
 |
by Rich Brueckner on (#1Q6P7)
IDC has published the preliminary agenda for the next international HPC User Forum. The event will take place Sept. 29-30 in Oxford, UK.The post Agenda Posted for HPC User Forum in Oxford appeared first on insideHPC.
|
| Link | http://insidehpc.com/ |
| Feed | http://insidehpc.com/feed/ |
| Updated | 2026-06-20 08:45 |
 |
by staff on (#1Q6KT)
Today One Stop Systems (OSS) introduced a pair of high-speed networked storage appliances that supports high-performance, shared storage services. "The OSS approach optimizes the hardware for the environment and optimizes the software for the application in the Flash Storage Array for Networks product line (FSAn). This hardware and software optimization in the FSAn product line provides the best ROI in any environment by minimizing hardware and license costs through advance array-level optimizations while maximizing the utilization of the flash array through VSI and VDI application support."The post OSS Introduces Flash Appliances appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1Q6D4)
The flagship supercomputer at the Swiss National Supercomputing Centre (CSCS), Piz Daint, named after a mountain in the Alps, currently delivers 7.8 petaflops of compute performance, or 7.8 quadrillion mathematical calculations per second. A recently announced upgrade will double its peak performance, thanks to a refresh using the latest Intel Xeon CPUs and 4,500 Nvidia Tesla P100 GPUs.The post Creating Balance in HPC on the Piz Daint Supercomputer appeared first on insideHPC.
|
 |
by MichaelS on (#1Q6BJ)
"High performance systems now typically a host processor and a coprocessor. The role of the coprocessor is to provide the developer and the user the ability to significantly speed up simulations if the algorithm that is used can run with a high degree of parallelization and can take advantage of an SIMD architecture. The Intel Xeon Phi coprocessor is an example of a coprocessor that is used in many HPC systems today."The post Intel Xeon Phi Coprocessor Architecture appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1Q39P)
NCI in Australia has issued its Call for Participation for the the Down-Under version of the 2016 Lustre User Group. The event will be held Sept. 7-8 on the campus of The Australian National University in Canberra, ACT Australia. "LUG 2016 will be a dynamic two day workshop that will explore improvements in the performance and flexibility of the Lustre file system for supporting diverse workloads. This will be a great opportunity for the Lustre community to discuss the challenges associated with enhancing Lustre for diverse applications, the technological advances necessary, and the associated ecosystem."The post Call for Participation: Lustre User Group at NCI in Australia appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1Q2X1)
In this video, Dan Stanzione from TACC describes how the Stampede II supercomputer will driving computational science. "Announced in June, a $30 million NSF award to the Texas Advanced Computing Center will be used acquire and deploy a new large scale supercomputing system, Stampede II, as a strategic national resource to provide high-performance computing capabilities for thousands of researchers across the U.S. This award builds on technology and expertise from the Stampede system first funded in by NSF 2011 and will deliver a peak performance of up to 18 Petaflops, over twice the overall system performance of the current Stampede system."The post Video: Stampede II Supercomputer to Advance Computational Science at TACC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1Q2SC)
Today One Stop Systems announced the 4U Flash Storage Array with Mangstor MX6300 NVMe SSDs. OSS' FSAe-4 can accommodate 32 of the MX6300 providing up to 172TB of shared Flash storage. The FSAe-4 is a fully redundant, hot serviceable configuration with 4 independent 1U servers attached to the PCIe expansion chassis. The expansion system can support Ethernet (RoCE) or Infiniband fabrics and network speeds up to 100Gb/s.The post Mangstor MX6300 NVMe SSDs Power One Stop Systems FSAe-4 Flash Storage Array appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1Q2R3)
Today Intel announced plans to acquire startup Nervana Systems as part of an effort to bolster the company's artificial intelligence capabilities. "Nervana has a fully-optimized software and hardware stack for deep learning," said Intel's Diane Bryant in a blog post. "Their IP and expertise in accelerating deep learning algorithms will expand Intel’s capabilities in the field of AI. We will apply Nervana’s software expertise to further optimize the Intel Math Kernel Library and its integration into industry standard frameworksThe post Intel to Bolster Machine Learning with Nervana Acquisition appeared first on insideHPC.
