared first on insideHPC.
|
 |
by staff on (#2M95V)
IBM and Stone Ridge Technology have announced a new performance milestone in reservoir simulation that will improve efficiency and lower the cost of production. Working with Nvidia, the companies reported that they had beat previous results using one-tenth the power and 1/100th of the space by employing GPUs alongside a GPU optimized code from Stone Ridge Technology called ECHELON.The post Echelon Code on Minksy Servers Sets Record for Oil & Gas Simulation appeared first on insideHPC.
|
 |
by staff on (#2M90H)
Enterprise customers consistently demand improved performance from every component in their HPC infrastructure, including their workload manager. Ian Lumb, Solutions Architect at Univa Corp., speaks on the importance of an innovative workload manager to overall success.The post Your Workload Manager is Your Latest X Factor appeared first on insideHPC.
|
 |
by staff on (#2M5RR)
The Argonne Leadership Computing Facility Data Science Program (ADSP) is now accepting proposals for projects hoping to gain insight into very large datasets produced by experimental, simulation, or observational methods. The larger the data, in fact, the better. Applications are due by June 15, 2017.The post Argonne Seeking Proposals to Advance Big Data in Science appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2M5N5)
In this podcast, the Radio Free HPC team looks at a recent update on the Exascale Computing Project by Paul Messina. “The Exascale Computing Project (ECP) was established with the goals of maximizing the benefits of HPC for the United States and accelerating the development of a capable exascale computing ecosystem."The post Radio Free HPC Catches Up with the Exascale Computing Project appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2M5K7)
In this video from the HPC User Forum in Santa Fe, Earl Joseph from Hyperion Research provides an HPC Market Update and results from their Exascale Tracking Study. "Formerly the IDC HPC Research Group, Hyperion Research tracks the high performance market."The post Video: 2016 HPC Market Results, Growth Projections, and Trends appeared first on insideHPC.
|
 |
by staff on (#2M5E4)
Today Mellanox announced that EDR 100Gb/s InfiniBand solutions have demonstrated from 30 to 250 percent higher HPC applications performance versus Omni-Path. These performance tests were conducted at end-user installations and Mellanox benchmarking and research center, and covered a variety of HPC application segments including automotive, climate research, chemistry, bioscience, genomics and more.The post Mellanox InfiniBand Delivers up to 250 Percent Higher ROI for HPC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2M5AJ)
High Performance Computing integrator OCF is supporting scientific research at the UK Atomic Weapons Establishment (AWE), with the design, testing and implementation of a new HPC cluster and a separate big data storage system. "The new HPC system is built on IBM’s POWER8 architecture and a separate parallel file system, called Cedar 3, built on IBM Spectrum Scale. In early benchmark testing, Cedar 3 is operating 10 times faster than the previous high-performance storage system at AWE. Both server and storage systems use IBM Spectrum Protect for data backup and recovery."The post OCF Builds POWER8 Supercomputer for Atomic Weapons Establishment in the UK appeared first on insideHPC.
|
 |
by staff on (#2M2F0)
Over at the Altair Blog, Jochen Krebs writes that the new HPC cluster at BASF will run PBS Works workload management software. "What does it take to go from months to mere days in gaining results when conducting research? Supercomputing now plays a vital role in the advancement of systems efficiency across industries. On March 17th, BASF and HPE announced in a press release that BASF has chosen HPE to build a new supercomputer for chemical research projects. HPE’s Apollo System supercomputer will help BASF to reduce computer simulation and modeling times from months to days and will drive the digitalization of BASF’s worldwide research activities."The post PBS Works will Power New Supercomputer at BASF appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2M2CT)
"This talk will present the motivating factors for considering OpenStack for the management of research computing infrastructure. Stig Telfer will give an overview of the differences in design criteria between cloud, HPC and data analytics, and how these differences can be mitigated through architectural and configuration choices of an OpenStack private cloud. Some real-world examples will be given that demonstrate the potential for using OpenStack for managing HPC infrastructure. This talk will present ways that the HPC community can gain the benefits of using software-defined infrastructure without paying the performance overhead."The post OpenStack for Research Computing appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2KZRE)
Ingolf Wittmann from IBM presented this talk for the Switzerland HPC Conference. "This presentation will point out based on real examples how HPC environments can benefit from such solutions and technologies to drive cognitive solutions, machine/deep learning where we can ask ourselves, 'What will be possible in the near future - can the future computers be smarter than humans?"The post The Computer That Could Be Smarter than Us – Cognitive Computing appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2KZP8)
Bay Area Startup 10x Genomics is seeking a Linux / Infrastructure Engineer in our Job of the Week. "We are looking for an exceptional engineer with a solid understanding of Linux, storage, and infrastructure to join our IT team. If you are a self-starter passionate about improving system uptime and performance, take pride in finding the best technology solution for a business problem, and are excited to work in a highly collaborative environment alongside a diverse team of experts every day, join us at 10x Genomics."The post Job of the Week: Linux Infrastructure Engineer at 10X Genomics appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2KVY7)
"This is the first in a series of short videos to introduce you to parallel programming with OpenACC and the PGI compilers, using C++ or Fortran. You will learn by example how to build a simple example program, how to add OpenACC directives, and to rebuild the program for parallel execution on a multicore system. To get the most out of this video, you should download the example programs and follow along on your workstation."The post Introduction to Parallel Programming with OpenACC appeared first on insideHPC.
