
 |
by staff on (#1RGEP)
Today Mellanox announced the opening of its new APAC headquarters and solutions centre in Singapore. The Company’s new APAC headquarters will feature a technology solution centre for showcasing the latest technologies from Mellanox, in addition to an executive briefing facility. The solution centre will feature the innovative solutions enabled by latest Mellanox technologies including HPC, Cloud, Big Data, and storage.The post Mellanox Opens New Singapore Headquarters to Strengthen HPC in Asia appeared first on insideHPC.
|
| Link | http://insidehpc.com/ |
| Feed | http://insidehpc.com/feed/ |
| Updated | 2026-06-20 08:45 |
 |
by Douglas Eadline on (#1RGBF)
When the history of HPC is viewed in terms of technological approaches, three epochs emerge. The most recent epoch, that of co-design systems, is new and somewhat unfamiliar to many HPC practitioners. Each epoch is defined by a fundamental shift in design, new technologies, and the economics of the day. "A network co-design model allows data algorithms to be executed more efficiently using smart interface cards and switches. As co-design approaches become more mainstream, design resources will begin to focus on specific issues and move away from optimizing general performance."The post The Evolution of HPC appeared first on insideHPC.
|
 |
by staff on (#1RDFR)
Intel and Hewlett Packard Enterprise (HPE) have recently created two new Centers of Excellence (CoE) to help customers gain hands-on experience with High Performance Computing (HPC). This plus collaboration with customers on implementing the latest technology solutions are highlights being celebrated by the two companies on the one-year anniversary of their alliance.The post Hewlett Packard Enterprise and Intel Alliance Delivers New Centers of Excellence for HPC appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1RD5B)
Today, the National Science Foundation (NSF) announced a $110 million award to the University of Illinois at Urbana-Champaign and 18 partner institutions to continue and expand activities undertaken through the Extreme Science and Engineering Discovery Environment (XSEDE).The post NSF Awards $110 Million for XSEDE 2.0 appeared first on insideHPC.
|
 |
by staff on (#1RD2H)
Today Avere Systems and Cycle Computing announced a technology integration that enables hybrid high-performance computing (HPC) in popular public cloud computing environments. By integrating the Avere vFXT Edge filer cloud bursting technology with Cycle Computing’s CycleCloud offering, users are now able to launch an Avere tiered file system on demand linked directly with the CycleCloud managed scalable compute nodes through cloud providers like AWS, Google Cloud Platform and Microsoft Azure.The post Avere Systems Teams with Cycle Computing for High Performance Multi-cloud Orchestration appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1RCXN)
The Fujitsu Journal has posted details on a recent Hot Chips presentation by Toshio Yoshida about the instruction set architecture (ISA) of the Post-K processor. "The Post-K processor employs the ARM ISA, developed by ARM Ltd., with enhancements for supercomputer use. Meanwhile, Fujitsu has been developing the microarchitecture of the processor. In Fujitsu's presentation, we also explained that our development of mainframe processors and UNIX server SPARC processors will continue into the future. The reason that Fujitsu is able to continuously develop multiple processors is our shared microarchitecture approach to processor development."The post Fujitsu Unveils Processor Details for Post-K Computer appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1RA1H)
Over at the ARM Community Blog, Nigel Stephens writes that the company has introduced scalable vector extensions (SVE) their A64 instruction set to bolster high performance computing. Fujitsu is developing a new HPC processor conforming to ARMv8-A with SVE for the Post-K computer.The post ARM Ramps up for HPC with SVE Scalable Vector Extensions appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1R9YD)
In this video from the 2016 Blue Waters Symposium, GPU Performance Nuggets – Carl Pearson and Simon Garcia De Gonzalo from the University of Illinois present: GPU Performance Nuggets. "In this talk, we introduce a pair of Nvidia performance tools available on Blue Waters. We discuss what the GPU memory hierarchy provides for your application. We then present a case study that explores if memory hierarchy optimization can go too far."The post Tutorial: GPU Performance Nuggets appeared first on insideHPC.