|
 |
by MichaelS on (#1Q2KW)
The recent introduction of new high end processors from Intel combined with accelerator technologies such as NVIDIA Tesla GPUs and Intel Xeon Phi provide the raw ‘industry standard’ materials to cobble together a test platform suitable for small research projects and development. When combined with open source toolkits some meaningful results can be achieved, but wide scale enterprise deployment in production environments raises the infrastructure, software and support requirements to a completely different level.The post Components For Deep Learning appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PZE7)
"The ExaFlash Platform is an historic achievement that will reshape the storage and data center industries," said Thomas Isakovich, CEO and Founder of Nimbus Data. "It offers unprecedented scale (from terabytes to exabytes), record-smashing efficiency (95% lower power and 50x greater density than existing all-flash arrays), and a breakthrough price point (a fraction of the cost of existing all-flash arrays). ExaFlash brings the all-flash data center dream to reality and will help empower humankind’s innovation for decades to come."The post Nimbus Data Rolls Out ExaFlash Storage Platform appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PZ60)
"We’ve seen the rapid evolution of SSDs and have been contributing to the NVMe over Fabrics standard and community drivers,†said Michael Kagan, CTO at Mellanox Technologies. “Because faster storage requires faster networks, we designed the highest-speeds and most intelligent offloads into both our ConnectX-5 and BlueField families. This lets us connect many SSDs directly to the network at full speed, without the need to dedicate many CPU cores to managing data movement, and we provide a complete end-to-end networking solution with the highest-performing 25, 50, and 100GbE switches and cables as well.â€The post New Mellanox Networking Solutions Accelerate NVMe Over Fabrics appeared first on insideHPC.
|
 |
by staff on (#1PZ42)
Today the Ethernet Alliance unveiled the agenda for its 2016 Technology Exploration Forum (TEF 2016). At the center of the day’s agenda is Ethernet’s quickening journey through its next decade of continuous technology evolution and growth as the marketplace continues to change. TEF 2016: The Road to Ethernet 2026 is scheduled for September 29, 2016, at the Santa Clara County Convention Center, Santa Clara, Calif.The post Ethernet Alliance Technology Forum Looks to 2026 appeared first on insideHPC.
|
 |
by staff on (#1PZ2K)
Today Seagate announced two new flash innovations that extend the limits of storage computing performance in enterprise data centers to unprecedented levels. The new products include a 60 terabyte SAS solid-state-drive — the largest SSD ever demonstrated — and the 8TB Nytro XP7200 NVMe SSD. These two new products represent the high performance end of Seagate’s Enterprise portfolio – a complete ecosystem of HDD, SSD and storage system products designed to help customers manage the deluge of data they face and move the right data where it’s needed fast to meet rapidly evolving business priorities and market demands.The post Seagate Unveils 60 Terabyte SSD appeared first on insideHPC.
|
 |
by staff on (#1PZ0W)
"Fujitsu Laboratories has newly developed parallelization technology to efficiently share data between machines, and applied it to Caffe, an open source deep learning framework widely used around the world. Fujitsu Laboratories evaluated the technology on AlexNet, where it was confirmed to have achieved learning speeds with 16 and 64 GPUs that are 14.7 and 27 times faster, respectively, than a single GPU. These are the world's fastest processing speeds(2), representing an improvement in learning speeds of 46% for 16 GPUs and 71% for 64 GPUs."The post Fujitsu Develops High-Speed Software for Deep Learning appeared first on insideHPC.
|
by staff on (#1PYR0)
Advancements in video technology have slowly pushed applications like video editing, video rendering and video storage editing into the High Performance Computing world. There are many different video editing programs that can cut, trim, re-sequence, and add sound, transitions and special effects to video. But with the introduction of 4K/8K video, a simple laptop isn’t powerful enough on its own anymore, especially for online editing.The post High Performance 4K Video Storage, Editing and Rendering appeared first on insideHPC.
 |
by staff on (#1PWB8)
Today One Stop Systems introduced the Magma StorageBox 1000 PCIe expansion system. Targeted for HPC applications, the SBB1000 provides up to 25.6TB of NVMe SSD direct attached storage through eight 2.5" drives to any standard server.The post OSS Rolls Out Magma StorageBox 1000 PCIe Expansion Chassis appeared first on insideHPC.
