
 |
by Rich Brueckner on (#36DKP)
In this video, Dan Olds from OrionX presents insights from their Q2-Q3 2017 Survey on Artificial Intelligence/Machine Learning/Deep Learning - one of the industry's most comprehensive AI/ML/DL surveys to date with more than 144 data points. "Dan Olds talks the audience through the demographics and questions, respondents’ understanding of AI/ML/DL, current projects, who is driving AI in organizations, project attributes and more."The post Industry Analysis: AI and Deep Learning – the Voice of the Market appeared first on insideHPC.
|
| Link | http://insidehpc.com/ |
| Feed | http://insidehpc.com/feed/ |
| Updated | 2026-06-19 20:30 |
 |
by Rich Brueckner on (#36B59)
Gilad Shainer gave this talk at the HPC Advisory Council Spain Conference. "The latest revolution in HPC is the move to a co-design architecture, a collaborative effort among industry, academia, and manufacturers to reach Exascale performance. By taking a holistic system-level approach to fundamental performance improvements Co-design architectures exploit system efficiency and optimizes performance by creating synergies between the hardware and the software."The post Video: The Era of Data-Centric Data Centers appeared first on insideHPC.
|
 |
by Rich Brueckner on (#36B1K)
Purdue University seeks a HPC Systems Administrator to design, deploy, administer, and update large-scale research systems, related infrastructure services, grid software stacks, and operating systems. Additionally, as HPC Systems Administrator, you will be responsible for components of Purdue's computational research environment, and work closely with researchers, systems administrators, engineers and developers throughout the University and partner institutions. You will also administer existing cluster and grid infrastructure technologies, and research/prototype new systems and technologies.The post Job of the Week: HPC System Administrator at Purdue appeared first on insideHPC.
|
 |
by staff on (#368VR)
Today Intel announced the launch of the Intel Optane SSD 900P Series, the first SSD for desktop PC and workstation users built on Intel Optane technology. "Up to four times faster than competitive NAND-based SSDs, the Intel Optane SSD 900P Series delivers incredibly low latency and best-in-class random read and write performance. The Intel Optane SSD 900P Series is ideal for the most demanding storage workloads, including 3D rendering, complex simulations, fast game load times and more. The device also offers up to 22 times more endurance than other drives."The post Now Shipping: Intel Optane SSDs with 4x Performance of NAND-Based Devices appeared first on insideHPC.
|
 |
by staff on (#368RS)
The cost of moving HPC workloads to Iceland is coming down in a big way. Today Verne Global and Tele Greenland announced that the 12.4-Tbps upgrade to the Greenland Connect subsea cable system with three new 100-Gpbs connections into Verne Global’s Icelandic data center, is now complete. The upgraded network provides streamlined routing from Iceland to the New York City metro area, lower latency and up to 90% lower network costs. Tele Greenland has also invested in improving route security to ensure data integrity and protect cables from elemental factors.The post New Subsea Cable Lowers Network Costs from Iceland to North America by 90% appeared first on insideHPC.
|
 |
by staff on (#368NC)
Brian Ban continues his series of SC17 Session Previews with a look at an invited talk on nanotechnology. "This talk will focus on the challenges that computational chemistry faces in taking the equations that model the very small (molecules and the reactions they undergo) to efficient and scalable implementations on the very large computers of today and tomorrow."The post SC17 Session Preview: “Taking the Nanoscale to the Exascale†appeared first on insideHPC.
|
 |
by staff on (#368NE)
Today German officials signed a contract for the long-term financing of a new supercomputer for DKRZ. The new machine will be used for climate research. "We need to understand much better how climate changes influence our way of life and vice versa - locally and globally," said Katharina Fegebank, Senator for Science, Research and Equality. "This interplay is highly complex. Wise solutions are therefore dependent on sound scientific knowledge."The post Agreement Ensures Ongoing HPC Funding for Climate Research at DKRZ in Germany appeared first on insideHPC.
|
 |
by Rich Brueckner on (#368F0)
Andres Gómez Tato from CESGA gave this talk at the HPC Advisory Council Spain Conference. "With the explosion of Deep Learning thanks to the availability of large volume of data, computational resources are needed to train large models, using GPUs and distributed computing. When working on large models, HPC infrastructures can help to speed-up some task during the model design and training. Based on the experience at CESGA and FORTISIMO, this talk reviews the computational needs of Deep Learning, the use cases where HPC can help to Machine Learning, the performance of available Machine Learning APIs and the parallel methods commonly used during ML training."The post Video: HPC Meets Machine Learning appeared first on insideHPC.