|
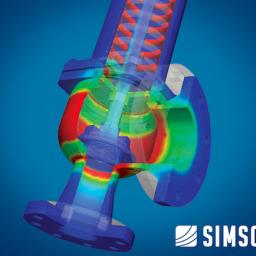 |
by staff on (#1R9TC)
Today SimScale in Germany announced a partnership with Autodesk, a leader in 3D design and fabrication software. The SimScale add-in for Autodesk Fusion 360 aims at improving the design engineering workflow between the design (CAD) and virtual testing phases (CAE). With the help of the add-in, users creating their 3D models in Autodesk Fusion 360 will be able to push their geometry directly to an existing CFD, FEA, or thermal analysis project on SimScale, where they can simulate it in the cloud.The post SimScale Integrates with Autodesk Fusion 360 appeared first on insideHPC.
|
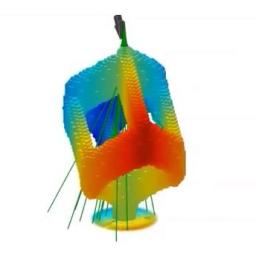 |
by Rich Brueckner on (#1R9KJ)
In this video, ORNL researchers use supercomputers to simulate nanomanufacturing, the process of building microscopic devices atom by atom. Simulated here is the construction of a 250-nanometer 3-D cube by focused electron beam induced deposition.The post Video: Combining Simulation & Experiment for Nanoscale 3-D Printing appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1R9DC)
For the first time, SC16 will offer childcare in the convention center to registered attendees and exhibitors. "This will provide an opportunity for the family to be together while one or both parents enjoy either parts or all of the conference. Of course, it is entirely optional, but we listened to our audience and this seemed to be a growing need. I realize this is a small step, but hopefully it is the first of many more small steps to come."The post SC16 Welcomes Families with On-Site Childcare appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1R6EH)
Today the OpenPOWER Foundation announced that their inaugural OpenPOWER Summit Europe will take place Oct. 26-28 in Barcelona, Spain. Held in conjunction with OpenStack Europe, the OpenPOWER Summit Europe, the event will feature speakers and demonstrations from the OpenPOWER ecosystem, including industry leaders and academia sharing their technical solutions and state of the art advancements.The post OpenPOWER Summit Europe Comes to Barcelona Oct. 26-28 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1R6CE)
Wen-mei Hwu from the University of Illinois at Urbana-Champaign presented this talk at the Blue Waters Symposium. "In the 21st Century, we are able to understand, design, and create what we can compute. Computational models are allowing us to see even farther, going back and forth in time, learn better, test hypothesis that cannot be verified any other way, and create safe artificial processes."The post Video: What is Driving Heterogeneity in HPC? appeared first on insideHPC.
|
 |
by staff on (#1R3ZB)
Six application development teams from NERSC gathered at Intel in early August for a marathon “dungeon session" designed to help tweak their codes for the next-generation Intel Xeon Phi Knight’s Landing manycore architecture and NERSC’s new Cori supercomputer. “We try to prepare ahead of time to bring the types of problems that can only be solved with the experts at Intel and Cray present—deep questions about the architecture and how applications use the Xeon Phi processor. It’s all geared toward optimizing the codes to run on the new manycore architecture and on Cori.â€The post NERSC Dungeon Session Speeds Code for Cori Supercomputer appeared first on insideHPC.