|
 |
by staff on (#1PW3J)
Today HPC cloud provider Nimbix announced a significant increase in their presence in the machine learning market space as more customers are using their JARVICE platform to help address the need for an easier, more cost efficient way of working with machine learning. "The Nimbix Cloud was a great choice for our research tasks in conversational AI. They are one of the first cloud services to provide NVIDIA Tesla K80 GPUs that were essential for computing neural networks that are implemented as part of Luka's AI,†said Phil Dudchuck, Co-Founder at Luka.ai.The post Nimbix Speeds Cloud-based Machine Learning appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PW0N)
Today Netlist announced the first public demonstration of its HybriDIMM Storage Class Memory (SCM) product at the upcoming Flash Memory Summit. Using an industry standard DDR4 LRDIMM interface, HybriDIMM is the first SCM product to operate in current Intel x86 servers without BIOS and hardware changes, and the first unified DRAM-NAND solution that scales memory to terabyte storage capacities and accelerates storage to nanosecond memory speeds.The post Netlist HybriDIMM Memory Unifies DRAM-NAND appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PVZ7)
Is Machine Learning more of a Data Movement problem than a Processing problem? In this podcast, the Radio Free HPC team looks at use cases for Machine Learning where data locality is critical for performance. "Most of the Machine Learning hearing stories we hear involve a central data repository. Henry says he is not hearing enough about how Machine Learning is going to deal with the problem of massive data streams from things like sensors. Such data, he contends, will have to be processed at the source."The post Radio Free HPC Looks at Machine Learning and Data Locality appeared first on insideHPC.
|
 |
by staff on (#1PVSE)
Today E8 Storage launched the storage industry’s first-ever centralized, highly available rack scale flash appliance based on Non-Volatile Memory express (NVMe) drives. The E8-D24 is the first array that combines the high performance of NVMe drives, the high availability and reliability of centralized storage, and the high scalability of scale-out solutions.The post E8 Storage Launches NVMe Rack Scale Flash Appliance appeared first on insideHPC.
|
 |
by staff on (#1PVQ4)
Today the Green500 released their listing of the world's most energy efficient supercomputers. "Japan’s research institution RIKEN once again captured the top spot with its Shoubu supercomputer. With rating of 6673.84 MFLOPS/Watt, Shoubu edged out another RIKEN system, Satsuki, the number 2 system that delivered 6195.22 MFLOPS/Watt. Both are “ZettaScalerâ€supercomputers, employing Intel Xeon processors and PEZY-SCnp manycore accelerators.The post Riken’s Shoubu Supercomputer Leads Green500 List appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PS7D)
AMD’s motivation for developing these open-source GPU tools is based on an opportunity to remove the added complexity of proprietary programming frameworks to GPU application development. "If successful, these tools – or similar versions – could help to democratize GPU application development, removing the need for proprietary frameworks, which then makes the HPC accelerator market much more competitive for smaller players. For example, HPC users could potentially use these tools to convert CUDA code into C++ and then run it on an Intel Xeon co-processor."The post AMD Boltzmann Initiative Promotes HPC Freedom of Choice appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PS40)
In this video from The Digital Future conference in Berlin, Leslie Greengard from the Simons Center for Data Analysis presents: Modeling Physical Systems in Complex Geometry. Greengard is an American mathematician, physician and computer scientist. He is co-inventor of the fast multipole method, recognized as one of the top-ten algorithms of computing."The post Leslie Greengard Presents: Modeling Physical Systems in Complex Geometry appeared first on insideHPC.
|
 |
by staff on (#1PPGB)
Today International Computer Concepts (ICC) announced that it has upgraded the company's ICC Vega line of high-frequency trading servers with the latest Broadwell-E microarchitecture from Intel. After extensive testing, the Vega servers featuring overclocked Intel Core i7 processors are ready to ship to customers.The post ICC Updates Overclocked Vega Financial Servers with Broadwell-E appeared first on insideHPC.