|
 |
by Rich Brueckner on (#367WH)
In this podcast, the Radio Free HPC team asks the question: Is the Cloud Killing the Tape Market? The issue came up this week that Spectra Logic is laying off 9 percent of its workforce. “The technology has had its ups and downs over the years, and things look positive for it once again as cloud providers have adopted it as a cost-effective way to handle the growing amount of data being generated, TechTarget, a marketing firm, reported.â€The post Radio Free Looks at why the Tape Storage Market is falling on Hard Times appeared first on insideHPC.
|
 |
by staff on (#36586)
Today NCI in Australia announced that it has adopted IBM’s Power8 architecture as part of Raijin, the system fastest supercomputer in the Southern Hemisphere. The hybrid x86/Power8 system will offer local researchers the opportunity to explore the intersection of AI and HPC. "The extraordinary bandwidth in Power Systems provides a significant performance advantage, and we look forward to scientists exploiting those capabilities now and into the future."The post NCI Doubles Raijin Supercomputer Throughput with IBM POWER8 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#3652J)
Today the ARCTUR group in Slovenia announced the ARCTUR Be Innovative HPC Challenge. In this contest, 350,000 EUR worth of ARCTUR HPC resources will be granted to the proposal with the most interesting applications. "The goal of the competition is to encourage small and medium enterprises (among others) to scale up their computer simulations and modeling by using ARCTUR HPC infrastructure, writing an interesting use-case demonstrating the benefits of the use of HPC and becoming strategic parters of the company."The post Win Supercomputer Access in the ARCTUR Be Innovative HPC Challenge appeared first on insideHPC.
|
 |
by staff on (#364ZZ)
"In just a few steps, the NVIDIA GPU Cloud (NGC) container registry helps developers get started with no-cost access to a comprehensive, easy-to-use, fully optimized deep learning software stack. The cloud-based service is available immediately to users of the just-announced Amazon Elastic Compute Cloud (Amazon EC2) P3 instances featuring NVIDIA Tesla V100 GPUs. NVIDIA plans to expand support to other cloud platforms soon."The post NVIDIA GPU Cloud comes to AWS with Volta GPUs appeared first on insideHPC.
|
 |
by Richard Friedman on (#364Q3)
Intel Compilers 18.0 and Intel Parallel Studio XE 2018 tuning software fully support the AVX-512 instructions. By widening and deepening the vector registers, the new instructions and added enhancements let the compiler squeeze more vector parallelism out of applications than before. Applications compiled with the –xCORE-AVX512 will generate an executable that utilizes these new high-performance instructions.The post Intel Compilers 18.0 Tune for AVX-512 ISA Extensions appeared first on insideHPC.
|
 |
by staff on (#364T2)
Today Versity Software announced the addition of Meghan McClelland as Vice President of Product. “ Versity is the only independent provider of advanced, scalable, high throughput software defined archiving storage technology products. Meghan shares our vision for delivering hardware agnostic, open, scalable, customer friendly large storage solutions."The post Versity names Meghan McClelland VP of Product appeared first on insideHPC.
|
 |
by staff on (#361Y2)
Today Green Revolution Cooling announced the latest installation of its liquid immersion computing system at John Paul Catholic University (JPCU) in San Diego. The high density cluster made up of industry standard servers optimized for immersion, and built in partnership with Supermicro, exploit the enhanced performance and compelling economic value inherent with GRC liquid immersion technology. "Virtually limitless cooling, industry leading efficiency, and lower upfront cost, made it an absolute no brainer for us,†said Kevin Meziere, VP of Technology at JPCU “the ability to cool over 100kW [per rack] effectively and efficiently, gives us the ability to be more responsive to future technology trends and adopt more powerful hardware without concerns of cooling capacity and costs. Being a downtown campus every square inch counts, so the ability more densely pack equipment is a huge win.â€The post JPCU Deploys Immersion-cooled Supercomputer appeared first on insideHPC.