|
 |
by staff on (#1R3X3)
Today IBM announced the opening of the first OpenPOWER Research Facility (OPRF) at the Indian Institute of Technology Bombay. The OPRF will help drive the country's National Knowledge Network initiative to interconnect all institutions of higher learning and research with a high-speed data communication network, facilitating knowledge sharing and collaborative research and innovation. "Open collaboration is driving the next wave of innovation across the entire system stack, allowing clients and organizations to develop customized solutions to capitalize on today's emerging workloads,' said Monica Aggarwal, Vice President, India Systems Development Lab (ISDL), IBM Systems. "The OPRF will enable Indian companies, universities and government organizations to build technologies indigenously using the high-performance POWER processor, helping to drive the national IT agenda of India," she added.The post IIT in Bombay Opens the First OpenPOWER Research Facility appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1R1QJ)
In this podcast, the Radio Free HPC team reviews the recent 2016 Intel Developer Forum. “How will Intel return to growth in the face of a declining PC market? At IDF, they put the spotlight on IoT and Machine Learning. With new threats rising from the likes of AMD and Nvidia, will Chipzilla make the right moves? Tune in to find out.â€The post Radio Free HPC Looks at IDF 2016 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1R16A)
Over at the SC16 Blog, Elizabeth Leake writes that there will be a bit of a housing crunch in Salt Lake City this year during the world's largest supercomputing conference.The post SC16 Facing Housing Crunch in Salt Lake City appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1R13F)
This week Nvidia CEO Jen-Hsun Huang hand-delivered one of the company's new DGX-1 Machine Learning supercomputers to the OpenAI non-profit in San Francisco. “The DGX-1 is a huge advance,†OpenAI Research Scientist Ilya Sutskever said. “It will allow us to explore problems that were completely unexplored before, and it will allow us to achieve levels of performance that weren’t achievable.â€The post Nvidia Donates DGX-1 Machine Learning Supercomputer to OpenAI Non-profit appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1R0X5)
Norbert Eicker from the Jülich Supercomputing Centre presented this talk at the SAI Computing Conference in London. "The ultimate goal is to reduce the burden on the application developers. To this end DEEP/-ER provides a well-accustomed programming environment that saves application developers from some of the tedious and often costly code modernization work. Confining this work to code-annotation as proposed by DEEP/-ER is a major advancement."The post Taming Heterogeneity in HPC – The DEEP-ER take appeared first on insideHPC.
|
 |
by staff on (#1R0T7)
Altair's new Data Center GPU Management Tool is now available to Nvidia HPC Customers. With the wide adoption of Graphics Processing Units, customers are addressing vital work in fields including artificial intelligence, deep learning, self-driving cars, and virtual reality now have the ability to improve the speed and reliability of their computations through a new technology collaboration with Altair to integrate PBS Professional.The post Making Life Easier with Altair Data Center GPU Management Tool appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QY1G)
In this video from the 2016 Intel Developer Forum, Diane Bryant describes the company's efforts to advance Machine Learning and Artificial Intelligence. Along the way, she offers a sneak peak at the Knights Mill processor, the next generation of Intel Xeon Phi slated for release sometime in 2017. "Now you can scale your machine learning and deep learning applications quickly – and gain insights more efficiently – with your existing hardware infrastructure. Popular open frameworks newly optimized for Intel, together with our advanced math libraries, make Intel Architecture-based platforms a smart choice for these projects."The post Video: Intel Sneak Peek at Knights Mill Processor for Machine Learning appeared first on insideHPC.
|
 |
by staff on (#1QXMA)
A new iBook by Dr. Stephen Perrenod looks at 72 Beautiful Galaxies. With a Foreword written by our own Rich Brueckner from insideHPC, the iPad "book" offers an interactive way to explore the universe. "In 72 Beautiful Galaxies we take you on a trip from relatively near to very far away in the universe, with images of 72 galaxies - and beyond that you will also see hundreds of galaxies as they are found in clusters."The post New iBook brings us 72 Beautiful Galaxies appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QXCQ)
There is still time to register for the 2016 Hot Interconnects Conference, which takes place August 24-26 at Huawei in Santa Clara, California. The keynote speaker this year is Kiran Makhijan, Senior Research Scientist, Network Technology Labs at the Huawei America Research Center. Her talk is entitled: Cloudcasting - Perspectives on Virtual Routing for Cloud Centric Network Architectures.The post Hot Interconnects Conference Comes to Santa Clara Aug 24-26 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QX5W)
In this video, D-Wave Systems Founder Eric Ladizinsky presents: The Coming Quantum Computing Revolution. "Despite the incredible power of today’s supercomputers, there are many complex computing problems that can’t be addressed by conventional systems. Our need to better understand everything, from the universe to our own DNA, leads us to seek new approaches to answer the most difficult questions. While we are only at the beginning of this journey, quantum computing has the potential to help solve some of the most complex technical, commercial, scientific, and national defense problems that organizations face."The post Video: The Coming Quantum Computing Revolution appeared first on insideHPC.