|
 |
by staff on (#2KVT6)
This week Advanced Clustering installed a new supercomputer at Clarkson University in New York. "Our project is a small-scale super computer with a lot of horsepower for computation ability,†Liu said. “It has many servers, interconnected to look like one big machine. Research involving facial recognition, iris recognition and fingerprint recognition requires a lot of computing power, so we’re investigating how to perfect that capability and make biometrics run faster.â€The post Advanced Clustering Installs New Supercomputer at Clarkson University appeared first on insideHPC.
|
 |
by staff on (#2KVQE)
Simon Fraser University (SFU), Compute Canada and WestGrid were all part of the major new update to Canada's HPC resources with the recent announcement of the launch of the most powerful academic supercomputer in Canada, Cedar. Housed in the new data centre at SFU’s Burnaby Campus, Cedar will serve Canadian researchers across the country in all scientific disciplines by providing expanded compute, storage and cloud resources.The post Cedar Supercomputer Comes to Canada appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2KVP1)
"In this talk we will discuss a workflow for building and testing Docker containers and their deployment on an HPC system using Shifter. Docker is widely used by developers as a powerful tool for standardizing the packaging of applications across multiple environments, which greatly eases the porting efforts. On the other hand, Shifter provides a container runtime that has been specifically built to fit the needs of HPC. We will briefly introduce these tools while discussing the advantages of using these technologies to fulfill the needs of specific workflows for HPC, e.g., security, high-performance, portability and parallel scalability."The post HPC Workflows Using Containers appeared first on insideHPC.
|
 |
by staff on (#2KR7B)
Over at the Google Blog, Alex Barrett writes that an MIT math professor recently broke the record for the largest-ever Compute Engine cluster, with 220,000 cores on Preemptible VMs. According to Google, this is the largest known HPC cluster to ever run in the public cloud.The post MIT Professor Runs Record Google Compute Engine job with 220K Cores appeared first on insideHPC.
|
 |
by staff on (#2KR3E)
Today the Gauss Centre for Supercomputing in Germany announced that Prof. Dr. Michael M. Resch is the new chairman of the GCS Board of Directors. “Over the coming years, GCS is devoted to keeping its leading European position in HPC,†Resch said. "With all the challenges of architectural diversity and varying user requirements, we strongly believe that GCS will face the challenge and deliver performance not just in terms of flops, but more importantly in terms of best solutions and practices for our scientific and industrial users.â€The post Michael Resch Named Chairman of GCS in Germany appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2KR12)
Dr. Eng Lim Goh from Hewlett Packard Enterprise gave this talk at the HPC User Forum. "SGI’s highly complementary portfolio, including its in-memory high-performance data analytics technology and leading high-performance computing solutions will extend and strengthen HPE’s current leadership position in the growing mission critical and high-performance computing segments of the server market."The post Dr. Eng Lim Goh presents: HPC & AI Technology Trends appeared first on insideHPC.
|
|
by MichaelS on (#2KQYY)
"Just as developers need tools to understand the performance of a CPU intensive application in order to modify the code for higher performance, so do those that develop interactive 3D computer graphics applications. An excellent tool for t this purpose is the Intel Graphics Performance Analyzer set. This tool, which is free to download, can help the developer understand at a very low level how the application is performing, from a number of aspects."The post Intel® Graphics Performance Analyzer for Faster Graphics Performance appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2KKVF)
"Starting today, Intel will contribute all Lustre features and enhancements to the open source community. This will mean that we will no longer provide Intel-branded releases of Lustre, and instead align our efforts and support around the community release." In related news, former Whamcloud CEO and Lustre team leader Brent Gorda has left the Intel Lustre team for another management position.The post Intel to Open Source All Lustre Code as Brent Gorda Moves On appeared first on insideHPC.