|
 |
by staff on (#361TA)
Today NEC Corporation launched their new high-end HPC product line, the SX-Aurora TSUBASA. "Utilizing cutting-edge chip integration technology, the new product features a complete multi-core vector processor in the form of a card-type Vector Engine (VE), which is developed based on NEC’s high-density interface technology and efficient cooling technology."The post Vectors are Back: The new NEC SX-Aurora TSUBASA Supercomputer appeared first on insideHPC.
|
 |
by staff on (#361Q2)
In this special guest feature from Scientific Computing World, Nox Moyake describes the process of entrenching and developing HPC in South Africa. "The CHPC currently has about 1,000 users; most are in academia and others in industry. The centre supports research from across a number of domains and participates in a number of grand international projects such at the CERN and the SKA projects."The post Firing up a Continent with HPC appeared first on insideHPC.
|
 |
by staff on (#361Q4)
Today Hewlett Packard Enterprise announced new purpose-built platforms and services capabilities to help companies simplify the adoption of Artificial Intelligence, with an initial focus on a key subset of AI known as deep learning. “HPE’s infrastructure and software solutions are designed for ease-of-use and promise to play an important role in driving AI adoption into enterprises and other organizations in the next few years.â€The post HPE Unveils a Set Artificial Intelligence Platforms and Services appeared first on insideHPC.
|
 |
by Rich Brueckner on (#361GY)
In this video. the House Subcommittee on Research & Technology and Subcommittee on Energy holds a hearing on American Leadership in Quantum Technology. "Quantum technology can completely transform many areas of science and a wide array of technologies, including sensors, lasers, materials science, GPS, and much more. Quantum computers have the potential to solve complex problems that are beyond the scope of today’s most powerful supercomputers. Quantum-enabled data analytics can revolutionize the development of new medicines and materials and assure security for sensitive information."The post Video: House Hearing on American Leadership in Quantum Technology appeared first on insideHPC.
|
 |
by staff on (#35YS1)
Spectra Logic announced today that Spectra Certified LTO-8 Type M media along with LTO-8 drives and all supported media are now available for order. An industry first offering, LTO-8 Type M media provides a 50 percent increase in capacity from 6TB to 9TB using new LTO-7 media.The post LTO-8 Type M Tape Boosts Storage Capacity from Spectra Logic appeared first on insideHPC.
|
 |
by staff on (#35YN1)
“I think for the first time we have shown a proof of concept for embedded cooling for Department of Defense and potential commercial applications,†Garimella said. “This transformative approach has great promise for use in radar electronics, as well as in high-performance supercomputers. In this paper, we have demonstrated the technology and the unprecedented performance it provides.â€The post Purdue Develops Intrachip Micro-cooling for HPC appeared first on insideHPC.
|
 |
by staff on (#35YDV)
Over at Argonne, Charlie Catlett describes how the advent of Exascale computing will enable Smart Cities designed to improve the quality of life for urban dwellers. Catlett will moderate a panel discussion on Smart Cities at the SC17 Plenary session, which kicks off the conference on Monday, Nov. 13 in Denver.The post Exascale to Enable Smart Cities appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35Y7Y)
In this podcast, Dan Olds from OrionX describes Project Cyclops - a benchmarking quest to build the world's fastest single node. "We’ve done more than 150 podcasts talking about topics in high performance computing,†said Dan Olds, partner at OrionX.net Research. “It was time we actually put something together and take a run at some of these benchmarks.â€The post Radio Free HPC Announces Project Cyclops for World’s Fastest Node appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35XQ5)
The Beowulf Bash is returning to Denver for SC17. The event takes place at the Lucky Strike bowling alley on Monday, Nov. 13 from 9pm to 12 midnight. "Got an urge to try something new? Lucky Strike Denver has you covered. With a tantalizing menu of chef driven cuisine, hand-crafted cocktails, and live local DJs, Lucky Strike Denver breathes new life into the typical bowling experience with chic modern decor and a one-of-a-kind atmosphere."The post Beowulf Bash Returns to Denver for SC17 appeared first on insideHPC.
|
 |
by staff on (#35VCZ)
In this video, Nicolas Loubet from IBM Research describes how IBM's new 5 nanometer transistors will provide huge power savings that could enable mobile devices to run for days without a charge. "The resulting increase in performance will help accelerate cognitive computing, the Internet of Things (IoT) and other data-intensive applications delivered in the cloud."The post Video: What IBM’s 5 Nanometer Transistors Mean for You appeared first on insideHPC.