|
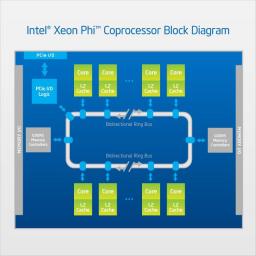 |
by MichaelS on (#1QX0F)
"The major functionality of the Intel Xeon Phi coprocessor is a chip that does the heavy computation. The current version utilizes up to 16 channels of GDDR5 memory. An interesting notes is that up to 32 memory devices can be used, by using both sides of the motherboard to hold the memory. This doubles the effective memory availability as compared to more conventional designs."The post Intel Xeon Phi Coprocessor Design appeared first on insideHPC.
|
 |
by Douglas Eadline on (#1QTMJ)
A single issue has always defined the history of HPC systems: performance. While offloading and co-design may seem like new approaches to computing, they actually have been used, to a lesser degree, in the past as a way to enhance performance. Current co-design methods are now going deeper into cluster components than was previously possible. These new capabilities extend from the local cluster nodes into the "computing network."The post Designing Machines Around Problems: The Co-Design Push to Exascale appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QSXX)
In this video from the 2016 Blue Waters Symposium, Andriy Kot from NCSA presents: Parallel I/O Best Practices.The post Video: Parallel I/O Best Practices appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QSVW)
In this TACC Podcast, Researchers describe how XSEDE supercomputing resources are helping them grow a better soybean through the SoyKB project based from the University of Missouri-Columbia. "The way resequencing is conducted is to chop the genome in many small pieces and see the many, many combinations of small pieces," said Xu. "The data are huge, millions of fragments mapped to a reference. That's actually a very time consuming process. Resequencing data analysis takes most of our computing time on XSEDE."The post Podcast: Supercomputing Better Soybeans appeared first on insideHPC.
|
 |
by MichaelS on (#1QSQD)
Deep learning solutions are typically a part of a broader high performance analytics function in for profit enterprises, with a requirement to deliver a fusion of business and data requirements. In addition to support large scale deployments, industrial solutions typically require portability, support for a range of development environments, and ease of use.The post Software Framework for Deep Learning appeared first on insideHPC.
|
 |
by staff on (#1QSMB)
NOAA and its partners have developed a new forecasting tool to simulate how water moves throughout the nation’s rivers and streams, paving the way for the biggest improvement in flood forecasting the country has ever seen. Launched today and run on NOAA’s powerful new Cray XC40 supercomputer, the National Water Model uses data from more than 8,000 U.S. Geological Survey gauges to simulate conditions for 2.7 million locations in the contiguous United States. The model generates hourly forecasts for the entire river network. Previously, NOAA was only able to forecast streamflow for 4,000 locations every few hours.The post Supercomputers Power NOAA Flood Forecasting Tool appeared first on insideHPC.
|
 |
by MichaelS on (#1QS9B)
This very interesting whitepaper explains how selecting a proper parallel file system for your application can increase the performance of complex simulations and reduce time to completion.The post Faster and More Accurate Exploration using Shared Storage with Parallel Access appeared first on insideHPC.