|
 |
by staff on (#1PPEB)
This week at the Flash Memory Summit, One Stop Systems showcased the OCP Flash Storage Array (OCP-FSA), supporting up to 500TB of Flash storage in a 2U form factor. Designed to comply with the Open Rack Standards set by the Open Compute Project, the OCP-FSA is one of the first 500TB Flash Storage Arrays in 2U rack space.The post One Stop Systems Showcases Open Compute Flash Array with 500 TB in 2U appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PKWX)
"A quantum computer cannot just be created from just trapping ions, it is necessary to move the information (the ions) between different locations in a trap, for example between calculation and storage regions. Our group has developed a method which allows the means to confidently control the motion of individual ions and shuttle an ion to any position in a ion trap microchip. By developing traps that generate complex electrical fields, it is possible to push and pull the ions by varying the strength of these fields, making it possible to manipulate single ions around corners! Right now, we are in the process of developing full scale architectures that contain all the necessary features for a full scale quantum computer."The post Video: Quantum Computing – The World’s Most Incredible Machines appeared first on insideHPC.
|
 |
by staff on (#1PKMP)
The University of Illinois at Urbana-Champaign is leading three new centers of innovation funded through the National Science Foundation’s Industry/University Cooperative Research Centers (I/UCRC) program.The post NSF Centers for Innovation Focus on Machine Learning, Genomics and More appeared first on insideHPC.
|
 |
by staff on (#1PKF0)
"We have been working on developing a number of tools that enable users to quantify power and performance in both software and hardware, and then design a more efficient system. We can also utilize the tools to predict the performance of a piece of software on a system that may not be available or does not yet exist – the aim is to take the guesswork away from novel system design."The post Adept Project Explores HPC Energy Efficiency appeared first on insideHPC.
|
 |
by staff on (#1PKBC)
Today Seagate announced the Nytro XF1230 SATA SSD, an energy-efficient drive specifically designed to meet the performance and reliability requirements of today’s cloud data centers. "SSDs in enterprise data centers provide extremely fast data access in a small footprint, while consuming very little energy. No SSD in its class does this better than Seagate’s latest addition to the Nytro product line,†said Brett Pemble, Seagate’s general manager and vice president of SSD products. “This is a critical addition to our growing SSD portfolio and an answer to what our enterprise customers have been asking for: a highly reliable, very low-latency SATA SSD that’s also energy efficient. It also means more people get more value from more data for lower cost.â€The post Seagate Rolls Out Energy-Efficient SATA SSD For Enterprise Cloud appeared first on insideHPC.
|
 |
by staff on (#1PK89)
Scientists at Argonne have discovered a self-healing, diamond-like material that could revolutionize the design of future automotive engines. “This is a very unique discovery, and one that was a little unexpected,†said Ali Erdemir, the Argonne Distinguished Fellow who leads the team. “We have developed many types of diamond-like carbon coatings of our own, but we’ve never found one that generates itself by breaking down the molecules of the lubricating oil and can actually regenerate the tribofilm as it is worn away.â€The post Argonne Discovers Self-healing Diamond-like Carbon appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PGDX)
Today Bright Computing announced that the Electronics Research Institute (ERI) and Brightskies Technologies have chosen the full suite of Bright technology to manage its HPC, big data, and cloud infrastructure. "Using Bright Computing’s technologies, we were able to showcase how to provision a virtual HPC cluster or big data cluster over cloud as extensions to the existing cluster or on demand as per users’ requests," said Dr. Khaled Elamrawi, President of Brightskies Technologies. “This was very powerful and clearly addressed the challenges that ERI were facing.â€The post Bright Computing Powers Electronics Research Institute appeared first on insideHPC.
|
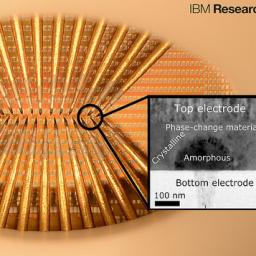 |
by Rich Brueckner on (#1PGAJ)
IBM scientists have created randomly spiking neurons using phase-change materials to store and process data. This demonstration marks a significant step forward in the development of energy-efficient, ultra-dense integrated neuromorphic technologies for applications in cognitive computing.The post IBM Phase-Change Device Imitates Functionality of Neurons appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PG40)
"At the Minnesota Supercomputing Institute we are exploring ways to provide the immediacy and flexibility of interactive computing within the batch-scheduled, tightly controlled world of traditional cluster supercomputing. As Jupyter Notebook has gained in popularity, the steps needed to use it within such an environment have proven to be a barrier to entry even as increasingly powerful Python tools have developed to take advantage of large computational resources. JupyterHub to the rescue! Except out of the box, it doesn't know anything about resource types, job submission, and so on. We developed BatchSpawner and friends as a general JupyterHub backend for batch-scheduled environments. In this talk I will walk through how we have deployed JupyterHub to provide a user-friendly gateway to interactive supercomputing."The post Video: JupyterHub as an Interactive Supercomputing Gateway appeared first on insideHPC.