|
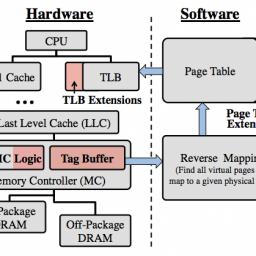 |
by staff on (#35VA4)
Researchers from MIT, Intel, and ETH Zurich have developed a new cache-management scheme that improves the data rate of in-package DRAM caches by 33 to 50 percent. "The bandwidth in this in-package DRAM can be five times higher than off-package DRAM,†says Xiangyao Yu, a postdoc in MIT’s Computer Science and Artificial Intelligence Laboratory and first author on the new paper. “But it turns out that previous schemes spend too much traffic accessing metadata or moving data between in- and off-package DRAM, not really accessing data, and they waste a lot of bandwidth. The performance is not the best you can get from this new technology.â€The post Banshee Makes DRAM Cache up to 50 percent more efficient appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35V4C)
Today Fujitsu announced the deployment of a immersion-cooled cluster at the Japan Automobile Research Institute (JARI). The new system will be used simulate automobile collisions. "Going forward, Fujitsu has plans to offer the liquid immersion cooling system worldwide as a product for cooling IT devices in non-conductive fluid."The post Fujitsu Deploys immersion-cooled x86 Cluster for JARI in Japan appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35TYY)
Today Cray announced a partnership with Microsoft to offer dedicated Cray supercomputing systems in Microsoft Azure. Under the partnership agreement, Microsoft and Cray will jointly engage with customers to offer dedicated Cray supercomputing systems in Microsoft Azure datacenters to enable customers to run AI, advanced analytics, and modeling and simulation workloads at unprecedented scale, seamlessly connected to the Azure cloud.The post Cray Supercomputing Comes to Microsoft Azure appeared first on insideHPC.
|
 |
by staff on (#35TYC)
Powerful technologies today fuel tomorrow’s HPC and High-Performance Data Analytics innovations and help organizations accelerate toward discoveries. Get ahead of the curve at the Intel HPC Developer Conference 2017 in Denver, Colorado on November 11-12.The post Register Now For the Intel HPC Developer Conference 2017 appeared first on insideHPC.
|
 |
by Richard Friedman on (#35TYD)
The HPC system software stack tends to be complicated, assembled out of a diverse mix of somewhat compatible open source and commercial components. This is the second article in a four-part series that explores using Intel HPC Orchestrator to solve HPC software stack management challenges. Download the full insideHPC Special Report.The post Challenges to Managing an HPC Software Stack appeared first on insideHPC.
|
|
by staff on (#35TMJ)
Today the Radio Free HPC podcast team announced announced plans to build what they hope will be the “fastest single-node supercomputer in the world" for the High Performance Conjugate Gradients Benchmark (HPCG). "Codenamed “Project Cyclopsâ€, the single-node supercomputer demonstrates the computational power that individual scientists, engineers, artificial intelligence practitioners, and data scientists can deploy in their offices."The post Single Node “Cyclops†Supercomputer Looks to Set Records appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35RMV)
Pavel Shamis from ARM gave this talk at the MVAPICH User Group. "With the emerging availability HPC solutions based on ARM CPU architecture, it is important to understand how ARM integrates with the RDMA hardware and HPC network software stack. In this talk, we will overview ARM architecture and system software stack. We will discuss how ARM CPU interacts with network devices and accelerators. In addition, we will share our experience in enabling RDMA software stack and one-sided communication libraries (Open UCX, OpenSHMEM/SHMEM) on ARM and share preliminary evaluation results."The post HPC Network Stack on ARM appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35RG4)
The StartupHPC Community will host their annual meetup at SC17 in Denver next month. StartupHPC is a grass roots community for STEM- and HPC-inspired entrepreneurs, corporations, venture capital firms, academia, government agencies, and support organizations. "If you can provide informal help or formal services to the startup community, let us know and we will include you in a leaflet given out at the meetup. If you are interested in entrepreneurship or are trying to grow a startup, stop by and see who can help you accelerate your progress."The post StartupHPC Meetup Coming to Denver at SC17 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35PFH)
Cleve Moler from MathWorks gave this talk at the 2017 Argonne Training Program on Extreme-Scale Computing. "MATLAB is a high-performance language for technical computing. It integrates computation, visualization, and programming in an easy-to-use environment where problems and solutions are expressed in familiar mathematical notation. Typical uses include: Data analysis, exploration, and visualization."The post Video: Evolution of MATLAB appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35PBN)