|
 |
by staff on (#2KKS4)
Today PSSC Labs announced it has refreshed its CBeST (Complete Beowulf Software Toolkit) cluster management package. CBeST is already a proven platform deployed on over 2200 PowerWulf Clusters to date and with this refresh PSSC Labs is adding a host of new features and upgrades to ensure users have everything needed to manage, monitor, maintain and upgrade their HPC cluster. "PSSC Labs is unique in that we manufacture all of our own hardware and develop our own cluster management toolkits in house. While other companies simply cobble together third party hardware and software, PSSC Labs custom builds every HPC cluster to achieve performance and reliability boosts of up to 15%,†said Alex Lesser, Vice President of PSSC Labs.The post PSSC Labs Updates CBeST Cluster Management Software appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2KKKJ)
Paul Messina from Argonne presented this talk at the HPC User Forum in Santa Fe. "The Exascale Computing Project (ECP) was established with the goals of maximizing the benefits of HPC for the United States and accelerating the development of a capable exascale computing ecosystem. The ECP is a collaborative effort of two U.S. Department of Energy organizations – the Office of Science (DOE-SC) and the National Nuclear Security Administration (NNSA)."The post Update on the Exascale Computing Project (ECP) appeared first on insideHPC.
|
 |
by Beth Harlen on (#2KKCN)
This Rock Stars of HPC series is about the men and women who are changing the way the HPC community develops, deploys, and operates the supercomputers and social and economic impact of their discoveries. "As the lead developer of the VMD molecular visualization and analysis tool, John Stone’s code is used by more than 100,000 researchers around the world. He’s also a CUDA Fellow, helping to bring HPC to the masses with accelerated computing. In this way and many others, John Stone is certainly one of the Rock Stars of HPC."The post Rock Stars of HPC: John Stone appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2KG4F)
Dan Olds from OrionX.net presented this talk at the Switzerland HPC Conference. "Dan Olds will present recent research into the history of High Performance Interconnects (HPI), the current state of the HPI market, where HPIs are going in the future, and how customers should evaluate HPI options today. This will be a highly informative and interactive session."The post High Performance Interconnects – Assessments, Rankings and Landscape appeared first on insideHPC.
|
 |
by staff on (#2KG2Y)
Today the Rescale HPC Cloud introduced the ScaleX Labs with Intel Xeon Phi processors and Intel Omni-Path Fabric managed by R Systems. The collaboration brings lightning-fast, next-generation computation to Rescale’s cloud platform for big compute, ScaleX Pro. "We are proud to provide a remote access platform for Intel’s latest processors and interconnect, and appreciate the committed cooperation of our partners at R Systems,†said Rescale CEO Joris Poort. “Our customers care about both performance and convenience, and the ScaleX Labs with Intel Xeon Phi processors brings them both in a single cloud HPC solution at a price point that works for everyone.â€The post Rescale Announces ScaleX Labs with Intel Xeon Phi and Omni-Path appeared first on insideHPC.
|
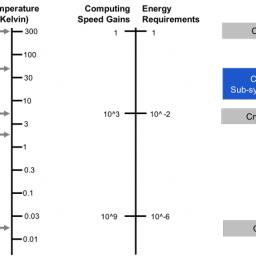 |
by staff on (#2KFRD)
"With the increasing challenges in conventional approaches to improving memory capacity and power efficiency, our early research indicates that a significant change in the operating temperature of DRAM using cryogenic techniques may become essential in future memory systems,†said Dr. Gary Bronner, vice president of Rambus Labs. “Our strategic partnership with Microsoft has enabled us to identify new architectural models as we strive to develop systems utilizing cryogenic memory. The expansion of this collaboration will lead to new applications in high-performance supercomputers and quantum computers.â€The post Rambus Collaborates with Microsoft on Cryogenic Memory appeared first on insideHPC.