|
 |
by MichaelS on (#1PFX3)
The ability to develop applications independent of the hardware availability at run time is a very important concept that enables developers to take advantage of the latest and greatest processing and coprocessing power. Without having to make run time checks on hardware availability is critical to a smooth running HPC environment.The post Using Libraries in Offload Mode appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PFX4)
Thomas Lippert presented this talk at The Digital Future conference. "The Human Brain Project brings together neuroscientists, physicians, computer scientists, physicists, mathematicians and computer specialists from internationally respected scientific institutions in 23 countries. Their goal is to simulate the complete human brain within the next ten years using a supercomputer of the future. The simulation will be accurate in every detail, and will take in aspects such as genetics, the molecular level and the interaction of whole cell clusters."The post Simulation and Data Sciences in the Exascale, Neuromorphic and Quantum Computing Era appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PCMZ)
Today Curtiss-Wright’s Defense Solutions division announced that it is collaborating with Dolphin Interconnect Solutions to bring Dolphin’s eXpressWare PCIe Software Suite to the embedded aerospace and defense market. Available separately or as part of Curtiss-Wright’s OpenHPEC Accelerator Suite of best-in-class software tools, this PCIe Fabric Communications suite speeds and simplifies the design of high-speed, low-latency PCIe fabric-based peer-to-peer communications in OpenVPX-based High Performance Embedded Computing (HPEC) systems for demanding Radar, SIGINT and EW applications.The post Curtiss-Wright & Dolphin Speed HPEC System Fabric appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PCEX)
Orange Silicon Valley and CocoLink Corp have built a functional prototype of what they're calling "the world's highest density Deep Learning Supercomputer in a box." Using the CoCoLink KLIMAX 210 server, they were able to load 20 overclocked GPUs in a single 4U rack unit.The post GPUs Power World’s Highest Density Deep Learning Supercomputer in a Box appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PCAJ)
Today Bright Computing released Version 7.3 of Bright Cluster Manager and Bright OpenStack. With enhanced support for containers, the new release has enhanced integration with Amazon Web Services (AWS), improvements to the interface with the Ceph distributed object store and file system, and a variety of other updates that make deployment and configuration easier and more intuitive.The post Bright Cluster Manager 7.3 Enhances Container Support appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PC9B)
The Barcelona Supercomputing Center and Colorado State University have launched a new website to track seasonal hurricane forecasts and the evolution of hurricane activity. The website shows the average number of hurricanes that are expected to affect the North Atlantic and those that have already occurred in the current season and the previous ones since 1966. A color code indicates the degree of activity forecast for the upcoming hurricane season.The post BSC Powers New Hurricane Threat Tracker appeared first on insideHPC.
|
 |
by MichaelS on (#1PC63)
Given the compute and data intensive nature of deep learning which has significant overlaps with the needs of the high performance computing market, theTOP500 list provides a good proxy of the current market dynamics and trends. From the central computation perspective, today’s multicore processor architectures dominate the TOP500 with 91% based on Intel processors. However, looking forwards we can expect to see further developments that may include core CPU architectures such as OpenPOWER and ARM.The post The Core Technologies for Deep Learning appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1PBG5)
"Improving diversity at conferences should be high up on the agenda for everyone. It is generally accepted that diversity in the workforce is a good thing: improving the representation of women in teams improves the overall performance of the teams, seeing women in positions that were traditionally male dominated helps to overcome the negative stereotypes that women are not suited to these roles as well as providing visible role models for future generations."The post Addressing Diversity at EuroMPI appeared first on insideHPC.
|
 |
by staff on (#1P9B3)
Today SC16 announced that Katharine Frase has been selected as the SC16 Keynote Speaker. "We are thrilled to have such an experienced pioneer and leader address pressing issues across so many industry fronts,†says John West, SC16 General Chair from the Texas Advanced Computing Center. “Her discussion will be thought-provoking to everyone in the room – from industry veterans to those new to the field.â€The post SC16 Keynote to Focus on Cognitive Computing appeared first on insideHPC.