D.E. Shaw Research in New York is seeking HPC System Administrators in our Job of the Week. "Our research effort is aimed at achieving major scientific advances in the field of biochemistry and fundamentally transforming the process of drug discovery. Exceptional sysadmins sought to manage systems, storage, and network infrastructure for a New York–based interdisciplinary research group. Positions are available at our New York City offices, and at our data centers in Durham, NC and Endicott, NY."The post Job of the Week: HPC System Administrators at D.E. Shaw Research in New York appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35M19)
SC17 has announced the finalists for the Gordon Bell Prize in High Performance Computing. The $10,000 prize will be presented to the winner at the conference in Denver next month. "The Gordon Bell Prize recognizes the extraordinary progress made each year in the innovative application of parallel computing to challenges in science, engineering, and large-scale data analytics. Prizes may be awarded for peak performance or special achievements in scalability and time-to-solution on important science and engineering problems."The post Gordon Bell Prize Finalists to Present their work at SC17 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35KPY)
There is still time to participate in our insideHPC Survey on the intersection HPC & AI. In return, we'll send you a free report with the results and enter your name in a drawing to win one of two Echo Show devices with Alexa technology. "The Smart Home is here today. With the Echo Show, you can use your own voice to control a wide array of smart connected devices."The post There is still time to participate in our HPC & AI Survey appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35KV7)
In this video, Jim Mellon from Sygenta describes how the company's partnership with NCSA is helping the company answer the agricultural challenges of the future. "Together, we’re solving some of the toughest issues in agriculture today, like how to feed our rapidly growing population knowing that the amount of land we have for growing crops is finite. NCSA Industry provides the HPC resources that Syngenta’s scientists need to solve these issues, as well as an industry focus on security, performance, and availability, with the consultancy to better understand how to maximize these resources."The post HPC in Agriculture: NCSA and Syngenta’s Dynamic Partnership appeared first on insideHPC.
|
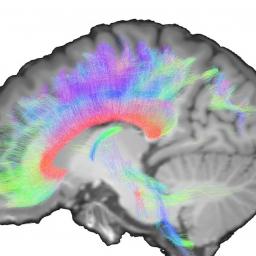 |
by staff on (#35KKP)
Scientists at the University of Basel are using the Piz Daint supercomputer at CSCS to discover interrelationships in the human genome that might simplify the search for “memory molecules†and eventually lead to more effective medical treatment for people with diseases that are accompanied by memory disturbance. "Until now, searching for genes related to memory capacity has been comparable to seeking out the proverbial needle in a haystack.â€The post Searching for Human Brain Memory Molecules with the Piz Daint Supercomputer appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35KG8)
Keren Bergman from Columbia University gave this talk at the 2017 Argonne Training Program on Extreme-Scale Computing. "Exaflop machines would represent a thousand-fold improvement over the current standard, the petaflop machines that first came on line in 2008. But while exaflop computers already appear on funders' technology roadmaps, making the exaflop leap on the short timescales of those roadmaps constitutes a formidable challenge."The post Video: Silicon Photonics for Extreme Computing appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35JZ4)
The Supercomputing Frontiers Europe 2018 conference has issued its Call for Papers. The conference takes place March 12 – 15, 2018 in Warsaw, Poland. "Supercomputing Frontiers is an annual international conference that provides a platform for thought leaders from both academia and industry to interact and discuss visionary ideas, important visionary trends and substantial innovations in supercomputing. Organized by ICM UW, Supercomputing Frontiers Europe 2018 will explore visionary trends and innovations in high performance computing."The post Call for Papers: Supercomputing Frontiers Europe 2018 appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35GG3)
In this video from the HPC User Forum in Milwaukee, Brian Kucic from R-Systems describes how the company enables companies of all sizes to move their technical computing workloads to the Cloud. "R Systems provides High Performance Computer Cluster resources and technical expertise to commercial and institutional research clients through the R Systems brand and the Dell HPC Cloud Services Partnership. In addition to our industry standard solutions, R Systems Engineers assist clients in selecting the components of their optimal cluster configuration."The post Video: How R-Systems Helps Customers Move HPC to the Cloud appeared first on insideHPC.