|
|
by Rich Brueckner on (#1QPGG)
Today SC16 announced that the conference will feature 38 high-quality workshops to complement the overall Technical Program events, expand the knowledge base of its subject area, and extend its impact by providing greater depth of focus.The post SC16 to Feature 38 HPC Workshops appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QP6X)
Today the U.S. Department of Energy announced that it will invest $16 million over the next four years to accelerate the design of new materials through use of supercomputers. “Our simulations will rely on current petascale and future exascale capabilities at DOE supercomputing centers. To validate the predictions about material behavior, we’ll conduct experiments and use the facilities of the Advanced Photon Source, Spallation Neutron Source and the Nanoscale Science Research Centers.â€The post DOE to Invest $16 Million in Supercomputing Materials appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QP43)
"Few fields are moving faster right now than deep learning," writes Buck. "Today’s neural networks are 6x deeper and more powerful than just a few years ago. There are new techniques in multi-GPU scaling that offer even faster training performance. In addition, our architecture and software have improved neural network training time by over 10x in a year by moving from Kepler to Maxwell to today’s latest Pascal-based systems, like the DGX-1 with eight Tesla P100 GPUs. So it’s understandable that newcomers to the field may not be aware of all the developments that have been taking place in both hardware and software."The post Nvidia Disputes Intel’s Maching Learning Performance Claims appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QNX9)
Today Cycle Computing announced its continued involvement in optimizing research spearheaded by NASA’s Center for Climate Simulation (NCCS) and the University of Minnesota. Currently, a biomass measurement effort is underway in a coast-to-coast band of Sub-Saharan Africa. An over 10 million square kilometer region of Africa’s trees, a swath of acreage bigger than the entirety […]The post NASA Optimizes Climate Impact Research with Cycle Computing appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QNVK)
"In order to address data intensive workloads in need of higher performance for storage, TYAN takes full advantage of Intel NVMe technology to highlight hybrid storage configurations. TYAN server solutions with NVMe support can not only boost storage performance over the PCIe interface but provide storage flexibility for customers through scale-out architecture†said Danny Hsu, Vice President of MiTAC Computing Technology Corporation's TYAN Business Unit.The post TYAN Showcases NVMe Servers and Storage Platforms at IDF 2016 appeared first on insideHPC.
|
 |
by staff on (#1QNGE)
With the release of high wattage processors liquid cooling is becoming a necessity for HPC data centers. Liquid cooling’s ability to provide the direct removal of heat from these high wattage components within the servers is well established. However, there are sometimes concerns from facilities management that need to be addressed prior to liquid cooling’s introduction to the data center.The post Making it Easy to Introduce Liquid Cooling to the Data Center appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QJQ8)
LANL reports that a moment of inspiration during a wiring diagram review has saved more than $2 million in material and labor costs for the Trinity supercomputer at Los Alamos National Laboratory.The post Trinity Supercomputer Wiring Reconfiguration Saves Millions appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QJNQ)
In this Intel Chip Chat Podcast, Nidhi Chappell, the Director of Machine Learning Strategy at Intel discusses the company's planned acquisition of Nervana Systems to further drive Intel’s capabilities in the artificial intelligence (AI) field. "We will apply Nervana’s software expertise to further optimize the Intel Math Kernel Library and its integration into industry standard frameworks. Nervana’s Engine and silicon expertise will advance Intel’s AI portfolio and enhance the deep learning performance and TCO of our Intel Xeon and Intel Xeon Phi processors.â€The post Podcast: Intel Steps Up to Machine Learning with Nervana Systems Acquisition appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QJGY)
Peter Ungaro presented this talk at the 2016 Blue Waters Symposium. "Built by Cray, Blue Waters is one of the most powerful supercomputers in the world, and is the fastest supercomputer on a university campus. Scientists and engineers across the country use the computing and data power of Blue Waters to tackle a wide range of challenging problems, from predicting the behavior of complex biological systems to simulating the evolution of the cosmos."The post Pete Ungaro Presents: Blue Waters & the Cray Roadmap appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QJBA)
"I am honored to have been asked to drive NCSA’s continuing mission as a world-class, integrative center for transdisciplinary convergent research, education, and innovation," said Gropp. "Embracing advanced computing and domain collaborations across the University of Illinois at Urbana-Champaign campus and ensuring scientific communities have access to advanced digital resources will be at the heart of these efforts."The post Bill Gropp Named Acting Director of NCSA appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QJ7F)
Researchers at the University of Oxford have achieved a quantum logic gate with record-breaking 99.9% precision, reaching the benchmark required theoretically to build a quantum computer. "An analogy from conventional computing hardware would be that we have finally worked out how to build a transistor with good enough performance to make logic circuits, but the technology for wiring thousands of those transistors together to build an electronic computer is still in its infancy."The post University of Oxford Develops Logic Gate for Quantum Computing appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QFJY)
"High performance computing has transformed how science and engineering research is conducted. Answering a question in 30 minutes that used to take 6 months can quickly change the way one asks questions. Large computing facilities provide access to some of the world’s largest computing, data, and network resources in the world. Indeed, the DOE complex has the highest concentration of supercomputing capability in the world. However, by nature of their existence, making use of the largest computers in the world can be a challenging and unique task. This talk will discuss how supercomputers are unique and explain how that impacts their use."The post Video: How the HPC Environment is Different from the Desktop (and Why) appeared first on insideHPC.