|
 |
by staff on (#1P94S)
XSEDE reports that this year's International Summer School on HPC Challenges in Computational Sciences was a rousing success. "This program is an excellent mix of high performance computing knowledge and meeting international people involved in the field. There are a lot of training programs in the USA, but very few of them combine it with interaction of international colleagues and immersion in another culture.â€The post International HPC Summer School Prepares Next Generation appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1P8WK)
Steve Oberlin from Nvidia presented this talk at The Digital Future conference. "Oberlin will discuss machine learning and neural networks, explore a few advanced applications based on deep learning algorithms, discuss the foundation and architecture of representative algorithms, and illustrate the pivotal role GPU acceleration is playing in this exciting and rapidly expanding field."The post Steve Oberlin Presents: Accelerating Understanding – Machine Learning & Intelligent Applications appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1P8RG)
Today Penguin Computing announced that it is delivering an energy-efficient, HPC cluster to the University of Alaska Fairbanks. The new cluster, based on Penguin Computing’s Relion server family was first delivered in April 2016 and has been incrementally expanding throughout the year. The cluster was named Chinook in honor of deceased UAF employee Kevin Engle, who was known for his passion for salmon and Alaska. Engle was a research programmer and ground station manager at UAF’s Geographic Information Network of Alaska.The post Penguin Computing Powers Chinook Cluster at University of Alaska Fairbanks appeared first on insideHPC.
|
 |
by staff on (#1P8P0)
"We have partnered with Liqid to provide our customers with a leading option for enterprise-class flash storage. OSS is one of the only companies currently producing expansion products as dense as this FSA. By combining our PCIe expertise with Liqid's PCIe flash storage and software expertise, we have created a state-of-the-art flash array that can provide fast response time, high-availability, and high-speed data processing in data centers, cloud environments, mega websites, and high-performance applications."The post One Stop Systems Partners with Liqid on 3U Flash Storage Array appeared first on insideHPC.
|
 |
by staff on (#1P59D)
The National Computational Infrastructure (NCI), Australia's high-performance supercomputer, cloud and data repository, has received a $7M boost from the Australian Government, matched by the NCI Collaborating partners. "The NCI predicts that the $14M investment will provide a 30 per cent increase in NCI’s computational capability. In addition, it will allow the NCI to continue to provide a robust service for nationally significant research data across a range of disciplines, including the earth and environmental sciences, medical research, astronomy and materials science."The post NCI in Australia Receives $14 Million Investment appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1P547)
Cray's Steve Scott presented this talk at The Digital Future Conference. "Research and development at Cray is guided by our adaptive supercomputing vision. This vision is focused on delivering innovative, next-generation products that integrate diverse processing technologies into a unified architecture, enabling customers to surpass today’s limitations and meeting the market’s demand for realized performance."The post Cray’s Steve Scott Presents: Supercomputing Technologies and Trends: Where do we go from here? appeared first on insideHPC.
|
 |
by staff on (#1P52W)
Today Panasas introduced ActiveStor 20, its latest generation hybrid scale-out NAS appliance, featuring a 65 percent increase in flash and a 25 percent increase in hard drive capacity. High-density flash drives and 10 terabyte (TB) HGST Ultrastar He10 helium-based hard drives deliver superior unstructured sequential file and mixed-workload performance with rapid access to large and small files alike. Scalabiltity increases to more than 45 petabytes (PB) in a single namespace and performance ramps up to 360 gigabytes per second (GB/s) and 2.6M IOPS.The post Panasas Rolls Out ActiveStor 20 appeared first on insideHPC.
|
 |
by staff on (#1P4TP)
The inaugural Misha Mahowald Prize for Neuromorphic Engineering has been awarded to the TrueNorth project, led by Dr. Dharmendra S. Modha at IBM Research. "The Misha Mahowald Prize recognizes outstanding achievement in the field of neuromorphic engineering. Neuromorphic engineering is defined as the construction of artificial computing systems which implement key computational principles found in natural nervous systems. Understanding how to build such systems may enable a new generation of intelligent devices, able to interact in real-time in uncertain real-world conditions under severe power constraints, as biological brains do."The post IBM TrueNorth Project wins Inaugural Misha Mahowald Prize appeared first on insideHPC.
|