|
 |
by staff on (#35GCM)
This week’s landmark discovery of gravitational and light waves generated by the collision of two neutron stars eons ago was made possible by a signal verification and analysis performed by Comet, an advanced supercomputer based at SDSC in San Diego. "LIGO researchers have so far consumed more than 2 million hours of computational time on Comet through OSG – including about 630,000 hours each to help verify LIGO’s findings in 2015 and the current neutron star collision – using Comet’s Virtual Clusters for rapid, user-friendly analysis of extreme volumes of data, according to Würthwein."The post Comet Supercomputer Assists in Latest LIGO Discovery appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35G5P)
In this video from the SC17 HPC Connects series, Dimitris Menemenlis from NASA JPL/Caltech describes how supercomputing enables scientists to accurately map global ocean currents. The ocean is vast and there are still a lot of unknowns. We still can’t represent all the conditions and are pushing the boundaries of current supercomputer power,†said Menemenlis. “This is an exciting time to be an oceanographer who can use satellite observations and numerical simulations to push our understanding of ocean circulation forward.â€The post HPC Connects: Mapping Global Ocean Currents appeared first on insideHPC.
|
 |
by MichaelS on (#35G2E)
"Intel has been at the forefront of working with software partners to develop solutions for visualization of data that will scale in the future as many core systems such as the Intel Xeon Phi processor scale. The Intel Xeon Phi processor is extremely capable of producing visualizations that allow scientists and engineers to interactively view massive amounts of data."The post Visualization in Software using Intel Xeon Phi processors appeared first on insideHPC.
|
 |
by staff on (#35D7S)
Today the Barcelona Supercomputing Centre announced plans to allocate 475 million core hours of its supercomputer MareNostrum to 17 research projects as part of the PRACE initiative. Of all the nations participating in PRACE's recent Call for Proposals, Spain is now the leading contributor of compute hours to European research.The post MareNostrum Supercomputer to contribute 475 million core hours to European Research appeared first on insideHPC.
|
 |
by Rich Brueckner on (#35D3Q)
Phil Carns from Argonne gave this talk at the 2017 Argonne Training Program on Extreme-Scale Computing. "Darshan is a scalable HPC I/O characterization tool. It captures an accurate but concise picture of application I/O behavior with minimum overhead. Darshan was originally developed on the IBM Blue Gene series of computers deployed at the Argonne Leadership Computing Facility, but it is portable across a wide variety of platforms include the Cray XE6, Cray XC30, and Linux clusters. Darshan routinely instruments jobs using up to 786,432 compute cores on the Mira system at ALCF."The post HPC I/O for Computational Scientists appeared first on insideHPC.
|
 |
by staff on (#35CTE)
A cumulative effort over several years to scale the training of deep-learning neural networks has resulted in the first demonstration of petascale deep-learning training performance, and further to deliver this performance when solving real science problems. The result reflects the combined efforts of NERSC (National Energy Research Scientific Computing Center), Stanford and Intel to solve real world use cases rather than simply report on performance benchmarks.The post 1000x Faster Deep-Learning at Petascale Using Intel Xeon Phi Processors appeared first on insideHPC.
|
 |
by staff on (#35CX9)
In this special guest feature, Jeremy Thomas from Lawrence Livermore National Lab writes that exascale computing will be a vital boost to the U.S. manufacturing industry. “This is much bigger than any one company or any one industry. If you consider any industry, exascale is truly going to have a sizeable impact, and if a country like ours is going to be a leader in industrial design, engineering and manufacturing, we need exascale to keep the innovation edge.â€The post How Manufacturing will Leap Forward with Exascale Computing appeared first on insideHPC.
|
 |
by staff on (#35B1Z)
Intel's Naveen Rao writes that Intel will soon be shipping the world’s first family of processors designed from the ground up for artificial intelligence. As announced today, the new chip will be the company's first step towards it goal of achieving 100 times greater AI performance by 2020. "The goal of this new architecture is to provide the needed flexibility to support all deep learning primitives while making core hardware components as efficient as possible."The post Podcast: Intel to Ship Neural Network Processor by end of year appeared first on insideHPC.
|