|
|
by Rich Brueckner on (#1QAX1)
In this podcast, the Radio Free HPC team looks HPE's pending acquisition of SGI. "Will the acquisition be good for SGI and HP customers? Our RFHPC team is in unprecedented agreement that indeed it will. The key, however, to HPE's success will be keeping the SGI people. Rich thinks this acquisition will potentially give HPE the engineering talent it needs to compete with Cray at the high end of the market."The post Radio Free HPC Looks at HPE’s Pending Acquisition of SGI appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1QD34)
Nikkei in Japan writes that the Post K supercomputer is facing 1-2 year delay for deployment as part of the Flagship2020 project. Originally targeted for completion in 2020, the ARM-based Post K supercomputer has a performance target of being 100 times faster than the original K computer within a power envelope that will only be 3-4 times that of its predecessor. Nikkei cites semiconductor development issues as the reason for the project delay.The post Post K Supercomputer Delayed in Japan appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1Q9S4)
"Between 2011 and 2016, eight projects, with a total budget of more than €50 Million, were selected for this first push in the direction of the next- generation supercomputer: CRESTA, DEEP and DEEP-ER, EPiGRAM, EXA2CT, Mont- Blanc (I + II) and Numexas. The challenges they addressed in their projects were manifold: innovative approaches to algorithm and application development, system software, energy efficiency, tools and hardware design took centre stage."The post New Report Looks at European Exascale Projects appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1Q9P5)
Ed Seidel from NCSA presented this talk at The Digital Future conference in Berlin. "The National Center for Supercomputing Applications (NCSA) is a hub of transdisciplinary research and digital scholarship where University of Illinois faculty, staff, and students, and collaborators from around the globe, unite to address research grand challenges for the benefit of science and society. NCSA is also an engine of economic impact for the state and the nation, helping companies address computing and data challenges and providing hands-on training for undergraduate and graduate students and post-docs."The post Video: The Impact of the Computing and Data Revolution on Science & Society appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1Q9MP)
Nvidia is expanding its popular GPU Technology Conference to eight cities worldwide. "We’re broadening the reach of GTC with a series of conferences in eight cities across four continents, bringing the latest industry trends to major technology centers around the globe. Beijing, Taipei, Amsterdam, Melbourne, Tokyo, Seoul, Washington, and Mumbai will all host GTCs. Each will showcase technology from NVIDIA and our partners across the fields of deep learning, autonomous driving and virtual reality. Several events in the series will also feature keynote presentations by NVIDIA CEO and co-founder Jen-Hsun Huang."The post Nvidia Expands GTC to Eight Global Events appeared first on insideHPC.
|
 |
by Rich Brueckner on (#1Q7EY)
Today SGI announced that it has signed a definitive agreement to be acquired by Hewlett Packard Enterprise (HPE) for $7.75 per share in cash, a transaction valued at approximately $275 million, net of cash and debt. "At HPE, we are focused on empowering data-driven organizations," said Antonio Neri, executive vice president and general manager, Enterprise Group, Hewlett Packard Enterprise. "SGI's innovative technologies and services, including its best-in-class big data analytics and high performance computing solutions, complement HPE's proven data center solutions designed to create business insight and accelerate time to value for customers."The post Hewlett Packard Enterprise to Acquire SGI appeared first on insideHPC.
|
 |
by staff on (#1Q6S5)
"Supermicro RSD is architected to dramatically improve CPU and storage utilization rates, agility and efficiency in the datacenter,†stated Charles Liang, President and CEO of Supermicro. “When combined with our leadership position in the newest technologies such as U.2 NVMe, and in upcoming fabric technologies like Red Rock Canyon and PCI-E switches, Supermicro RSD will provide datacenters with unparalleled competitive advantages, especially when implemented with the new Ruler form factor high capacity flash storage.â€The post Supermicro to Unveil RSD Rack Scale Design at IDF appeared first on insideHPC.
|