|
 |
by staff on (#2KFKZ)
Today the European PRACE initiative announced that their 14th Call for Proposals yielded 113 eligible proposals of which 59 were awarded a total of close to 2 thousand million core hours. This brings the total number of projects awarded by PRACE to 524. Taking into account the 3 multi-year projects from the 12th Call that were renewed and the 10 million core hours reserved for Centres of Excellence, the total amount of core hours awarded by PRACE to more than 14 thousand million. "The 59 newly awarded projects are led by principal investigators from 15 different European countries. In addition, two projects are led by PIs from New Zealand and the USA."The post Call for Proposals reflects magnitude of PRACE 2 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2KEWM)
In this video from the Switzerland HPC Conference, Jeffrey Stuecheli from IBM presents: Open CAPI, A New Standard for High Performance Attachment of Memory, Acceleration, and Networks. "OpenCAPI sets a new standard for the industry, providing a high bandwidth, low latency open interface design specification. This session will introduce the new standard and it's goals. This includes details on how the interface protocol provides unprecedented latency and bandwidth to attached devices."The post Open CAPI: A New Standard for High Performance Attachment of Memory, Acceleration, and Networks appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2KCCG)
"HPC software is becoming increasingly complex. The space of possible build configurations is combinatorial, and existing package management tools do not handle these complexities well. Because of this, most HPC software is built by hand. This talk introduces "Spack", an open-source tool for scientific package management which helps developers and cluster administrators avoid having to waste countless hours porting and rebuilding software." A tutorial video on using Spack is also included.The post SPACK: A Package Manager for Supercomputers, Linux, and MacOS appeared first on insideHPC.
|
 |
by staff on (#2KCAV)
Today IBM announced that it will offer the Anaconda Open Data Science platform on IBM Cognitive Systems. Anaconda will also integrate with the PowerAI software distribution for machine learning and deep learning that makes it simple and fast to take advantage of Power performance and GPU optimization for data intensive cognitive workloads. "Anaconda is an important capability for developers building cognitive solutions, and now it’s available on IBM’s high performance deep learning platform,†said Bob Picciano, senior vice president of Cognitive Systems. “Anaconda on IBM Cognitive Systems empowers developers and data scientists to build and deploy deep learning applications that are ready to scale.â€The post Anaconda Open Data Science Platform comes to IBM Cognitive Systems appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2KC9A)
Today the Department of Energy’s Innovative and Novel Computational Impact on Theory and Experiment (INCITE) program announced it is accepting proposals for high-impact, computationally intensive research campaigns in a broad array of science, engineering, and computer science domains. DOE’s Office of Science plans to award over 6 billion supercomputer processor-hours at Argonne National Laboratory and […]The post DOE’s INCITE Program Seeks Advanced Computational Research Proposals for 2018 appeared first on insideHPC.
|
 |
by staff on (#2KC78)
Today IBM announced that the first annual OpenPOWER Foundation Developer Congress will take place May 22-25 in San Francisco. With a focus on Machine Learning, the conference will focus on continuing to foster the collaboration within the foundation to satisfy the performance demands of today’s computing market.The post OpenPOWER Developer Congress Event to Focus on Machine Learning appeared first on insideHPC.
|
 |
by staff on (#2KC5K)
"Baidu and NVIDIA are long-time partners in advancing the state of the art in AI,†said Ian Buck, general manager of Accelerated Computing at NVIDIA. “Baidu understands that enterprises need GPU computing to process the massive volumes of data needed for deep learning. Through Baidu Cloud, companies can quickly convert data into insights that lead to breakthrough products and services.â€The post Baidu Deep Learning Service adds Latest NVIDIA Pascal GPUs appeared first on insideHPC.
|
 |
by staff on (#2K9A7)
In this AI Podcast, Mark Michalski from the Massachusetts General Hospital Center for Clinical Data Science discusses how AI is being used to advance medicine. "Medicine — particularly radiology and pathology — have become more data-driven. The Massachusetts General Hospital Center for Clinical Data Science — led by Mark Michalski — promises to accelerate that, using AI technologies to spot patterns that can improve the detection, diagnosis and treatment of diseases."The post Podcast: How AI Can Improve the Diagnosis and Treatment of Diseases appeared first on insideHPC.
|
 |
by Rich Brueckner on (#2K993)
Luigi Brochard from Lenovo gave this talk at the Switzerland HPC Conference. "High performance computing is converging more and more with the big data topic and related infrastructure requirements in the field. Lenovo is investing in developing systems designed to resolve todays and future problems in a more efficient way and respond to the demands of Industrial and research application landscape."The post Lenovo HPC Strategy Update appeared first on insideHPC.
|